









前段时间慢悠悠的在看 程序员的自我修改-链接.装载.库 ,写的蛮好的,推荐大家有空闲的话都去看看~ 断断续续看完了前两章,还是记录一下~好记性不如烂笔头
撰写不易,转载需注明出处:http://blog.csdn.net/jscese/article/details/50036605本文来自 【jscese】的博客!
做了什么
我们习惯性的在linux下编译某个C程序 直接敲个命令:
gcc hello.c -o hello然后就可以./hello 运行这个EIF文件了,异常简单
那是因为gcc 把所有的都自己默默的做完了,整个的过程分四步走:
预处理-prepressing
编译-compilation
汇编-assembly
链接-linking
预处理
预处理只是做正式编译前的一些准备工作,根据规则处理将要被编译的源文件。
以hello.c 为例,内容如下:
#include <stdio.h>
#define TEST 5
#pragma message("jscese pragma")
void main(int argc ,char argv[])
{
//jscese test
printf("hello,world\n");
int itest=TEST;
#ifdef DEF
printf("if def \n");
#endif
printf("itest=%d\n",itest);
}预处理命令如下 -E 选项:
gcc -E hello.c -o hello.igcc 预处理的规则如下:
1: 删除 #define , 所有使用宏的地方全部展开
2: #include的目标文件会插入指令的位置,递归进行
3: #if #else #ifdef #elseif #endif 解析判断是否有效
4: 删除所有// /**/
5: 添加行号 以及文件名标识 2 “hello.c” 2 用于编译警告报错提示
6: 保留#pragma 这个预编译指令,留给编译器
以上者六条规则比较好理解,同时可查看 hello.i 中的内容如下:
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "hello.c"
...
# 940 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
# 5 "hello.c"
#pragma message("jscese pragma")
# 5 "hello.c"
void main(int argc char argv[])
{
printf("hello,world\n");
int itest=5;
printf("itest=%d\n",itest);
}可以看到 预处理之后的 #define 不见了,用了TEST宏的地方展开了,// 注释的地方不见了, #ifdef 的部分也因为不成立删除了。
有时候可以通过查看预处理文件 来确定引入 以及 宏定义是否正确
编译
编译部分算是四个流程里面最为繁琐的一部分,也是最核心的部分,完成 高级语言到低级语言的转变(如汇编)
命令如下 -S 选项,不是 -s,这里使用小写就直接编译生成EIF了,而且是strip symbol信息的,gdb打开是不能调试的:
gcc -S hello.c -o hello.s这个-S ,gcc内部会调用对应的执行程序,c语言的话 就是调用 /usr/lib/gcc/x86_64-linux-gnu/4.6/cc1 来处理
/usr/lib/gcc/x86_64-linux-gnu/4.6/cc1 hello.c结果一样 都会生成一个 hello.s 的汇编文件,并且会执行 预处理时留下的 #pragma ,这里的#pragma是打印下信息,可用于编译时的调试:
jscese:~/jscese_code/compile_test/2_compile$ gcc -s hello.c -o hello.s
hello.c:5:10: note: #pragma message: jscese pragma在这里可以想到 直接就从 c语言跨度到 汇编了, cc1 把前面的预处理也做了,是把预处理和编译一起做了
其中编译部分由可以细分如下几0:
1:scanner —— lex
2:parser —— yacc ->语法树
3:semantic analyzer -> 带语义的语法树
4:source code optimizer -> 一些可以在编译阶段前进行的优化
5:code generator -> 依赖目标机器
6:code optimizer ->指令优化
可能直接看上面6条 会没什么概念,还是记录一下书中的例子,简单的一句代码:

scanner
扫描字符 记录token:

parser
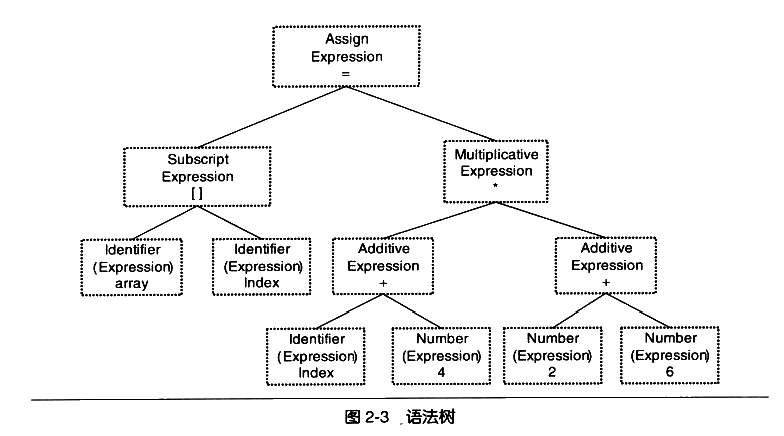
作为赋值表达式,一些优先级解析,判断合法
semantic analyzer
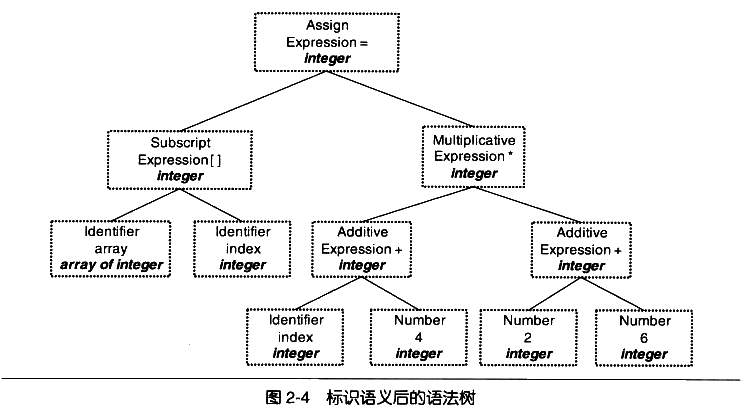
表达式带符号,转换之间是否合法
source code optimizer
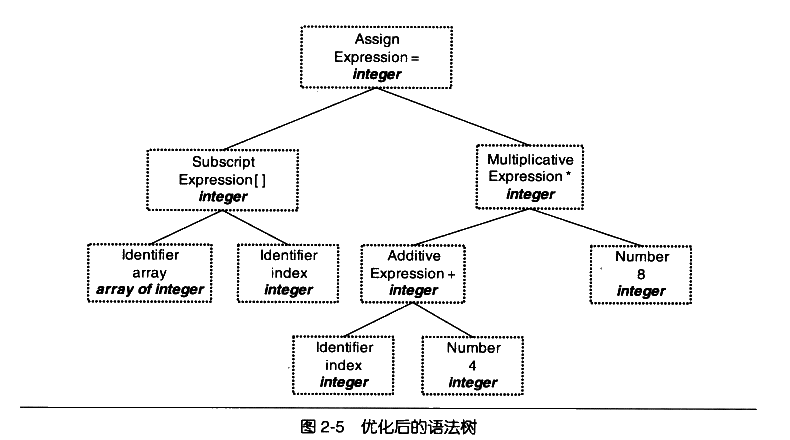
同理 三地址码优化例子:
x=y op z
优化之后如下:
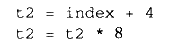
细节就不多记录了,可以去看书
code generator
根据上面的语义语法树,代码生成器翻译之后的 汇编如下:

code optimizer
经过指令优化成:

这就是最终得到的 汇编代码
关于编译牵扯的东西太多,书中描写的稍微多点,这里只是有个大概的印象记录
汇编
汇编步骤相对比较简单,将上面得到的 汇编代码 转换翻译成机器指令 , 由一个汇编器 as 完成,gcc命令形式如下:
gcc -c hello.s -o hello.o
//as hello.s -o hello.o得到的是目标文件 .o
链接
链接部分也比较复杂,个人的理解,就是将 目标文件.o 相关的都链接起来,
比如上面看到的最后的汇编代码,array数组的地址,index值存放在哪里,值是多少都是未知的,如果在同文件定义的还好
要是在另外的源文件,此时编译的目标文件里面 这些未知的地址 搁置放那里 ,等着链接的时候来设置的
主要工作包括:
1:地址和空间分配
2:符号决议
3:重定位
具体就不记录了,描写性的居多,书中有,比较好理解
在有互相作用影响的情况下,只有在链接的环节 才能进行一系列最后的分配地址 大小等,决议和重定位一些地址或值
后续有机会再去学习学习~















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









