




 本文使用Python Scrapy爬取并分析了豆瓣《安家》的评论,通过评论时间、评分和内容揭示了电视剧的受欢迎程度和观众反馈。数据显示,评论在播出初期和特定事件后达到高峰,晚上8点至凌晨2点的评论最多,大部分观众给予推荐及以上评分,其中角色情绪分析出人意料。
本文使用Python Scrapy爬取并分析了豆瓣《安家》的评论,通过评论时间、评分和内容揭示了电视剧的受欢迎程度和观众反馈。数据显示,评论在播出初期和特定事件后达到高峰,晚上8点至凌晨2点的评论最多,大部分观众给予推荐及以上评分,其中角色情绪分析出人意料。
最近最火的电视剧,非《安家》莫属了。这是一部讲述房产中介的故事,有一个中介公司叫做“安家天下”,其中有两个店长,在剧情设定方面,我们就知道,这中间肯定会发生一些有(gou)趣(xue)的故事。因此我用Python爬取了豆瓣《安家》下所有的评论,进行了一波分析,从观众的角度来了解这部电视剧。
Part.1 爬虫部分
先来讲下技术栈,这个项目我用的是Scrapy+JSON的方式实现的。技术难度并不复杂,毕竟豆瓣并不是一个反爬虫很厉害的网站(学爬虫基本上都做过爬取top250),只要设置好User-Agent就行。在这里我就大概的描述一下代码过程,想要代码的可以在评论区评论“安家”,获取。
第一步通过Scrapy命令创建一个项目和爬虫:
scrapy startproject anjia_scrapy
cd anjia_scrapy
scrapy genspider anjia "douban.com"
然后开始编写爬虫。爬虫部分可以分开来讲一下,首先找到《安家》的评论页面的链接:https://movie.douban.com/subject/30482003/reviews?sort=time&start=0,这个链接是通过offset来获取评论的,每一页展示20条评论,因此如果要获取下一页的数据,就是设置在当前页面基础上,给start+20就行了,这是第一点。然后总共有38页(后续页数据没有)因此可以生成一个range(0,760,20)了。
第二点是评论内容数据,如果超过一定的字数是会隐藏的,看下截图:
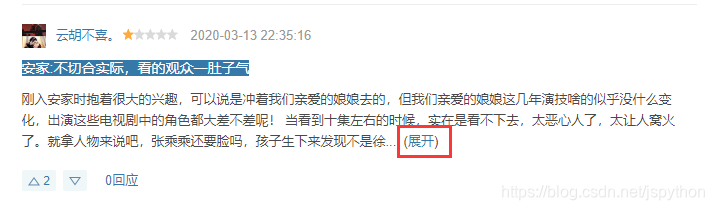
他的这个展开操作,并不是直接在界面上显示一下而已,而是发送了一次网络请求,因此我们还得针对每条评论重新请求一次,链接为:https://movie.douban.com/j/review/12380383/full,其中review后面的是这个评论的id,id可以在源代码中获取,这里就不再赘述了。
搞清楚了以上两点,我们就可以开始写代码了(数据提取规则这里不展开来讲,有兴趣的可以在评论区评论:安家获取源代码):
class AnjiaSpider(scrapy.Spider):
name = 'anjia'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/subject/30482003/reviews?sort=time&start=0']
def parse(self, response):
# 获取评论标签列表
review_list = response.xpath("//div[contains(@class,'review-list')]/div")
for review_div in review_list:
# 作者
author = review_div.xpath(".//a[@class='name']/text()").get()
# 发布时间
pub_time = review_div.xpath(".//span[@class='main-meta']/text()").get()
# 评分
rating = review_div.xpath(".//span[contains(@class,'main-title-rating')]/@title").get() or ""
# 标题
title = review_div.xpath(".//div[@class='main-bd']/h2/a/text()").get()
# 是否有展开按钮
is_unfold = review_div.xpath(".//a[@class='unfold']")
if is_unfold:
# 获取评论id
review_id = review_div.xpath(".//div[@class='review-short']/@data-rid").get()
# 获取内容
content = self.get_fold_content(review_id)
else:
content = review_div.xpath(".//div[@class='main-bd']//div[@class='short-content']/text()").get()
if content:
content = re.sub(r"\s",'',content)
# 创建item对象
item = AnjiaItem(
author=author,
pub_time=pub_time,
rating=rating,
title=title,
content=content
)
yield item
# 如果有下一页
next_url = response.xpath("//span[@class='next']/a/@href").get()
if next_url:
# 请求下一页的数据
yield scrapy.Request(response.urljoin 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









