









目录
一、导入Xml4j.rar到Idea中
测试环境:Windows10专业版
应用软件:IntelliJ IDEA 2021.1 x64
测试时间:2022年8月21日 20点22分
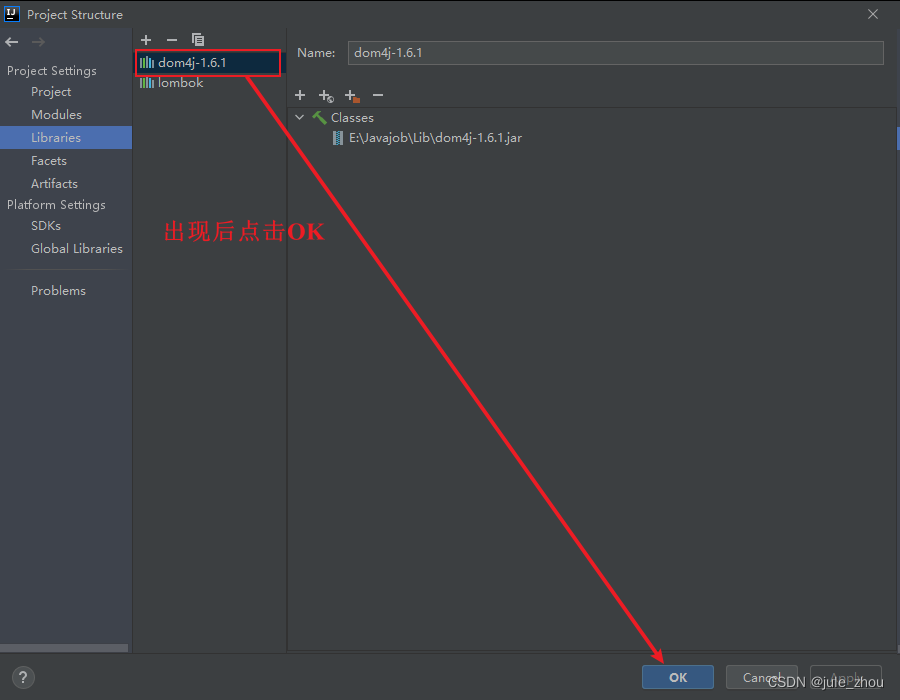
File–>Project Structure…
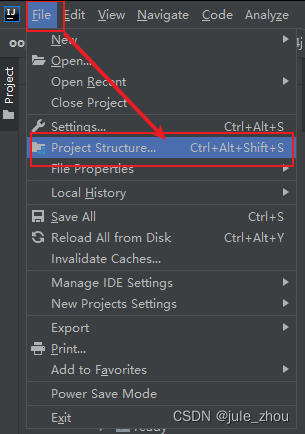
Project Settings–>Libraries–>+
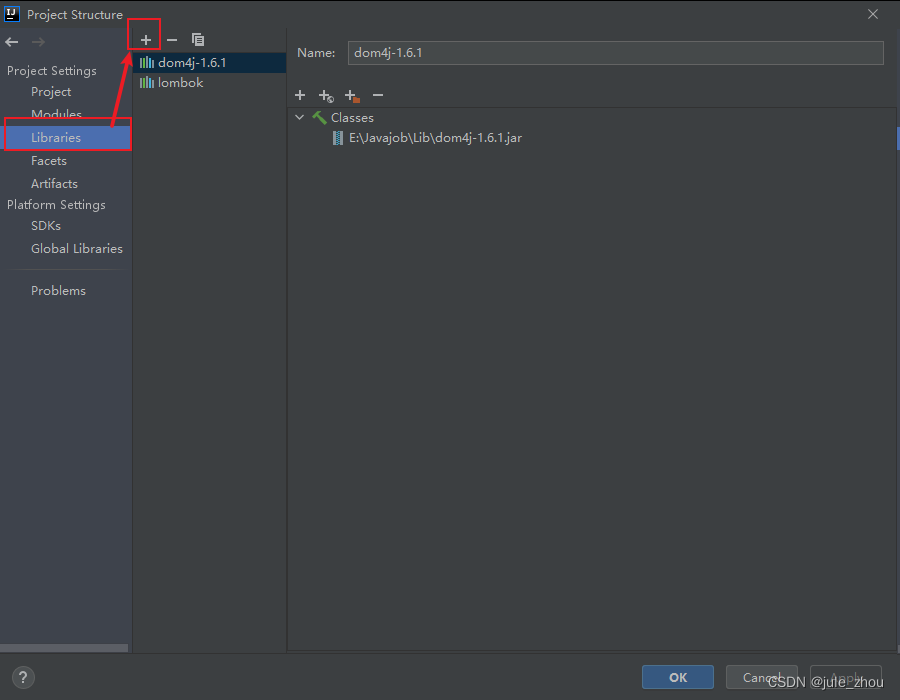 ±->Java
±->Java
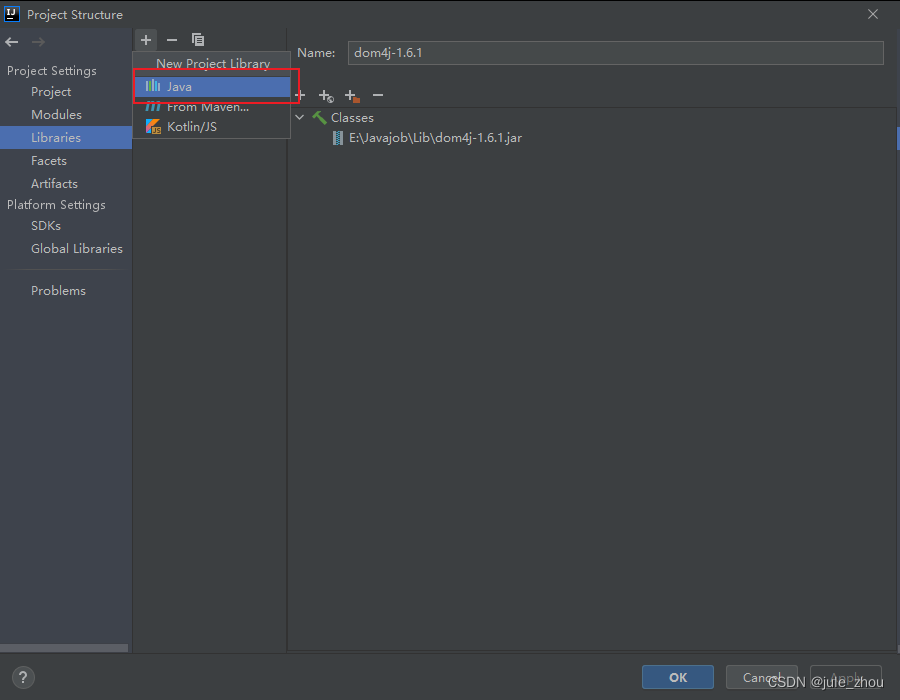 目录–>OK
目录–>OK
二、Xml4j在Java中的操纵
1.在Java中读取文件的操作
(一).初始化
/**
* @description 将XML转为Document对象
* @author Jule_zhou
* @date 2022-08-20 16:38:27
* @param file 文件地址
* @return
*/
public static Document document(File file) {
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(file);
} catch (DocumentException e) {
e.printStackTrace();
}
return document;
}
附加代码
// 获取根节点
Element rootElement = document.getRootElement();
(二).遍历节点
/**
* @description 遍历一个节点中的次一级所有节点
* @author Jule_zhou
* @date 2022-08-21 11:45:05
* @param element 子一级节点List集合
* @return {@link ArrayList < Element >} 父级节点
*/
static ArrayList<Element> getLastElement(Element element){
// 存放节点信息
ArrayList<Element> elements = new ArrayList<>();
Iterator<Element> iterator = element.elementIterator();
// 遍历所有次一级节点
while (iterator.hasNext()){
// 遍历拿取节点
Element lastElement = iterator.next();
// 添加节点信息,存储到List中
elements.add(lastElement);
}
return elements;
}
主要代码说明
// 获取当前标签节点下的所有子节点标签
// 当前节点为Element element;
Iterator<Element> iterator = element.elementIterator();
(三).遍历得到节点中的内容
/**
* @description 遍历标签中文本内容
* @author Jule_zhou
* @date 2022-08-21 12:13:58
* @param element
* @return {@link String} 文本
*/
static String getText(Element element)throws NullPointerException{
String str = "";
str = element.getTextTrim();
if ("".equals(str)){
throw new NullPointerException("未找到文本内容!");
}
return str;
}
特别代码说明
// getTextTrim()方法可以去除换行,如果存在多行数据,在str会出现间隔,但仍然是一个字符串(且该字符串内不存在换行)
// getTextTrim()方法不可以去除换行,会有大量空格产生
String str = element.getTextTrim();
附加代码
// attributeValue(String)方法可获得该节点属性值,其中需要传递一个String类型的属性名称
// 在Xml文件中<body number = "000"></body>,number就是属性名称,000就是属性值
String number = element.attributeValue("number");
(四).总结
| 方法名 | 作用 |
|---|---|
| SAXReader() | 解析Xml文件 |
| saxReader.read() | 读取文档并返回一个文档实体类型 |
| document.getRootElement() | 获取Xml根节点 |
| element.elementIterator(); | 获取字节点 |
| getTextTrim() | 获得文本 |
| element.attributeValue() | 获得属性值 |
2.存储已经创建好的Document树(文件保存)
/**
* @description 存储数据
* @author Jule_zhou
* @date 2022-08-21 22:56:59
* @param document 要写入的数据Document类型
* @return
*/
public void write(Document document,File file){
// 创建格式化
OutputFormat outputFormat = OutputFormat.createPrettyPrint();
// 设置编码格式
outputFormat.setEncoding("UTF-8");
try {
// 创建写入,(创建写入方式,设定编码格式)
XMLWriter xmlWrite = new XMLWriter(new FileWriter(file),outputFormat);
// 写入Document文件
xmlWrite.write(document);
xmlWrite.flush();
xmlWrite.close();
} catch (IOException e) {
e.printStackTrace();
}
知识点附加
OutputStream带有Stream字节流
Writer,字符流,更适合于中文读写
主要代码说明
// 创建格式化
OutputFormat outputFormat = OutputFormat.createPrettyPrint();
// 设置编码格式
outputFormat.setEncoding("UTF-8");
// 创建FileWrite的字符流写入
FileWrite fileWrite = new FileWriter(file);
// 创建写入,(创建写入方式,设定编码格式)
XMLWriter xmlWrite = new XMLWriter(fileWrite ,outputFormat);
// 使用write方法写入Document文件
xmlWrite.write(document);
3.创建一个DOM4j实例
/**
* @description 创建一个DOM4j实例
* @author Jule_zhou
* @date 2022-08-24 16:12:20
* @param
* @return {@link Document}
*/
public Document createDocument(){
// 创建一个Document对象
Document document = DocumentHelper.createDocument();
// 添加根节点
Element rootEle = document.addElement("mobiles");
// 添加子节点
Element cardNumberEle = rootEle.addElement("cardNumber");
// 添加cardNumberEle节点的属性
cardNumberEle.addAttribute("number","0000000");
// 添加cardNumber的子节点
Element mobilCardEle = cardNumberEle.addElement("mobilCard");
Element consumInfosEle = cardNumberEle.addElement("consumInfos");
// 添加mobilCardEle的子节点
Element userNameEle = mobilCardEle.addElement("userName");
Element passWordEle = mobilCardEle.addElement("passWord");
Element serPackageEle = mobilCardEle.addElement("serPackage");
Element consumAmoutEle = mobilCardEle.addElement("consumAmout");
Element moneyEle = mobilCardEle.addElement("money");
Element realTalkTimeEle = mobilCardEle.addElement("realTalkTime");
Element realSMSCountEle = mobilCardEle.addElement("realSMSCount");
Element realFlowEle = mobilCardEle.addElement("realFlow");
// 添加consumInfosEle的子节点
Element consumInfoEle = consumInfosEle.addElement("consumInfo");
// 添加consumInfoEle的子节点的属性
consumInfoEle.addAttribute("id","0");
// 添加serPackageEle的子节点
Element priceEle = serPackageEle.addElement("price");
Element talkTimeEle = serPackageEle.addElement("talkTime");
Element smsCountEle = serPackageEle.addElement("smsCount");
Element flowEle = serPackageEle.addElement("flow");
// 添加consumInfosEleEle的子节点
Element typeEle = consumInfoEle.addElement("type");
Element consumDataEle = consumInfoEle.addElement("consumData");
return document;
}
主要代码说明
// 创建一个Document对象(创建对象)
Document document = DocumentHelper.createDocument();
// 添加根节点(创建节点)
Element rootEle = document.addElement("mobiles");
// 添加子节点(创建节点)
Element cardNumberEle = rootEle.addElement("cardNumber");
// 添加cardNumberEle节点的属性(添加属性)
cardNumberEle.addAttribute("number","0000000");
















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











