







最好和最坏情况时间复杂度(best case time complexity)
案例代码如下:
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) pos = i;
}
return pos;
}
上面代码非常的简单 ,在无序的数组里,找变量x出现的位置。没找到就返回-1。这段代码的时间复杂度是O(n),n为数组的长度。
我们在数组中查找一个数据,其实不需要将数组都遍历一遍。上面那段代码不高效,下面给出优化的代码:
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
显然优化完后的代码的时间复杂度不再是O(n)了,以简单的复杂度分析的方法并解决不了这一问题了。
因为需要查找的x的位置充满了不确定性,既有可能在第一个,也有可能在最后一个。所以我们就需要引入三个概念:最好时间复杂度,最坏时间复杂度和平均时间复杂度。
最好时间复杂度和最坏时间复杂度都很好理解,该段代码的最坏时间复杂度便是O(n),最好时间复杂度是O(1)。因为最好情况x在第一个就找到了,最坏情况会找不到或者在最后一位。
稍微需要花点脑子的就是平均时间复杂度分析,我们依旧拿着查找变量x的例子来解释。
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
要查找x在数组中的位置有n+1种情况(在数组0~n-1位置或不在数组中),俺们将每种情况下,查找需要遍历的数据个数累加,除n+1,就可以得到需要遍历的数据个数的平均值。
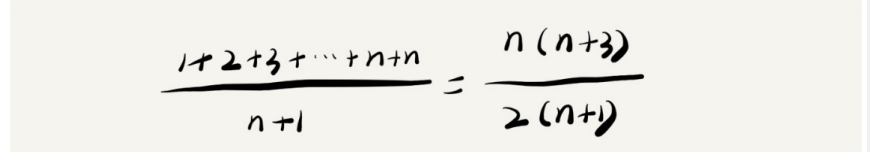
我们在大O标记法中,可以省去系数,低阶,常量, 所以,俺们可以讲上面的公式简化,便是O(n)。
虽然这个结论是对的,在n+1种情况内每种情况出现的概率并不是一样的。
我们知道,x要么在数组,要么就不在数组。在数组与不在数组的概率为1/2。另外,我们需要查找的数据x出现在0~ n-1,其概率也是一样的为1/n。根据概率乘法法则,要查找的数据x出现在0~n-1中任意位置的概率为1/(2n)。
按照这样的方法计算的平均时间复杂度就变成了:
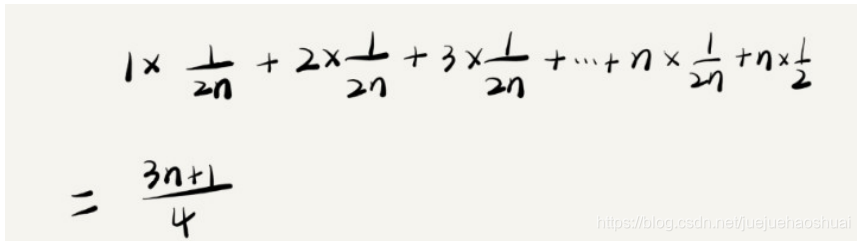
该值是概率论的加权平均值,就是期望值,所以平均时间复杂度的全称就是加权平均时间复杂度或者期望时间复杂度。
引入概率后代码的加权平均值为(3n+1)/4。用大O表示法来表示还是O(n)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









