







 本文详细比较了一致性哈希与普通哈希取模在Redis集群中的应用,强调了一致性哈希在解决数据分片、节点扩展和数据倾斜问题上的优势,以及哈希槽在Redis集群管理中的特点。
本文详细比较了一致性哈希与普通哈希取模在Redis集群中的应用,强调了一致性哈希在解决数据分片、节点扩展和数据倾斜问题上的优势,以及哈希槽在Redis集群管理中的特点。
目录
普通哈希取模
原理
普通哈希函数最大的作用就是散列,也就是将一系列在形式上具有相似性质的数据,打散成随机均匀分布的数据。
例如Redis集群的节点数为N个,使用哈希取模算法进行数据分片,本质上就是一个节点一个数据分片,每次请求使用 hash(key)%N 的方式计算对应的节点。
存在的问题
普通哈希取模分片对扩容极不友好,当集群的数量N发生变化时,之前的大量Hash映射就会失效,大量的key都需要随之进行节点迁移。
总结
普通哈希取模分片算法简单,只需要先对数据进行哈希,然后取模即可。但当数据节点伸缩时,会导致大量数据迁移。在一定要采用哈希取模分片的情况下,由于迁移数量和添加节点的数量有关,建议翻倍扩容。
一致性哈希
原理
一致性哈希是指将存储节点和数据都映射到一个首尾相连的哈希slot环上,所谓的哈希slot环其实就是将所有的slot虚拟化成一个圆环,每个slot都对应环上的每个刻度。存储节点一般可以根据节点IP的哈希值来确定,每个节点负责存储环上的一个分段,数据可以从映射在环上的位置开始,按照顺时针方向所找到的第一个存储节点。
一致性哈希算法主要应用于分布式存储系统中,可以有效解决分布式存储结构下普通哈希取模算法伸缩性差的问题,并保证在动态增加和删除节点的情况下尽量有多的请求命中原来的机器节点。
如果redis使用一致性哈希来进行分片路由,那么就需要先完成key到 2^32 个slot之间的映射,再到哈希slot环上按照顺时针方向完成slot到节点的映射。
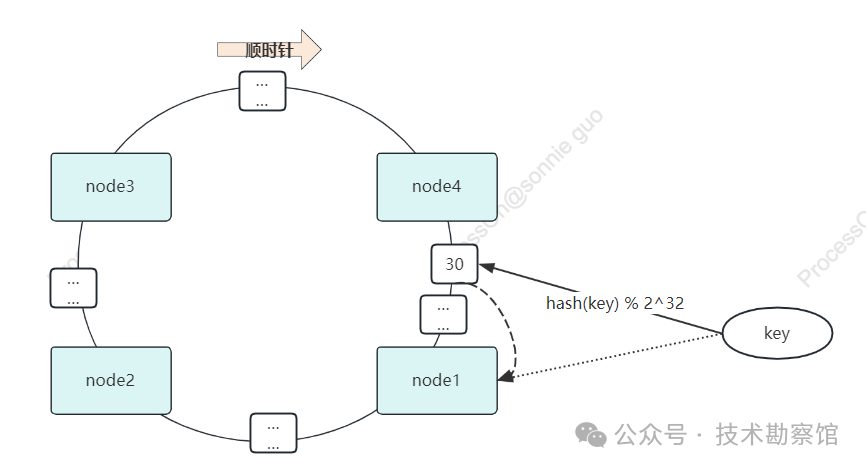
一致性哈希如何解决经典哈希取模算法伸缩性差的问题?
举个例子,假如我们在哈希环slot环上按顺时针方向依次有node1、node2、node3、node4四个redis节点,当需要在node1和node2之间添加node5时,由于顺时针寻址的原因,此时只会影响到node2上的数据,其他3个节点都不会受到影响。
同样的道理,当要删除node1时,会受影响的也只有顺时针方向下node1的下一个节点——node2,此时node1上的数据需要迁移至node2。
因此,在分布式集群伸缩场景下,相比哈希取模而言,节点数越多,迁移规模越小。
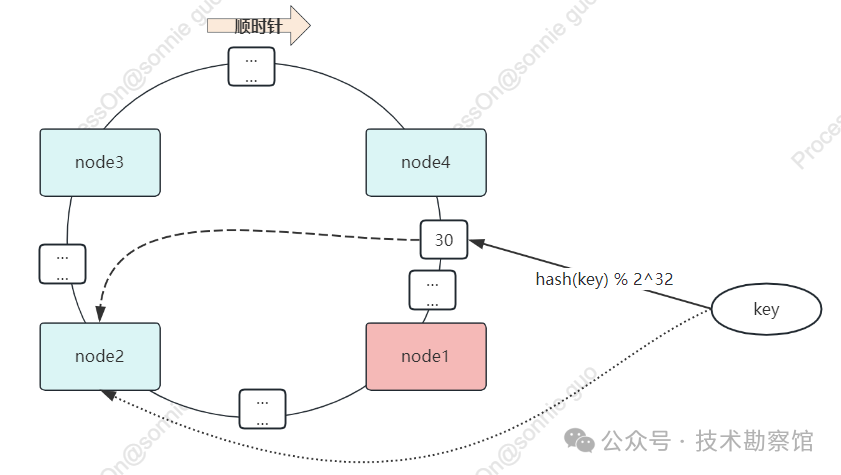
数据倾斜问题
在我们上述的一致性哈希算法中,存在一个很大的问题——数据倾斜。
我们还是通过案例来说明:假如在哈希环slot环上按顺时针方向还是依次有node1、node2、node3、node4四个redis节点,如果node2、node3同时宕机,此时这两个节点上的数据就都是迁移到node4,从而产生数据倾斜问题。
虚拟节点
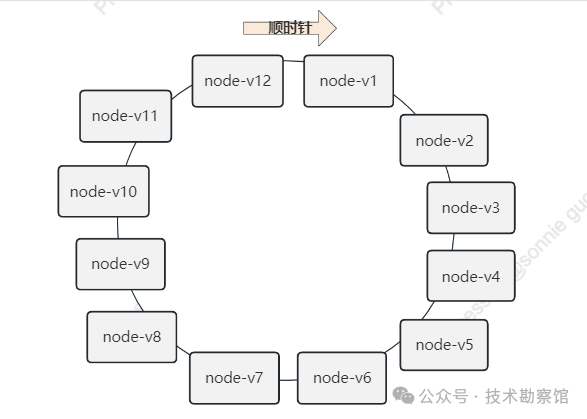
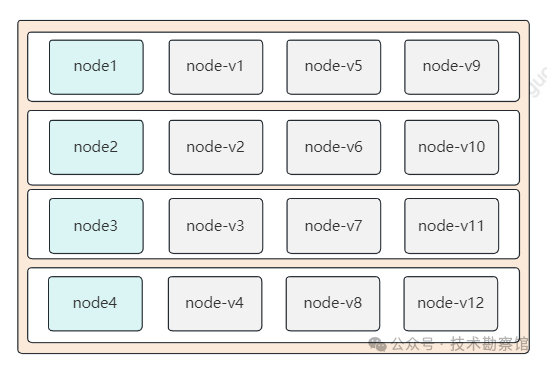
为了解决数据倾斜问题,一致性哈希算法引入了虚拟节点机制。虚拟节点顾名思义,它只是逻辑节点,部署实际的物理节点。每个虚拟节点都会被映射到对应的物理节点上,最终每个物理节点在哈希环上会有多个虚拟节点存在,数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。
例如当数据被定位到 node-v1、node-v-2、node-v-3 三个虚拟节点时,最终都会再被映射到node1节点上。假设物理节点node3被移除,那么把node3负责的逻辑节点二次分配到其他三个物理节点就行了。
引入虚拟节点机制,大大削弱甚至避免了数据倾斜问题。在实际应用中,通常将虚拟节点数设置为 32 甚至更大。
哈希槽
既然一致性哈希既能解决集群伸缩时的大规模节点数据迁移问题,也能避免节点数据迁移后的数据倾斜问题,那为什么Redis选用哈希槽而不是一致性哈希呢?
原理
redis集群架构采用去中心化的方式,每个节点都维护了一份元数据信息,其核心就是slot和节点间的映射关系。redis在做数据分片时,本质上也是先通过哈希运算再取模分片,其中,redis 集群的 hash算法,采用的是 crc16 哈希算法,并使用固定长度的模 16384,这16384个哈希分片也称之为 哈希槽,这些哈希槽会被尽可能均匀的分配给各个节点。
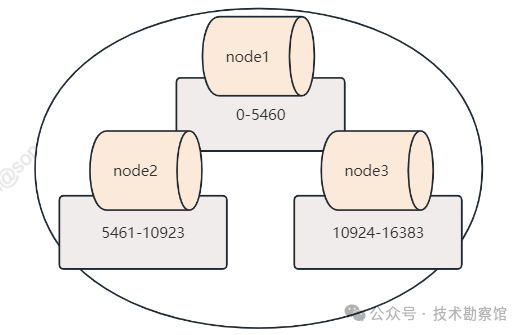
当新增一个节点 node4 时,redis 集群的做法是从各个节点的前面分别拿取一部分 slot 到 node4 上,从而实现4个节点的数据均匀。当然我们也可以根据不同节点所在机器的实际性能,通过 cluster addslots 命令为每个节点手动的分配槽的数量。当删除节点 node4 时,node4 上面的 slot 也会均匀的迁移到其他几个节点上。
哈希槽 VS 一致性哈希
-
槽位规模不同,redis 集群将数据划分为 16384 (2^14)个槽位,而一致性hash有 2^32个槽位。固定数量的哈希槽可以简化集群管理,尤其是在实现集群复制和故障转移机制方面;
-
slot 和节点的映射关系不同,一致性hash是通过哈希环顺时针动态映射的,无法很好的手动设置数据分布,而 redis 哈希槽是静态映射,因此可以让用户根据节点的性能进行手动的槽位迁移,从而更加精确地控制数据迁移的过程。
-
redis 哈希槽在集群伸缩时,需要所有节点都参与其中,从而达到节点间数据尽可能均匀的效果,也就是优先保证各个redis节点承担同样的访问压力;而一致性哈希则更侧重于实现尽可能少的数据迁移。
欢迎关注微信订阅号:技术勘察馆



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









