







- 基础讲解
1.1、概念
HDFS(Hadoop Distributed File System),是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的。所谓分布式文件系统,就是随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系 统管理的磁盘中,但是不方便管理和维护,需要一种系统来管理多台机器上的文件。
基础定位:它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。 HDFS的使用场景:适合一次写入多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.2、特点
主要有如下的特点,也是优势所在:
⑴主从架构
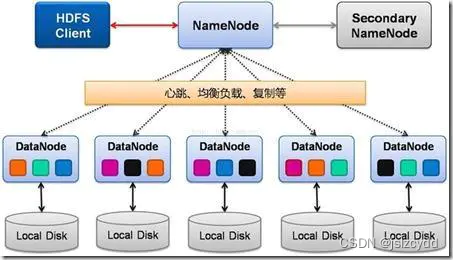
图 1
- Namenode: 作用是接收客户端读写,存元数据信息(元数据信息包括文件谁所有,权限,用户对文件的操作信息(edit logs),文件被分成几块(Block ID),块存在哪些DataNode), 配置副本策略。简单理解就是这个节点是一个管理者,不存放实际的数据,但是文件的读写都是通过它来进行。保存了实际文件的索引和相关的副本信息。
SecondNameNode:辅助Namenode的一个节点。主要是辅助NameNode,分担其工作量。定期合并fsimage和edits-log(这两个东西可以理解成为就是数据存和取中间状态的日志文件),并推送给NameNode。在紧急情况下,可辅助恢复 NameNode。
- Datanode; 真正存数据的节点,数据按块存,当DN启动会向NN汇报块信息。DataNode之间还保存数据的副本,实现数据节点的互相拷贝
⑵分块存储
Hdfs的文件自物理上是进行分块存储的,默认大小是128M,不足128M的则本身就是一块。块的大小可以在启动的时候根据自己的需要进行配置。Hdfs-site.xml中配置dfs.blocksize。例如一个300M的文件,会被分为3块,然后根据他内部算法将这3块分别放到不同的datanode机器进行存储,单个存储完成后再进行副本的复制,将某一台机器上的block复制到其他另外的节点(复制的数据根据配置的副本数,未配置的话默认就是3)
这也是为什么hdfs文件系统不建议用来存储过多的小文件。因为小文件太多其实是比较浪费他的分块的特性的。如上图1所示
⑶副本策略
因为hdfs为了保持数据的高可用性,在保存一份数据的时候会进行副本复制的行为。默认为3份。作为client操作方来说,其实我们不用去关心某一台机器上的数据或者有哪些块,因为无论是写数据还是读取数据,都会通过namenode来进行转发。则保证了获取到的文件列表都是单独的一份不会出现重复。
⑷namespace
其实hdfs内部是维护了一个抽象的目录树,就想的传统的文件系统,在页面上也可以通过/路径/ 的方式去获取到相关路径下的文件列表(仅仅是用于可视化查看)。如果想要在页面上进行操作还需要额外的配置,不过不建议这样子直接在页面进行操作,还是通过hdfs的shell命令或者程序运行的方式来操作文件。
注意:这里还有一种架构模式,就是Hadoop的HA高可用模式,即会有多个namenode节点,可以理解成为防止namenode单点故障而设计的。这种情况下,一般情况是有一台机器的NameNode是active状态,其他的NameNode为standby待机状态,如果某一个NameNode节点宕机其他的namenode才会被激活。这一点可以通过http访问http;//ip:namenode端口/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem,节点中beans中tag.HAState为active表示该节点是激活状态。
- 读写流程
2.1、写数据流程
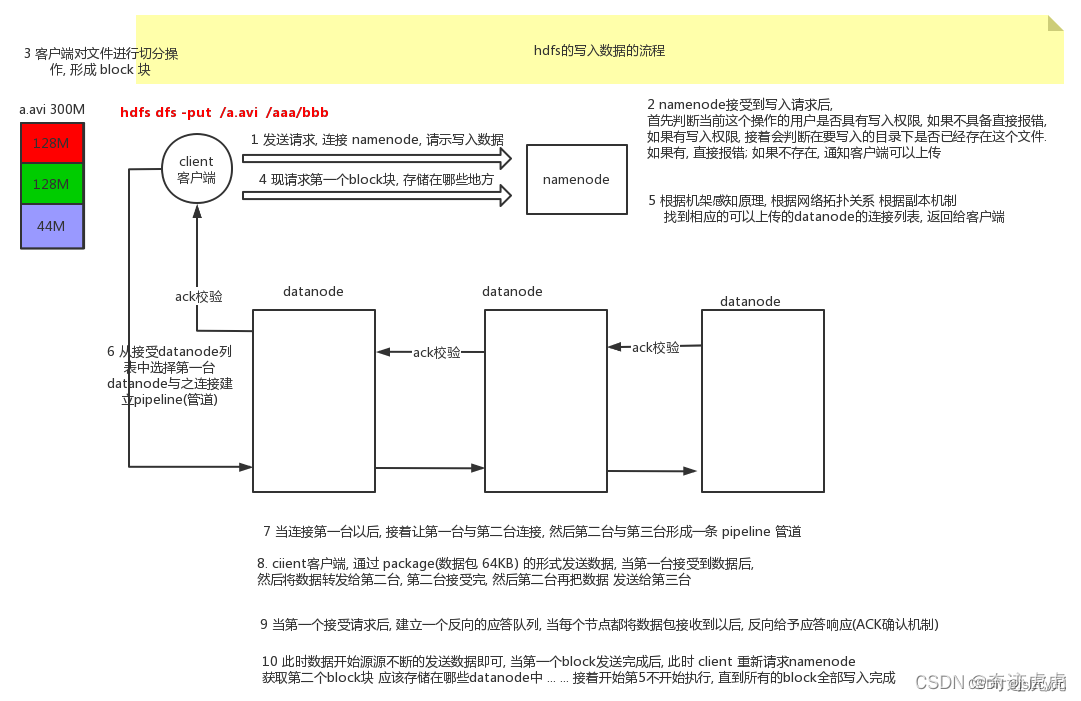
图 2
①client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode 检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
②client 请求第一个 block 该传输到哪些 DataNode 服务器上;
③NameNode 根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的 DataNode 的地址,如:A,B,C;
④client 请求3台 DataNode 中的一台A上传数据(本质上是一个 RPC 调用,建立 pipeline),A收到请求会继续调用B,然后B调用C,将整个 pipeline 建立完成,后逐级返回 client;
⑤client 开始往A上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认64K),A收到一个 packet 就会传给B,B传给C;A每传一个 packet 会放入一个应答队列等待应答。
⑥数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在 pipeline 反方向上,逐个发送 ack(ack 应答机制),最终由pipeline中第一个 DataNode 节点A将 pipeline ack 发送给client;
⑦当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个 block 到服务器。
简单总结:client只需要和NameNode交互,NameNode继续相关的校验和建立传输链接,并选择合适的机器进行数据写入。
2.2、读数据流程

①Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
②NameNode 会视情况返回文件的部分或者全部 block 列表,对于每个 block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
③这些返回的 DataNode 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离Client近的排靠前;心跳机制中超时汇报的 DataNode 状态为 STALE,这样的排靠后;
④Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是 DataNode,那么将从本地直接获取数据;底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
⑤当读完列表的 block 后,若文件读取还没有结束,客户端会继续向 NameNode 获取下一批的 block 列表;
⑥读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的 DataNode 继续读。
⑦read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回 Client 请求包含块的 DataNode 地址,并不是返回请求块的数据;
⑧最终读取来所有的 block 会合并成一个完整的最终文件。
简单总结:client和NameNode进行交互,NameNode来根据请求要获取的文件信息和DataNode进行交互。根据自己的算法来确认文件的所在位置获取不同的块信息,之后进行合并文件并返回给client。
读写文件总结:
从这里可以看出,其实针对我们文件发现的客户端来说,不用真正去关心数据具体存放在哪一个节点或者某个节点上面的数据有哪些。因为块文件存储的性质,某一个节点很有可能只是存放了一部分的块文件,并不能真正代表这个文件。
我们只需要和NameNode节点进行交互,然后从NameNode这里去获取所有的文件列表和文件性质(例如文件大小等)即可。获取到的文件也是唯一的一份而不会出现重复数据的情况。
3、扫描发现
4、其他归纳
4.1、hdfs常用shell命令
操作hdfs有两种方式,一种是hdfs dfs+命令,第二种是hadoop fs +命令。官方推荐是第二种,因为第一种仅仅是针对hdfs这种文件系统的shell,第二种可以支持其他类型的分布式文件系统,比较灵活。其实它的命令很多和Linux的命令都还是很相似的。
⑴创建文件夹
hadoop fs -mkdir /test
新建多级文件夹(某一个层级的文件夹是初始不存在的,则加上-p)
hadoop fs -mkdir -p /test/dir0/dir1
⑵新建文件
hadoop fs -touchz /test/file1
⑶获取指定目录下的文件或文件夹
hadoop fs -ls / (这个代表的是获取跟目录下的文件和文件夹)
注意:这种-ls的方式只会获取到指定目录的下层子目录,不会进行递归获取
可选参数:
-R级联显示paths下文件,这里paths是个多级目录
-h 显示文件的大小
hadoop fs -ls –R /
⑷删除目录和文件
hadoop fs –rm
可选参数:
-f 如果要删除的文件不存在,不显示提示和错误信息
-r 或-R 级联删除目录下的所有文件和子目录文件
-skipTrash直接删除,不进入垃圾回车站
⑸上传文件
hadoop fs –put /home/config /test2
这里代表的是:将Linux机器的/home目录下的config文件上传到hdfs的test2目录下。不指定名称的话,源文件名称是什么就是是什么
hadoop fs –put /home/config /test2/config-copy
这种就代表的上传文件并进行重命名的操作。
注意:如果在同一个目录下已经有了同样名称的文件,则会报错 File exists
可选参数:
-f 如果文件在分布式文件系统上已经存在,则覆盖存储,若不加则会报错。
-p 保持源文件的属性(组、拥有者、创建时间、权限等)。
⑹获取文件
hadoop fs –get /test2/config2 /home
注意:这里的获取可以理解成为一种复制,就get之后原来的hdfs没有任何变化
⑺查看文件内容
hadoop fs –cat /test2/config2
hadoop fs –text /test2/config2
hadoop fs –tail /test2/config2
三种方式都可以进行文件的查看。区别是text不仅可以查看文本文件,还可以查看压缩文件和Avro序列化的文件,其他两个不可以;tail查看的是最后1KB的文件(Linux上的tail默认查看最后10行记录)
可选参数:
-ignoreCrc 忽略循环检验失败的文件
-f 动态更新显示数据,如查看某个不断增长的文件的日志文件
⑻文件追加(文件合并)
hadoop fs –appendToFile /test2/config2 /test2/config
指定多个文件然后后面的文件在第一个文件下进行追加(换行追加的方式)。通常可以用于小文件的合并。
⑼复制文件或者文件夹
hadoop fs –cp SRC [SRC …] DST
注意:这里的SRC和DST要保持属性一致,即同样都是文件或文件夹。
⑽文件权限修改
hadoop fs -chmod 777 /test/file2
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。(和Linux的文件赋权限类似)
4.2、WebHDFS
Hadoop提供了两种Web方式访问HDFS,分别是:WebHDFS和HttpFS
这里简单说一下自带的webHDFS。即通过RESTful接口http的方式来获取一下hdfs相关信息。
前提:在core-site.xml文件中配置了相关信息
格式:http://NameNode的ip:端口号/webhdfs/v1
支持如下:
HTTP GET
• OPEN (see FileSystem.open)
• GETFILESTATUS (see FileSystem.getFileStatus)
• LISTSTATUS (see FileSystem.listStatus)
• GETCONTENTSUMMARY (see FileSystem.getContentSummary)
• GETFILECHECKSUM (see FileSystem.getFileChecksum)
• GETHOMEDIRECTORY (see FileSystem.getHomeDirectory)
• GETDELEGATIONTOKEN (see FileSystem.getDelegationToken)
HTTP PUT
• CREATE (see FileSystem.create)
• MKDIRS (see FileSystem.mkdirs)
• RENAME (see FileSystem.rename)
• SETREPLICATION (see FileSystem.setReplication)
• SETOWNER (see FileSystem.setOwner)
• SETPERMISSION (see FileSystem.setPermission)
• SETTIMES (see FileSystem.setTimes)
• RENEWDELEGATIONTOKEN (see DistributedFileSystem.renewDelegationToken)
• CANCELDELEGATIONTOKEN (see DistributedFileSystem.cancelDelegationToken)
HTTP POST
• APPEND (see FileSystem.append)
4.3、Hadoop2.x和Hadoop3.x
目前主流的有2和3两个大的版本。绝大部分的东西是相同的,尤其是Hadoop2.7.0以后。针对一些我们可以用到的地方这里总结一下。
⑴jdk版本最低要求不同:
Hadoop 2.x - java的最低支持版本是java 7
Hadoop 3.x - java的最低支持版本是java 8
⑵默认端口的修改
在hadoop3.x之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着用户的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。
现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-128
Namenode ports: 50470 --> 9871, 50070--> 9870
Secondary NN ports: 50091 --> 9869,50090 --> 9868
Datanode ports: 50020 --> 9867, 50010--> 9866, 50475 --> 9865, 50075 --> 9864
这里主要是50070--> 9870,50075 --> 9864关注一下。因为这两个IP的话可以用于访问页面的节点信息。















 3590
3590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









