







前提:安装好hadoop和jdk
1.下载Scala和Spark
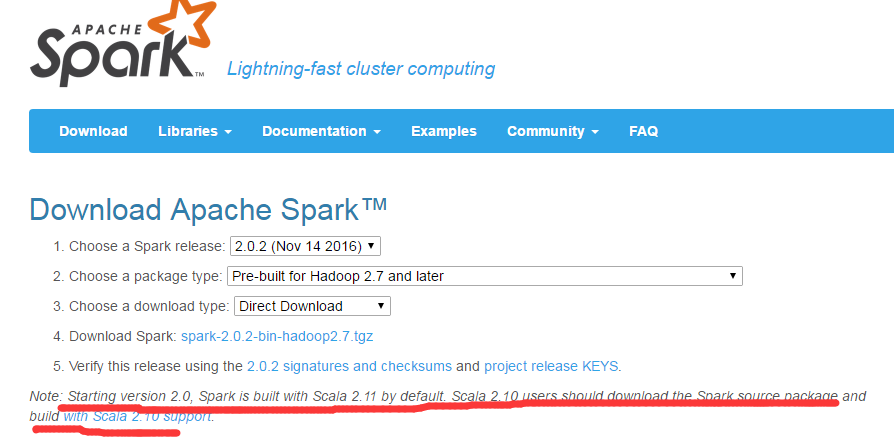
在spark官网选择好自己要安装的版本,注意scala和spark的版本得匹配,官网地址:http://spark.apache.org/downloads.html
spark下载链接:
http://219.239.26.11/files/10360000096A73F4/d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz
scala下载链接:
http://downloads.lightbend.com/scala/2.12.0/scala-2.12.0.tgz
2.安装
解压spark和scala的安装包:
我解压到了/usr/local/文件夹下
tar -zxvf scala-2.12.0.tgz -C /usr/local
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /usr/local
3.配置环境变量
如果有专门的用户可以配置到~/.bashrc里面,root下也可以配置到/etc/profile里面
这里我专门建了一个hadoop用户 ,所以配置到了~/.bashrc里面
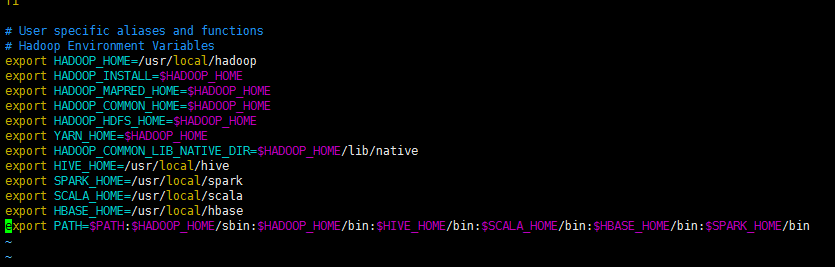
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin4.修改配置文件 spark-env.sh
进入spark安装目录 conf目录执行如下命令:
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加 hadoop、scala 、java环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_45
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export SPARK_MASTER_IP=hadooplocal5.启动测试
测试scala:
输入scala命令,返回以下信息为成功:

启动spark:
SPARKHOME/sbin/start−all.sh测试Spark是否安装成功:
SPARK_HOME/bin/run-example SparkPi
得到结果:
Pi is roughly 3.1393756968784845
然后访问http://hadooplocal:8080成功
停止:
$SPARK_HOME/sbin/stop-all.sh















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









