







本文深入剖析Redis命令执行的完整架构设计,从网络层处理到内存操作,再到持久化机制,全方位揭示Redis高性能背后的设计哲学。通过生活化类比和代码示例,详细解析事件驱动模型、单线程架构、协议解析等核心机制,并探讨Redis如何通过精巧的设计在简单性与高性能之间取得平衡。
Redis命令执行的宏观视角
Redis作为当今最流行的内存数据库之一,其卓越的性能表现源于精巧的架构设计。当我们在客户端键入一条简单的SET key value命令时,这个请求在Redis内部经历了一段精妙的旅程。这段旅程始于网络传输,穿越协议解析层,经过命令分派,最终在内存数据结构中完成操作,整个过程通常在微秒级别完成。
生活案例:想象一家高效的快递分拣中心。客户寄件(发送命令)后,快递(网络数据包)通过运输网络到达分拣中心(Redis服务器)。分拣中心有专门的入口接待(网络I/O处理),智能识别系统(协议解析)快速读取快递信息,然后由高效的分拣机器人(命令处理器)将快递准确放入对应区域(内存数据结构)。整个过程快速有序,即使面对海量快递(高并发请求)也能从容应对。
与传统关系型数据库不同,Redis采用单线程事件循环模型处理命令,这种看似简单的设计却成就了其惊人的性能表现。接下来,我们将深入Redis内部,逐层解析命令执行的全过程。
网络层:连接管理与事件驱动
连接建立与套接字管理
当客户端尝试连接Redis服务器时,首先会经历TCP三次握手过程。成功建立连接后,Redis会创建一个client对象来管理这个连接的所有状态。这个对象包含了套接字文件描述符、输入输出缓冲区、命令解析状态机等关键信息。
// Redis客户端连接结构体(简化版)
typedef struct client {
int fd; // 套接字文件描述符
sds querybuf; // 输入缓冲区(动态字符串)
redisDb *db; // 当前选择的数据库指针
int argc; // 命令参数个数
robj **argv; // 命令参数数组
struct redisCommand *cmd;// 要执行的命令
// ... 其他字段省略
} client;
生活案例:这类似于银行为每个到访客户创建一份业务办理档案,记录客户的基本信息、要办理的业务类型以及相关材料。档案跟随客户在整个业务流程中流转,确保服务连贯性。
事件驱动模型
Redis基于Reactor模式实现了高性能的事件驱动架构,其核心是一个事件循环(Event Loop),不断监听并处理各种I/O事件。关键数据结构如下:
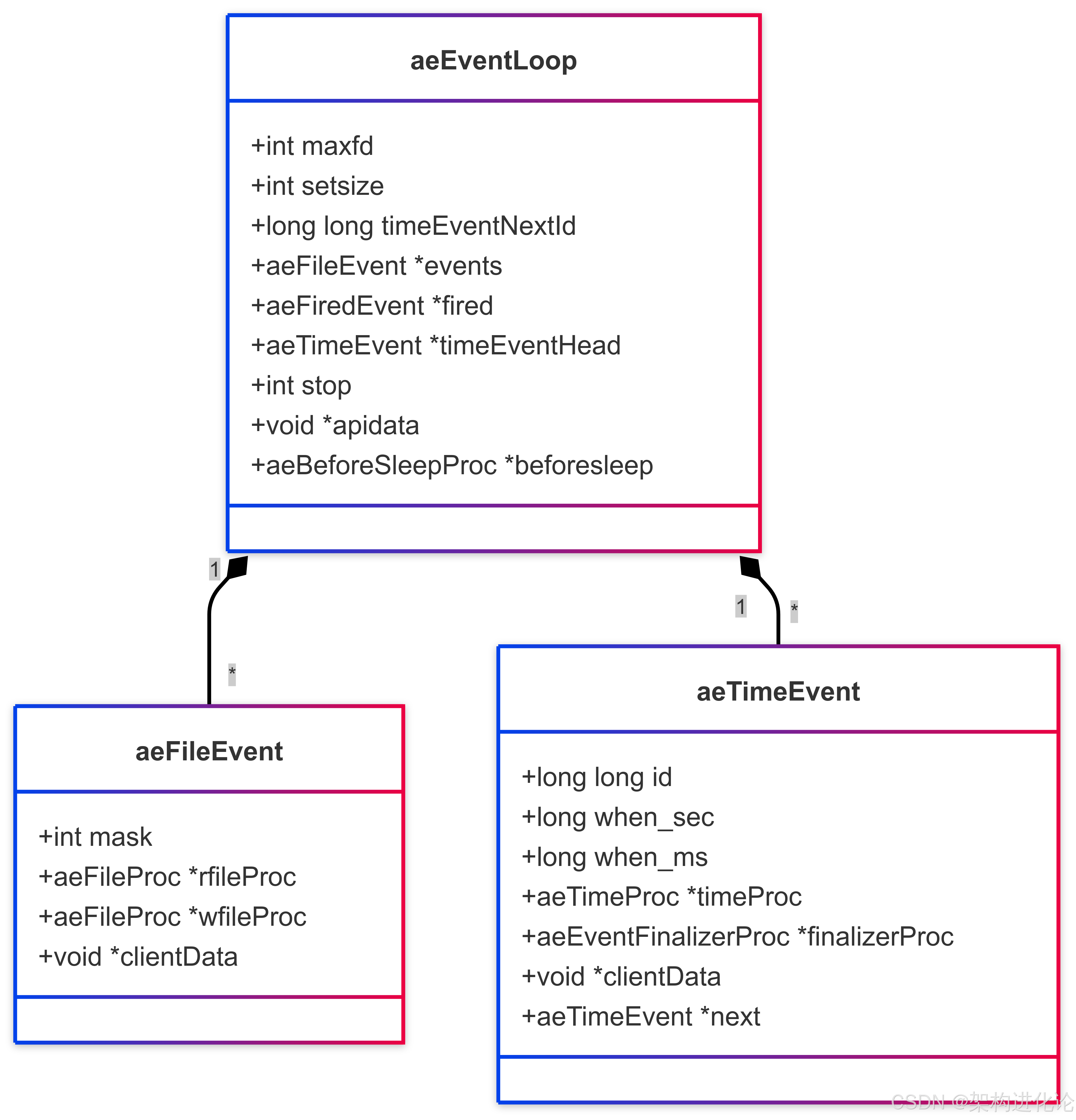
Redis使用I/O多路复用技术(如epoll、kqueue等)同时监听多个套接字,当某个套接字就绪时,事件循环会调用相应的处理函数。这种设计避免了传统阻塞I/O的资源浪费,也规避了多线程上下文切换的开销。
性能公式:Redis单线程模型的理论吞吐量上限可以表示为:
这个公式表明,在单线程模型下,Redis的吞吐量完全取决于平均命令处理时间。由于内存操作极快且没有锁竞争,Redis可以达到每秒数十万级别的QPS。
协议解析:从字节流到Redis对象
Redis协议简介
Redis使用自定义的RESP(REdis Serialization Protocol)协议进行客户端-服务器通信。这种协议在可读性和解析效率之间取得了良好平衡。一条SET key value命令的RESP表示如下:
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n
协议解析过程
Redis采用状态机模式逐步解析输入缓冲区中的协议数据。解析过程大致分为以下几个步骤:
-
读取并解析参数个数(如
*3表示有3个参数) -
逐个读取参数长度和值(如
$3\r\nSET\r\n) -
将解析出的字符串转换为Redis对象(robj)
-
根据命令名称查找对应的命令处理器
// 协议解析核心逻辑(简化版)
int processInputBuffer(client *c) {
while(c->qb_pos < sdslen(c->querybuf)) {
// 1. 解析参数个数
if (c->reqtype == PROTO_REQ_INLINE) {
// 处理内联命令(已废弃)
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
if (c->multibulklen == 0) {
// 解析*后面的数字
c->multibulklen = parseInt(c->querybuf + c->qb_pos);
c->qb_pos += bytesConsumed;
c->argv = zmalloc(sizeof(robj*)*c->multibulklen);
}
// 2. 解析每个bulk
while(c->multibulklen > 0) {
// 解析$后面的数字(字符串长度)
// 读取指定长度的字符串
c->argv[c->argc++] = createStringObject(ptr, len);
c->qb_pos += len+2; // +2 for \r\n
c->multibulklen--;
}
// 3. 执行命令
if (c->multibulklen == 0) {
c->cmd = lookupCommand(c->argv[0]->ptr);
call(c, CMD_CALL_FULL);
resetClient(c);
}
}
}
}
生活案例:这就像海关官员检查入境物品清单。首先确认总件数(参数个数),然后逐件检查每件物品的申报信息(参数长度)和实际内容(参数值),最后根据物品类型(命令名称)决定处理流程(命令处理器)。
命令执行:单线程模型下的高效处理
命令查找与执行
Redis维护了一个命令表(command table),存储所有支持的命令及其处理器。命令表实际上是一个字典结构,以命令名称为键,以redisCommand结构为值。
struct redisCommand {
char *name; // 命令名称
redisCommandProc *proc; // 命令处理器函数指针
int arity; // 参数个数,-N表示至少N个
int flags; // 标志位,如写命令、只读命令等
// ... 其他字段省略
};
当解析出命令名称后,Redis会在命令表中查找对应的redisCommand结构,然后调用其proc函数执行命令。例如,SET命令对应的处理器是setCommand函数。
单线程模型的优势与挑战
Redis采用单线程模型处理命令主要基于以下考虑:
-
避免锁开销:多线程环境下,共享数据结构需要复杂的同步机制
-
减少上下文切换:线程切换在高速处理时会成为显著开销
-
利用CPU缓存局部性:单线程可以更好地利用CPU缓存
-
简化实现:避免竞态条件,降低代码复杂度
性能公式:单线程模型的延迟可以表示为:
其中是命令在队列中的等待时间,
是命令实际处理时间。在低负载情况下,
接近于0。
内存操作与数据结构
Redis的核心价值在于其丰富的数据结构实现。以SET key value命令为例,它实际上是在Redis的键空间(key space)中创建一个字符串对象:
// setCommand实现简化版
void setCommand(client *c) {
robj *o = tryObjectEncoding(c->argv[2]); // 尝试对值进行编码优化
setKey(c->db, c->argv[1], o); // 设置键值对
server.dirty++; // 标记数据库被修改
addReply(c, shared.ok); // 返回响应
}
// 键空间设置函数
void setKey(redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val); // 新增键
} else {
dbOverwrite(db,key,val); // 覆盖已有键
}
// 触发相关事件通知
}
Redis的键空间实际上是一个字典(哈希表),支持时间复杂度的查找、插入和删除操作。字典使用渐进式rehash机制来保证扩容时的性能平稳。
响应返回:完成请求闭环
响应协议构造
命令执行完成后,Redis需要将结果返回给客户端。响应也采用RESP协议格式,不同类型的数据有不同的编码方式:
-
简单字符串:
+OK\r\n -
错误:
-ERR some error\r\n -
整数:
:123\r\n -
批量字符串:
$5\r\nhello\r\n -
数组:
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n
输出缓冲与写事件处理
Redis不会立即将响应写入套接字,而是先存入客户端的输出缓冲区,然后注册写事件。当套接字可写时,事件循环会触发写处理器发送数据:
// 添加响应到输出缓冲区
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
if (sdsEncodedObject(obj)) {
// 字符串类型响应
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyStringToList(c,obj->ptr,sdslen(obj->ptr));
} else if (obj->encoding == OBJ_ENCODING_INT) {
// 整数类型响应
char buf[32];
int len = ll2string(buf,sizeof(buf),(long)obj->ptr);
_addReplyToBuffer(c,buf,len);
}
// ... 其他类型处理
}
// 准备客户端写入状态
int prepareClientToWrite(client *c) {
if (c->flags & CLIENT_PENDING_WRITE) {
// 已经注册了写事件
return C_OK;
}
// 注册写事件
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE, sendReplyToClient, c);
c->flags |= CLIENT_PENDING_WRITE;
return C_OK;
}
这种缓冲+事件驱动的写机制可以有效避免阻塞,特别是在客户端接收速度较慢(如网络延迟高)的情况下。
高级主题:持久化与多线程演进
持久化对命令执行的影响
当Redis配置了持久化(AOF)时,每个写命令在执行后还会被追加到AOF缓冲区:
void call(client *c, int flags) {
// 执行命令
c->cmd->proc(c);
// 如果命令修改了数据且需要AOF持久化
if ((flags & CMD_CALL_PROPAGATE_AOF) && server.aof_state != AOF_OFF) {
// 传播到AOF
propagate(c->cmd,c->db->id,c->argv,c->argc,PROPAGATE_AOF);
}
}
AOF缓冲区会定期被写入磁盘,这个过程可能由主线程同步执行(影响性能),也可能由后台线程异步执行(Redis 6.0+)。
Redis多线程演进
虽然Redis核心命令处理保持单线程,但现代版本已引入多线程处理某些特定任务:
-
后台IO线程:Redis 6.0引入多线程处理网络IO(读请求解析和写响应发送)
-
后台持久化线程:某些持久化操作可以在后台线程执行
这种混合模型既保持了核心路径的单线程简单性,又利用多核CPU处理辅助任务,是Redis性能持续演进的重要方向。
总结:Redis设计哲学
Redis命令执行架构体现了几个核心设计理念:
-
简单性优先:单线程模型避免了复杂的并发控制
-
针对性优化:为特定工作负载(高速缓存、简单数据操作)定制设计
-
平衡的艺术:在内存使用、CPU效率、网络吞吐之间寻求最佳平衡
-
渐进式演进:保持核心架构稳定的前提下逐步引入新特性
生活案例:这就像一家米其林餐厅的后厨设计。主厨(单线程)专注于最重要的烹饪环节(命令执行),确保每道菜(每个命令)的完美品质。同时,配菜师(IO线程)负责食材准备(网络IO),洗碗工(后台线程)处理清洁工作(持久化),各司其职又相互配合,实现整体高效运转。
Redis的成功证明,在分布式系统领域,有时“少即是多”——精心设计的简单架构往往比复杂的多线程方案更能满足特定场景的需求。理解Redis命令执行的内在机制,不仅有助于更好地使用Redis,也为设计高性能系统提供了宝贵思路。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









