










近几年,很多人都听到过一个名词“大数据”也有一部分人选择学习了解大数据,那么大数据到底是什么?学习大数据需要有Java基础吗?接下来,小编带你详细了解一下。
如果要学习大数据,不管你是零基础,还是有一定的基础,都应该知道在学大数据之前一定要懂至少一种计算机编程语言,因为大数据的开发离不开编程语言,不仅要懂,还要精通!

大数据到底是什么呢?其实从概念上解释总归是不具体的,要想真正清楚地了解大数据最好还是能接触到相关项目。抽象化的概念都具体化不仅仅有利于学生们对大数据的认识,更重要的是可以通过实际项目的练习积累到更多的实战经验。
而世界编程语言有很多种,但在网络编程中应用比较广泛又适合大数据开发的Java是比较合适的。因为Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点。如果你对Java有一定的了解,就更应该清楚Java是一个强类型编程语言,拥有极高的跨平台能力,还有就是Java的异常处理能够保证系统的稳定性。
目前,Java语言的应用是最广泛的,在全世界排名第一,对于要学习大数据的人而言是最佳选择。hadoop及其他大数据处理技术都用到了Java,像Apache的基于Java的HBase和Accumulo以及 ElasticSearchas等等。
所以,学习大数据最好要从Java编程语言开始学起!另外,学习大数据和学习其他编程语言一样,一定要参加到实际项目中去,在实际应用中积累足够多的实战经验,它会直接影响到找工作,也会直接影响到薪资待遇!
1.Linux基础和分布式集群技术
学完此阶段可掌握的核心能力:
熟练使用Linux,熟练安装Linux上的软件,了解熟悉负载均衡、高可靠等集群相关概念,搭建互联网高并发、高可靠的服务架构;
学完此阶段可解决的现实问题:
搭建负载均衡、高可靠的服务器集群,可以增大网站的并发访问量,保证服务不间断地对外服务;
学完此阶段可拥有的市场价值:
具备初级程序员必要具备的Linux服务器运维能力。
1.内容介绍:
在大数据领域,使用最多的操作系统就是Linux系列,并且几乎都是分布式集群。该课程为大数据的基础课程,主要介绍Linux操作系统、Linux常用命令、Linux常用软件安装、Linux网络、防火墙、Shell编程等。
2.案例:搭建互联网高并发、高可靠的服务架构。
2.离线计算系统课程阶段
1. 离线计算系统课程阶段
HADOOP核心技术框架
学完此阶段可掌握的核心能力:
1、通过对大数据技术产生的背景和行业应用案例了解hadoop的作用;2、掌握hadoop底层分布式文件系统HDFS的原理、操作和应用开发;3、掌握MAPREDUCE分布式运算系统的工作原理和分布式分析应用开发;4、掌握HIVE数据仓库工具的工作原理及应用开发。
学完此阶段可解决的现实问题:
1、熟练搭建海量数据离线计算平台;2、根据具体业务场景设计、实现海量数据存储方案;3、根据具体数据分析需求实现基于mapreduce的分布式运算程序;
学完此阶段可拥有的市场价值:
具备企业数据部初级应用开发人员的能力
1.1 HADOOP快速入门
1.1.1 hadoop知识背景
什么是hadoop、hadoop产生背景、hadoop在大数据云计算中的位置和关系、国内hadoop的就业情况分析及课程大纲介绍
国内外hadoop应用案例介绍
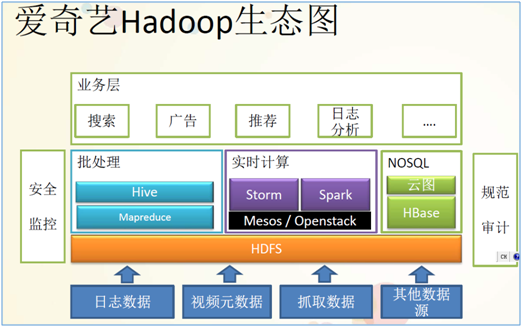
分布式系统概述、hadoop生态圈及各组成部分的简介

1.1.2 HIVE快速入门
hive基本介绍、hive的使用、数据仓库基本知识
1.1.3 数据分析流程案例
web点击流日志数据挖掘的需求分析、数据来源、处理流程、数据分析结果导出、数据展现
1.1.4 hadoop数据分析系统集群搭建
集群简介、服务器介绍、网络环境设置、服务器系统环境设置、JDK环境安装、hadoop集群安装部署、集群启动、集群状态测试
HIVE的配置安装、HIVE启动、HIVE使用测试
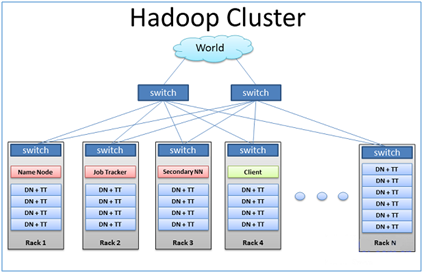
1.2 HDFS详解
1.2.1 HDFS的概念和特性
什么是分布式文件系统、HDFS的设计目标、HDFS与其他分布式存储系统的优劣势比较、HDFS的适用场景
1.2.2 HDFS的shell操作
HDFS命令行客户端启动、HDFS命令行客户端的基本操作、命令行客户端支持的常用命令、常用参数介绍
1.2.3 HDFS的工作机制
HDFS系统的模块架构、HDFS写数据流程、HDFS读数据流程
NAMENODE工作机制、元数据存储机制、元数据手动查看、元数据checkpoint机制、NAMENODE故障恢复、DATANODE工作机制、DATANODE动态增减、全局数据负载均衡
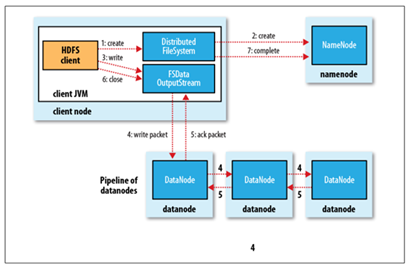
1.2.4 HDFS的java应用开发
搭建开发环境、获取api中的客户端对象、HDFS的java客户端所具备的常用功能、HDFS客户端对文件的常用操作实现、利用HDFS的JAVA客户端开发数据采集和存储系统
1.3 MAPREDUCE详解
1.3.1 MAPREDUCE快速上手
为什么需要MAPREDUCE、MAPREDUCE程序运行演示、MAPREDUCE编程示例及编程规范、MAPREDUCE程序运行模式、MAPREDUCE程序调试debug的几种方式
1.3.2 MAPREDUCE程序的运行机制
MAPREDUCE程序运行流程解析、MAPTASK并发数的决定机制、MAPREDUCE中的combiner组件应用、MAPREDUCE中的序列化框架及应用、MAPREDUCE中的排序、MAPREDUCE中的自定义分区实现、MAPREDUCE的shuffle机制、MAPREDUCE利用数据压缩进行优化、MAPREDUCE程序与YARN之间的关系、MAPREDUCE参数优化
通过以上各组件的详解,深刻理解MAPREDUCE的核心运行机制,从而具备灵活应对各种复杂应用场景的能力
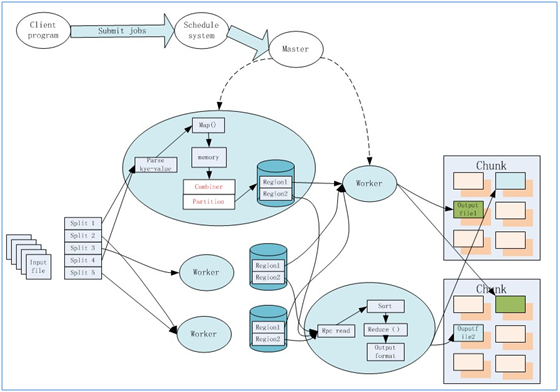
MAPREDUCE实战编程案例:通过一个实战案例来熟悉复杂MAPREDUCE程序的开发。该程序是从nginx服务器产生的访问服务器中计算出每个访客的访问次数及每次访问的时长。原始数据样例如下:

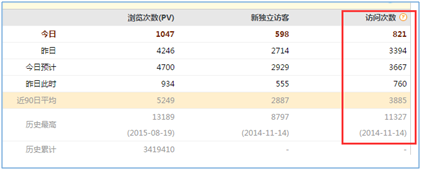
通过一系列的MAPREDUCE程序——清洗、过滤、访问次数及时间分析,最终计算出需求所要的结果,用于支撑页面展现:
1.4 HIVE增强
1.4.1 HIVE基本概念
HIVE应用场景、HIVE内部架构、HIVE与hadoop的关系、HIVE与传统数据库对比、HIVE的数据存储机制、HIVE的运算执行机制
1.4.2 HIVE基本操作
HIVE中的DDL操作、HIVE中的DML操作、在HIVE中如何实现高效的JOIN查询、HIVE的内置函数应用、HIVE shell的高级使用方式、HIVE常用参数配置、HIVE自定义函数和TRANSFORM的使用技巧、HIVE UDF开发实例
1.4.3 HIVE高级应用
HIVE执行过程分析及优化策略、HIVE在实战中的最佳实践案例、HIVE优化分类详解、HIVE实战案例--数据ETL、HIVE实战案例--用户访问时长统计
第一章 大数据概述
1.1大数据故事
点球(分析对手的特点)
电商(分析消费习惯,广告定点投放等)
1.2大数据背景
无处不在的大数据:科学数据、金融数据、物联网数据、交通数据、社交网络数据、零售数据等
1.3大数据的基本概念
大数据的4V特征:

大数据解决的问题:

1.4大数据涉及到的技术
数据采集、数据存储、数据处理/分析/挖掘、可视化
1.5大数据带来的挑战
对现有数据库管理技术的挑战
经典数据库并没有考虑数据的多类别
实时性的技术挑战
网络架构、数据中心、运维的挑战
其他挑战:数据隐私、数据源的复杂多样等
1.6 挑战之如何对大数据进行存储和分析
系统瓶颈:存储容量、读写速度、计算效率
Google大数据技术:GFS、BigTable、MapReduce
http://blog.csdn.net/myan/article/details/1726553
1.7如何学好大数据
查找官网、英文
项目实战融会贯通
参加社区活动
多动手、多练习、坚持















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









