





《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
1 Job概述
1.1 Job概念
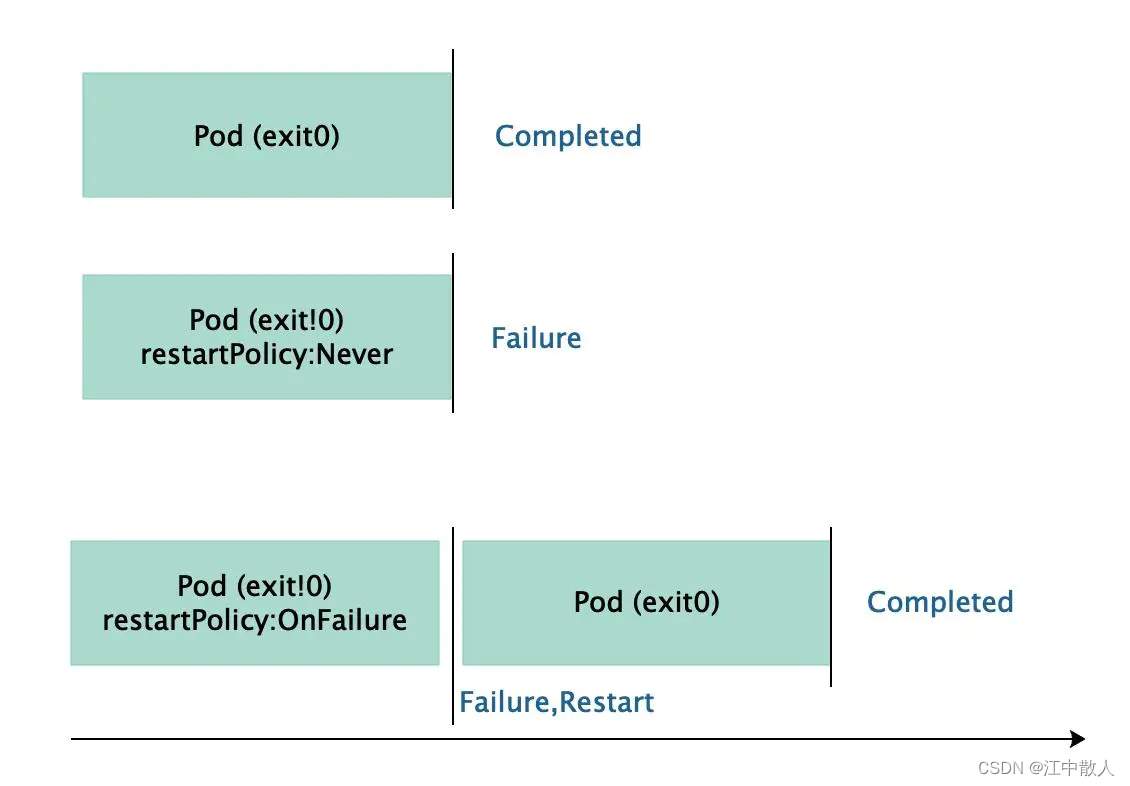
Job 负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。容器中的进程在正常运行结束后不会对其进行重启,而是将Pod对象置于"Completed"(完成)状态,若容器中的进程因错误而终止,则需要按照重启策略配置确定是否重启,未运行完成的Pod对象因其所在的节点故障而意外终止后会被调度。Job控制器的Pod对象的状态转换如下图所示:
1.2 Job 类型
Kubernetes 支持以下几种 Job:
- 非并行 Job:通常创建一个 Pod 直至其成功结束
- 固定结束次数的 Job:设置 .spec.completions,创建多个 Pod,直到 .spec.completions 个 Pod 成功结束
- 带有工作队列的并行 Job:设置 .spec.Parallelism 但不设置 .spec.completions,当所有 Pod 结束并且至少一个成功时,Job 就认为是成功
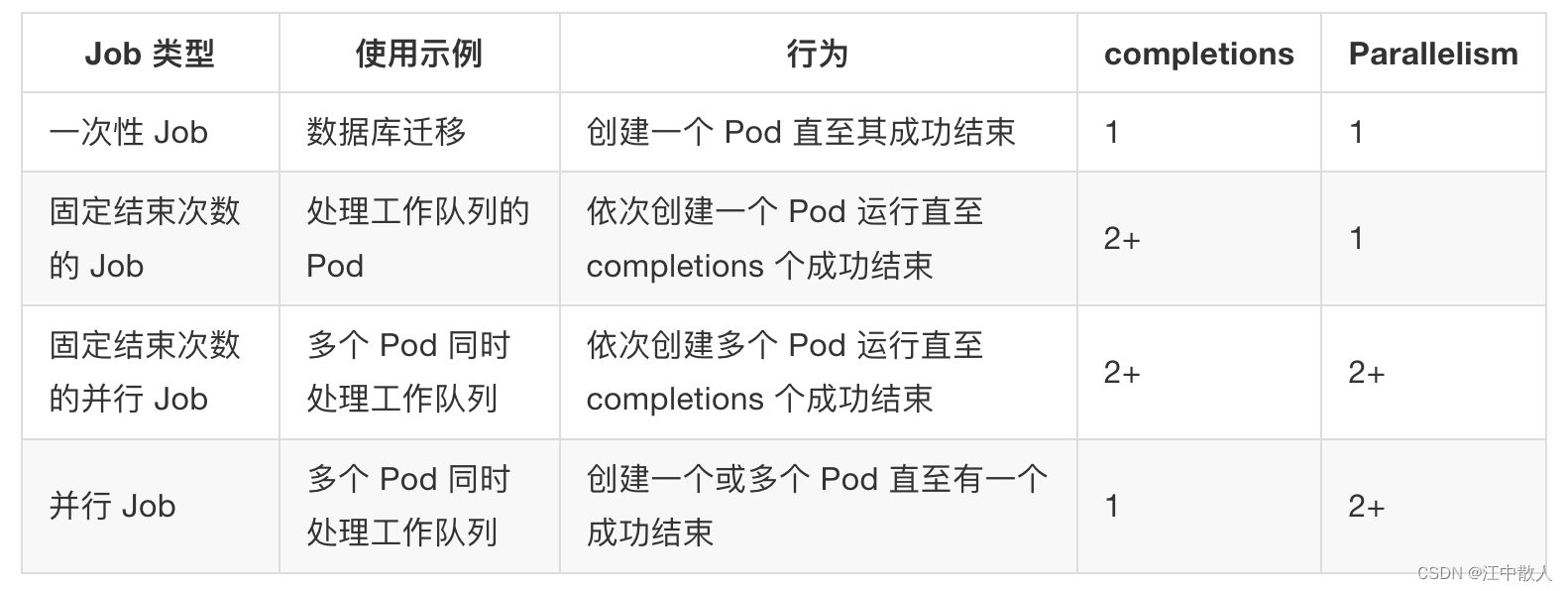
根据 .spec.completions 和 .spec.Parallelism 的设置,可以将 Job 划分为以下几种 pattern:
1.3 Job控制器运行模式
有的作业可能需要运行不止一次,用户可以配置它们以串行或者并行的方式运行。
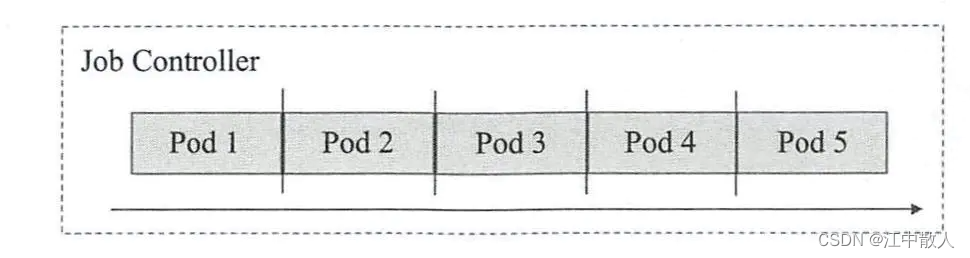
- 单工作队列(work queue):串行式Job,N个作业需要串行运行N次,直至满足期望的次数。如下图所示,这次Job也可以理解为并行度为1的作业执行方式,在某个时刻仅存在一个Pod资源对象。
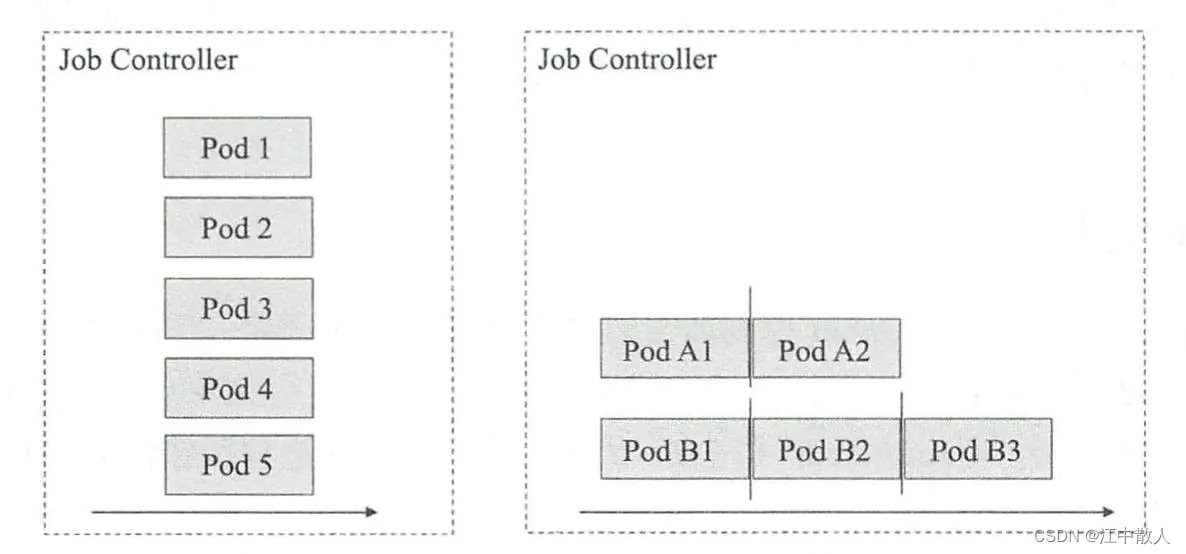
- 多工作队列:并行式Job,这种方式可以设置工作队列数量,即为一次可以执行多个工作队列,每个队列负责一个运行作业,如下图所示,有五个作业,我们就启动五个工作队列去并行执行,当然五个作业,我们也可以只启动两个工作队列去串行执行,两个队列每次各执行一个作业,则一个队列需要执行三次,另一个执行两次。
1.4 Bare Pods
所谓 Bare Pods 是指直接用 PodSpec 来创建的 Pod(即不在 ReplicaSets 或者 ReplicationCtroller 的管理之下的 Pods)。这些 Pod 在 Node 重启后不会自动重启,但 Job 则会创建新的 Pod 继续任务。所以,推荐使用 Job 来替代 Bare Pods,即便是应用只需要一个 Pod。
2 Job使用
2.1 Job Spec 格式
- spec.template 格式同 Pod
- RestartPolicy 仅支持 Never 或 OnFailure
- 单个 Pod 时,默认 Pod 成功运行后 Job 即结束
- .spec.completions 标志 Job 结束需要成功运行的 Pod 个数,默认为 1
- .spec.parallelism 标志并行运行的 Pod 的个数,默认为 1
- spec.activeDeadlineSeconds 标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
一个简单的例子:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never2.2 创建Job对象
Job控制器的spec字段内嵌的必要字段只有template,不需要定义标签选择器,控制器会自动关联,除了这一点与Deployment控制器不同,其它别无二致。
1.创建Job控制器配置清单
使用busybox镜像,然后沉睡120s,完成后即正常退出容器。
cat busybox-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: busybox-job
spec:
template:
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "sleep 120s" ]
restartPolicy: NeverPod模版中的spec.restartPolicy默认为"Always",这对Job控制器来说非常不适用,"Never"和"OnFeailure"才比较合适Job控制器。
2.创建Job控制器
kubectl apply -f busybox-job.yaml3.查看Job控制器及Pod状态
kubectl get job -o wide
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
busybox-job 0/1 36s 36s busybox busybox:latest controller-uid=8e85200f-43eb-4f24-ab6d-64c545287d51
kubectl get pods -o wide | grep
busybox busybox-job-wtdvf 1/1 Running 0 45s 10.244.3.150 k8s-node01 <none> <none>120s后,Job控制器创建的Pod对象完成了任务。
kubectl get pods -o wide | grep
busybox busybox-job-wtdvf 0/1 Completed 0 3m38s 10.244.3.150 k8s-node01 <none> <none>4.查看Job控制器的详细信息
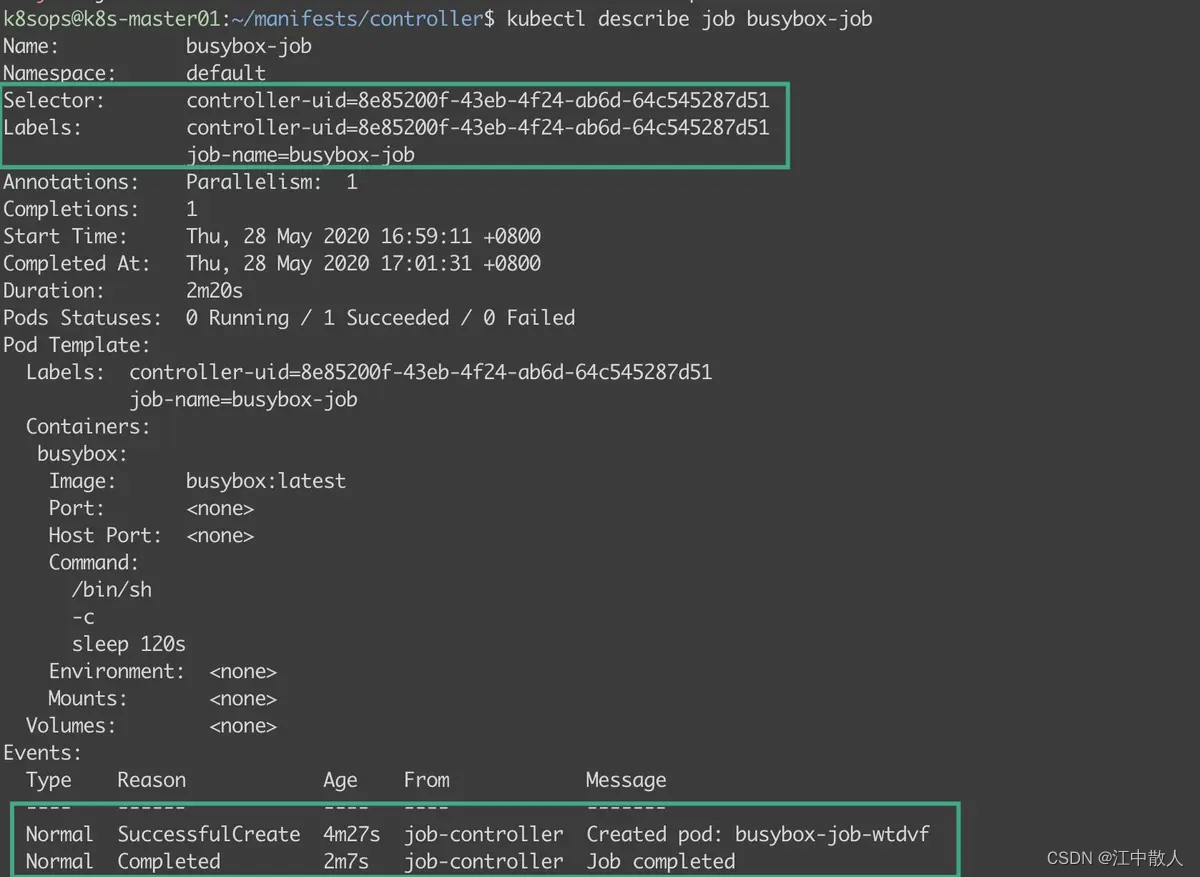
如下Selector与Lables都是Job控制器自动生成后自动关联,控制器自动生成的controller-uid-随机字符串,控制器携带了后面的字符串是为了防止所管理的Pod发生重合。
下面可以看到Job运行成功后及完成了操作并没有进程重启,这得助于我们设置的restartPolicy。
2.3 串行式Job
将并行度属性job.spec.parallelism的值设置为1,并设置总任务数job.spec.completions属性便能够让Job控制器以串行方式运行多任务,下面是一个需要串行5此任务的Job控制器示例:
cat busybox-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: busybox-job
spec:
parallelism: 1
completions: 5
template:
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "sleep 20s" ]
restartPolicy: OnFailure创建Job控制器:
kubectl apply -f busybox-job.yaml动态监控Pod对象作业的变化:
kubectl get pods -l job-name=busybox-job --watch
NAME READY STATUS RESTARTS AGE
busybox-job-q8wqr 0/1 Pending 0 0s
busybox-job-q8wqr 0/1 Pending 0 0s
busybox-job-q8wqr 0/1 ContainerCreating 0 0s
busybox-job-q8wqr 1/1 Running 0 20s
busybox-job-q8wqr 0/1 Completed 0 39s
busybox-job-lppcw 0/1 Pending 0 0s
busybox-job-lppcw 0/1 Pending 0 0s
busybox-job-lppcw 0/1 ContainerCreating 0 0s
busybox-job-lppcw 1/1 Running 0 19s
busybox-job-lppcw 0/1 Completed 0 39s
busybox-job-8jw2q 0/1 Pending 0 0s
busybox-job-8jw2q 0/1 Pending 0 0s
busybox-job-8jw2q 0/1 ContainerCreating 0 0s
busybox-job-8jw2q 1/1 Running 0 19s
busybox-job-8jw2q 0/1 Completed 0 40s
busybox-job-bcxpn 0/1 Pending 0 0s
busybox-job-bcxpn 0/1 Pending 0 0s
busybox-job-bcxpn 0/1 ContainerCreating 0 0s
busybox-job-bcxpn 1/1 Running 0 18s
busybox-job-bcxpn 0/1 Completed 0 38s
busybox-job-5t7xm 0/1 Pending 0 0s
busybox-job-5t7xm 0/1 Pending 0 0s
busybox-job-5t7xm 0/1 ContainerCreating 0 0s
busybox-job-5t7xm 1/1 Running 0 20s
busybox-job-5t7xm 0/1 Completed 0 41s如上,Job控制器需要执行五次任务,每次一个Pod执行一个任务,依次执行,执行成功后的Pod即为完成状态:
kubectl get pods -l job-name=busybox-job
NAME READY STATUS RESTARTS AGE
busybox-job-5t7xm 0/1 Completed 0 4m22s
busybox-job-8jw2q 0/1 Completed 0 5m40s
busybox-job-bcxpn 0/1 Completed 0 5m
busybox-job-lppcw 0/1 Completed 0 6m19s
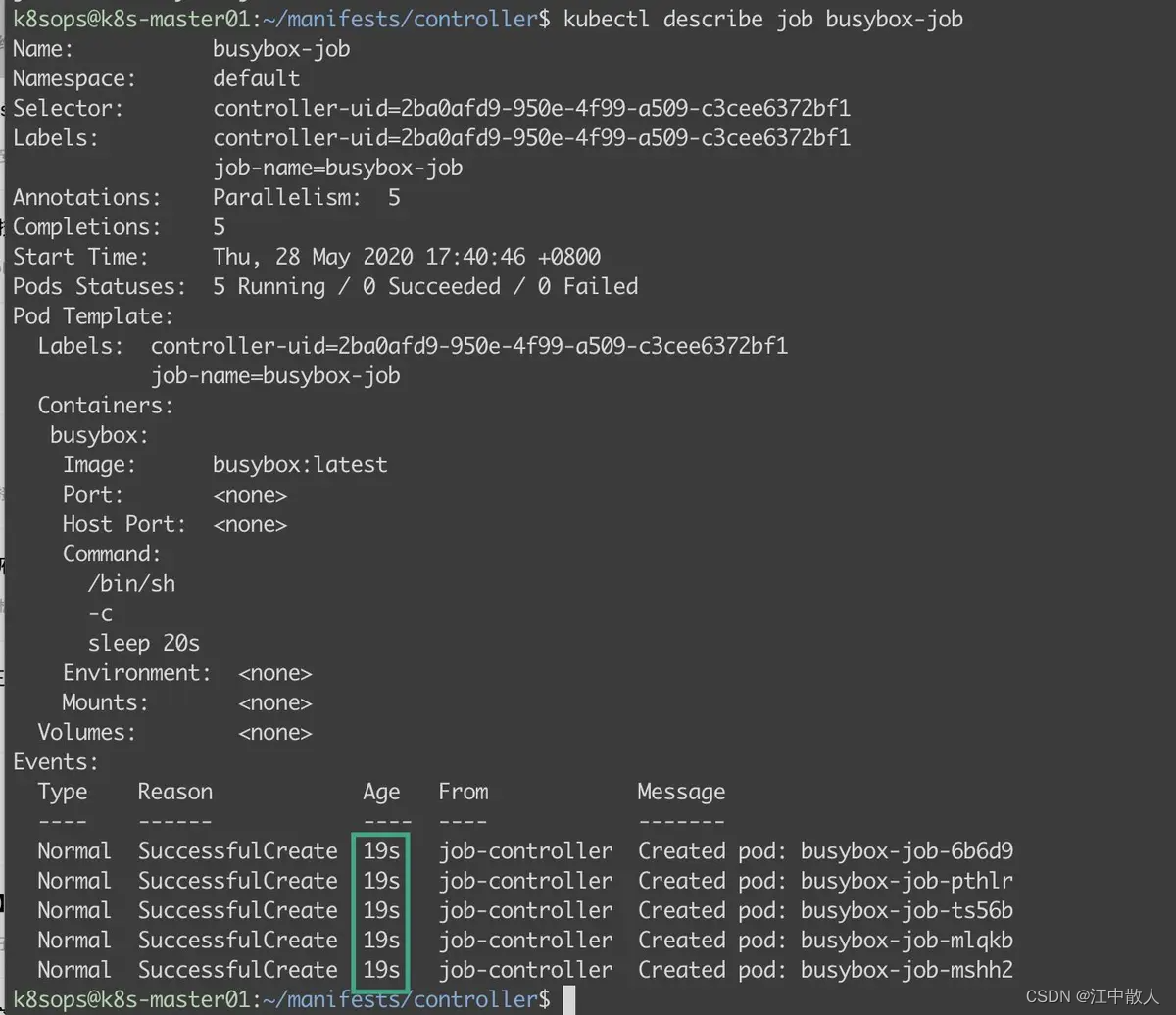
busybox-job-q8wqr 0/1 Completed 0 6m58s2.4 并行式Job
并行式Job我们只需要修改job.spec.parallelism属性与job.spec.completions属性即可:
- job.spec.parallelism属性表示了每次启动多少队列执行作业(即为Pod数量)
- job.spec.completions属性表示了作业的总数量
如下示例一个5个作业,同时启动5个队列进行作业。
cat busybox-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: busybox-job
spec:
parallelism: 5
completions: 5
template:
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "sleep 20s" ]
restartPolicy: OnFailure
kubectl apply -f busybox-job.yaml查看Job控制器运行状态,如下Job控制器中的Pod对象创建时间是一致的。
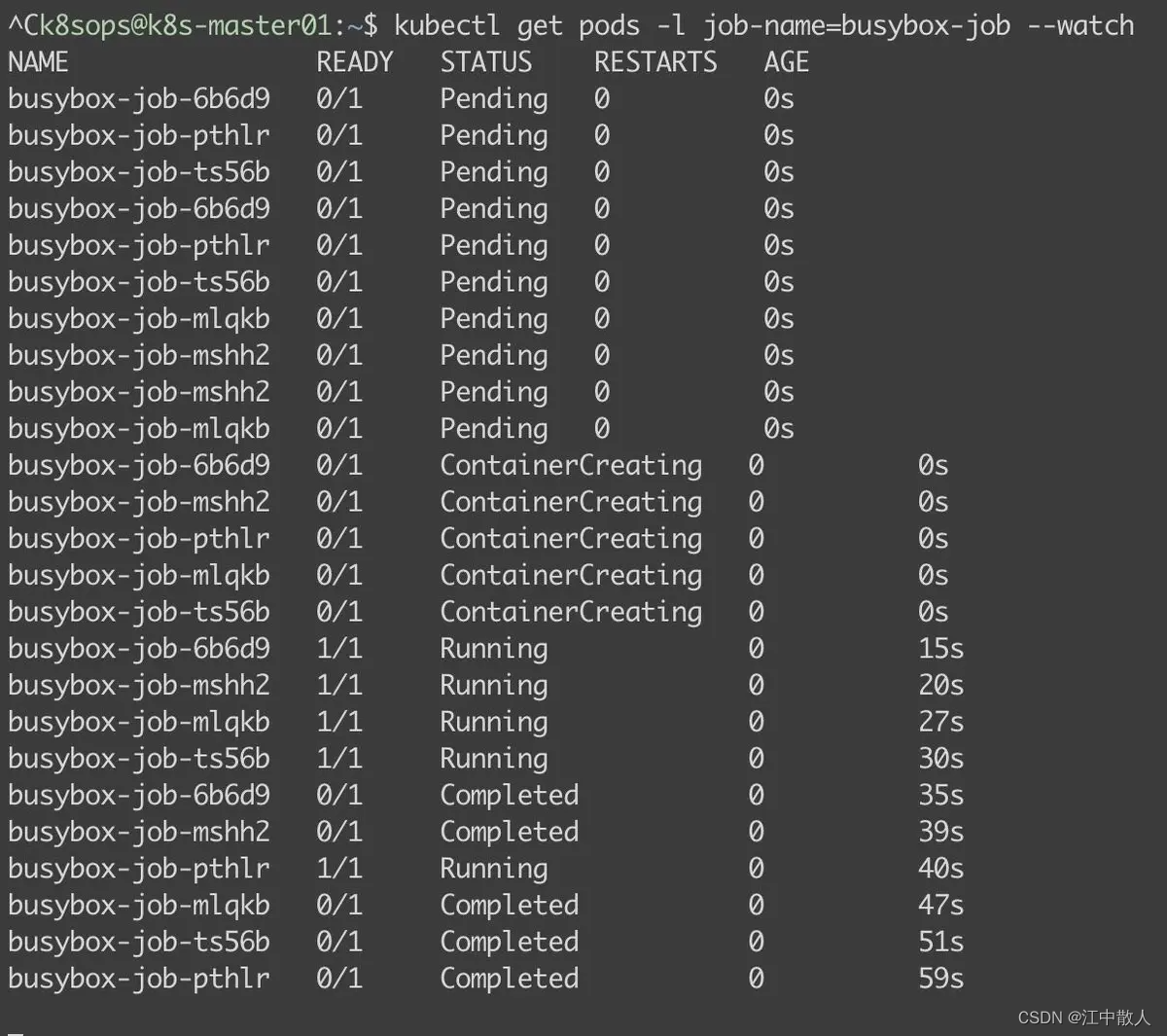
2.5 删除Job
Job控制器中的Pod运行完成后,将不再占用系统资源,用户可以按照需求保留或使用资源删除命令将Pod删除,不过如果某控制器的容器应用总是无法正常结束运行,而其restartPolicy又设置为了重启,则它可能会一直处于不停地重启和错误的循环当中。所幸的是,Job控制器提供了两个属性用于抑制这种情况的发生,具体如下:
- backoffLimit:将作业标记为失败状态之前的重试次数,默认值为6
- activeDeadlineSeconds:Job的deadline,用于为其指定最大活动时间长度,超出此时长的作业将被终止。
例如,下面的配置清单为,表示其失败重试次数为5此,并且如果超出100秒的时间仍然未运行完成,那么则将其终止:
cat busybox-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: busybox-job
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
parallelism: 1
completions: 5
template:
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "sleep 30s" ]
restartPolicy: OnFailure
```3 Job工作机制剖析
3.1 Job机制
Job用来创建1个或多个Pod,并保证指定数量(.spec.completions)的Pod成功完成。当一个Pod成功完成时(.status.phase=Succeeded),Job会记录已完成的Pod的数量,但完成的数量达到指定值时,这个Job就完成了。可以通过以下3种方式来判断一个Job是否已完成:
- .status.completionTime是否为空。Job完成时该字段会被设置成Job完成的时间,否则为空
- .spec.completions和.status.succeeded是否相等,即对比期望完成数和已成功数,当二者相等时,表示Job已经完成
- .status.conditions[0].type:type为Complete和Failed时,分别表示Job执行成功和失败
Pod的中的容器可能因为各种各样的原因失败,比如退出码不为0、超出内存限制被kill掉,容器失败分两种情况:
- .spec.template.spec.restartPolicy = "OnFailure":容器失败后会不断重启,直到成功(退出码为0)
- .spec.template.spec.restartPolicy = "Never":容器不会重启,Pod的状态转为Failed
当Pod执行失败时,Job会不断创建一个新的Pod进行重试,直到失败次数达到.spec.backoffLimit指定的数值,整个Job的执行失败。可以通过判断.status.failed和.spec.backoffLimit是否相等,即已失败数是否已经达到上限,来判断Job是否已经执行失败。如下,当.spec.backoffLimit设置为3时,.status.failed已经达到3,Job失败,不会再尝试创建新的Pod:
kubectl get -n demo jobs j-centos-2020-08-01-15-19-55-w -oyaml |grep status -A 10
status:
conditions:
- lastProbeTime: "2020-08-01T07:21:04Z"
lastTransitionTime: "2020-08-01T07:21:04Z"
message: Job has reached the specified backoff limit
reason: BackoffLimitExceeded
status: "True"
type: Failed
failed: 3
startTime: "2020-08-01T07:19:55Z"如果Pod在执行过程中被意外删除(如使用kubectl delete),Job会重新创建一个新的Pod。
适用场景
Job不是设计用来完成通信密集型的并行程序,如科学计算领域常见的场景。它支持并行地处理一组独立但相关的work item,如发送邮件,渲染帧,转码文件和扫描NoSql数据库中的key。
3.2 Job Controller
Job Controller 负责根据 Job Spec 创建 Pod,并持续监控 Pod 的状态,直至其成功结束。如果失败,则根据 restartPolicy(只支持 OnFailure 和 Never,不支持 Always)决定是否创建新的 Pod 再次重试任务。
参考链接
k8s Job详解_祈晴小义的博客-CSDN博客_k8s的job
kubernetes - 深入K8S Job(一):介绍_个人文章 - SegmentFault 思否
kubernetes Job讲解 - 尘叶心繁的专栏 - TNBLOG
深入K8S Job(二):job controller源码分析 - UCloud云社区


















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











