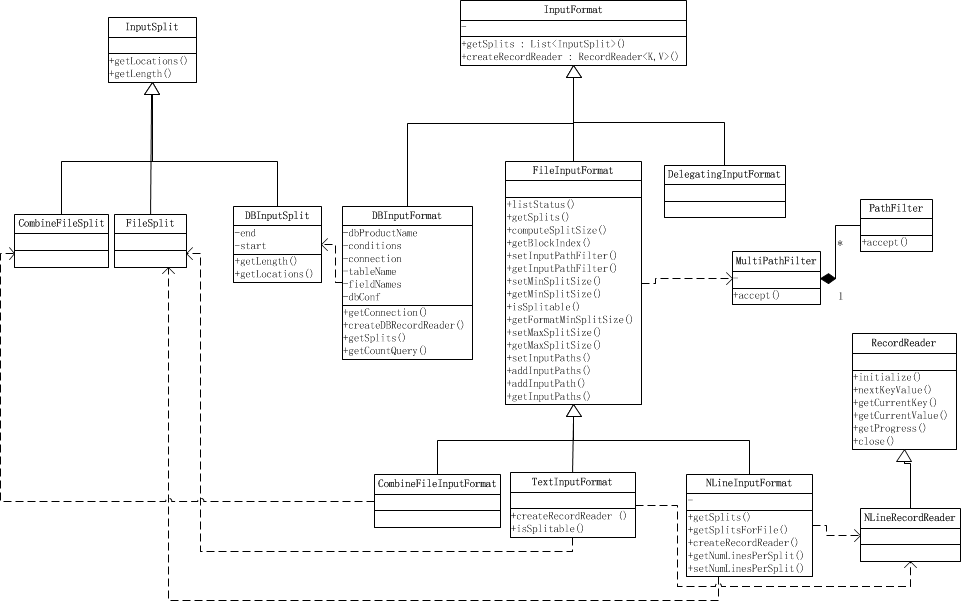
MapReduce作业的输入数据的规格是通过InputFormat类及其子类给出的。有以下几项主要功能:
- 输入数据的有效性检测。
- 将输入数据切分为逻辑块(InputSplit),并把他们分配给对应的Map任务。
- 实例化一个能在每个InputSplit类上工作的RecordReader对象,并以键-值对方式生成数据,这些K-V对将由我们写的Mapper方法处理。
| 派生类 | 说明 |
|---|
| FileInputFormat | 从HDFS中获取输入 |
| DBInputFormat | 从支持SQL的数据库读取数据的特殊类 |
| CombineFileInputFormat | 将对各文件合并到一个分片中 |
其中TextInputFormat是Hadoop默认的输入方法,而这个是继承自FileInputFormat的。之后,每行数据都会生成一条记录,每条记录则表示成
public abstract class InputFormat<K, V> {
/**
* 仅仅是逻辑分片,并没有物理分片,所以每一个分片类似于这样一个元组 <input-file-path, start, offset>
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
/**
* Create a record reader for a given split.
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
FileInputFormat子类
分片方法代码及详细注释如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else {
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
return splits;
}
抽象类InputSplit及其派生类有以下几个主要属性:
- 输入文件名。
- 分片数据在文件中的偏移量。
- 分片数据的长度(以字节为单位)。
- 分片数据所在的节点的位置信息。
在HDFS中,当文件大小少于HDFS的块容量时,每个文件将创建一个InputSplit实例。而对于被分割成多个块的文件,将使用更复杂的公式来计算InputSplit的数量。
基于分片所在位置信息和资源的可用性,调度器将决定在哪个节点为一个分片执行对应的Map任务,然后分片将与执行任务的节点进行通信。
InputSplit源码
public abstract class InputSplit {
/**
* 获取Split的大小,支持根据size对InputSplit排序.
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置.
*/
public abstract
String[] getLocations() throws IOException, InterruptedException;
/**
* 获取分片的存储信息(哪些节点、每个节点怎么存储等)
*/
@Evolving
public SplitLocationInfo[] getLocationInfo() throws IOException {
return null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
FileSplit子类
public class FileSplit extends InputSplit implements Writable {
private Path file;
private long start;
private long length;
private String[] hosts;
private SplitLocationInfo[] hostInfos;
public FileSplit() {}
/**
* Constructs a split with host information
*/
public FileSplit(Path file, long start, long length, String[] hosts) {
this.file = file;
this.start = start;
this.length = length;
this.hosts = hosts;
}
/** Constructs a split with host and cached-blocks information
*
* @param file the file name
* @param start the position of the first byte in the file to process
* @param length the number of bytes in the file to process
* @param hosts the list of hosts containing the block
* @param inMemoryHosts the list of hosts containing the block in memory
*/
public FileSplit(Path file, long start, long length, String[] hosts,
String[] inMemoryHosts) {
this(file, start, length, hosts);
hostInfos = new SplitLocationInfo[hosts.length];
for (int i = 0; i < hosts.length; i++) {
boolean inMemory = false;
for (String inMemoryHost : inMemoryHosts) {
if (inMemoryHost.equals(hosts[i])) {
inMemory = true;
break;
}
}
hostInfos[i] = new SplitLocationInfo(hosts[i], inMemory);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
FileSplit有四个属性:文件路径,分片起始位置,分片长度和存储分片的hosts。用这四项数据,就可以计算出提供给每个Mapper的分片数据。在InputFormat的getSplit()方法中构造分片,分片的四个属性会通过调用FileSplit的Constructor设置。
RecordReader类
RecordReader将读入到Map的数据拆分成K-V对。
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
/**
* 由一个InputSplit初始化
*/
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
/**
* 读取分片下一个<key, value>对
*/
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
/**
* Get the current key
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
/**
* Get the current value.
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
/**
* 跟踪读取分片的进度
*/
public abstract float getProgress() throws IOException, InterruptedException;
/**
* Close the record reader.
*/
public abstract void close() throws IOException;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
通过具体的实现类LineRecordReader,来了解各功能的具体操作:
public class LineRecordReader extends RecordReader<LongWritable, Text> {
public static final String MAX_LINE_LENGTH =
"mapreduce.input.linerecordreader.line.maxlength";
private long start;
private long pos;
private long end;
private SplitLineReader in;
private FSDataInputStream fileIn;
private Seekable filePosition;
private int maxLineLength;
private LongWritable key;
private Text value;
private boolean isCompressedInput;
private Decompressor decompressor;
private byte[] recordDelimiterBytes;
public LineRecordReader() {
}
public LineRecordReader(byte[] recordDelimiter) {
this.recordDelimiterBytes = recordDelimiter;
}
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
}
Map优化
输入过滤
通常,一个作业的输入都需要基于某些属性进行过滤。数据层面的过滤可以在Map里面完成,这种过滤使得Map任务仅需要对感兴趣的文件进行处理,并能减少不必要的文件读取。
PathFilter文件筛选器接口,使用它我们可以控制哪些文件要作为输入,哪些不作为输入。PathFilter有一个accept(Path)方法,当接收的Path要被包含进来,就返回true,否则返回false。
public interface PathFilter {
/**
* Tests whether or not the specified abstract pathname should be
* included in a pathname list.
*
* @param path The abstract pathname to be tested
* @return <code>true</code> if and only if <code>pathname</code>
* should be included
*/
boolean accept(Path path);
}
FileInputFormat类有hiddenFileFilter属性:
private static final PathFilter hiddenFileFilter = new PathFilter(){
public boolean accept(Path p){
String name = p.getName();
return !name.startsWith("_") && !name.startsWith(".");
}
};
Mapper
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public abstract class Context
implements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
/**
* 预处理,仅在map task启动时运行一次
*/
protected void setup(Context context
) throws IOException, InterruptedException {
}
/**
* 对于InputSplit中的每一对<key, value>都会运行一次
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* 扫尾工作,比如关闭流等
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
}
/**
* map task的驱动器
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
Mapper.class中的run()方法,它相当于map task的驱动:
- run()方法首先调用setup()进行初始操作
- 然后循环对每个从context.nextKeyValue()获取的“K-V对”调用map()函数进行处理
- 最后调用cleanup()做最后的处理
Hadoop的“小文件”问题
输入文件明显小于HDFS的块容量时,就会出现“小文件”文件。小文件作为输入处理时,hadoop将为每个文件创建一个Map任务,这将引入很高的任务注册开销。而且每个文件在NameNode中大约占据150字节的内存。
可以采取以下策略处理小文件:分别为:Hadoop Archive,Sequence file和CombineFileInputFormat。
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
使用HAR时需要两点,第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
该方案需人工进行维护,适用管理人员的操作,而且har文件一旦创建,Archives便不可改变,不能应用于多用户的互联网操作。
使用例:
hdfs dfs -mkdir /hw/hdfs/mr/combine/archiveDir
hadoop archive -archiveName pack1.har -p /hw/hdfs/mr/combine awd_2003_12 output/part-m-00000 /hw/hdfs/mr/combine/archiveDir
hdfs dfs -ls -R har:///hw/hdfs/mr/combine/archiveDir/pack1.har
hdfs dfs -ls har:///hw/hdfs/mr/combine/archiveDir/pack1.har/awd_2003_12
hdfs dfs -cat har:///hw/hdfs/mr/combine/archiveDir/pack1.har/output/part-m-00000
SequeceFile是Hadoop API提供的一种二进制文件支持。这种二进制文件直接将K-V对序列化到文件中。一般对小文件可以使用这种文件合并,即将文件名作为key,文件内容作为value序列化到大文件中。这种文件格式有以下好处:
- 支持压缩,且可定制为基于Record或Block压缩(Block级压缩性能较优)
- 本地化任务支持:因为文件可以被切分,因此MapReduce任务时数据的本地化情况应该是非常好的。
- 难度低:因为是Hadoop框架提供的API,业务逻辑侧的修改比较简单。
坏处是需要一个合并文件的过程,且合并后的文件将不方便查看。
该方案对于小文件的存取都比较自由,不限制用户和文件的多少,但是SequenceFile文件不能追加写入,适用于一次性写入大量小文件的操作。
SequenceFile分别提供了读、写、排序的操作类。SequenceFile的操作中有三种处理方式:
- NONE:不压缩数据直接存储
- RECORD:压缩value值不压缩key值存储的存储方式
- BLOCK:key/value值都压缩的方式存储
示例:
public class SequenceFileDemo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hsm01:9000"), conf);
FileStatus[] files = fs.listStatus(new Path(args[0]));
Text key = new Text();
Text value = new Text();
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, new Path(args[1]), key.getClass(), value.getClass());
InputStream in = null;
byte[] buffer = null;
for (FileStatus file : files) {
key.set(file.getPath().getName());
in = fs.open(file.getPath());
buffer = new byte[(int) file.getLen()];
IOUtils.readFully(in, buffer, 0, buffer.length);
value.set(buffer);
IOUtils.closeStream(in);
System.out.println(key.toString() + "\n" + value.toString());
writer.append(key, value);
}
IOUtils.closeStream(writer);
}
}
使用CombineFileInputFormat将对各小文件合并到一个InputSplit中。但由于没有改变NameNode中的文件数量,所以它不能减轻NameNode的内存需求量的压力。
下面演示CombineFileInputFormat将多个小文件合并:
CustomCombineFileInputFormat.Java
/**
* 合并文件,唯一需要重写的是createRecordReader()方法.
* <p>
* 在getSplits()方法中返回一个CombineFileSplit分片对象.每个分片可能合并了来自不同文件的不同块.
* 如果使用setMaxSplitSize()方法设置了分片的最大容量,本地节点的文件将会合并到一个分片,超出分片最大
* 容量的部分将与同一机架的其他主机的块合并.
* 如果没有设置这个最大容量,合并只会在同一机架内进行.
* </p>
*
* Created by zhangws on 16/10/8.
*/
public class CustomCombineFileInputFormat extends CombineFileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split,
TaskAttemptContext context)
throws IOException {
return new CombineFileRecordReader<>((CombineFileSplit) split,
context, CustomCombineFileRecordReader.class);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
CustomCombineFileRecordReader.java
/**
* 从CombineFileSplit中返回记录.
* <p>
* CombineFileSplit与FileSplit之间的不同点在于是否存在包含多个偏移量和长度的多个路径.
*
* 自定义的RecordReader类会被分片中的每个文件调用,因此,自定义RecordReader类的构造函数
* 必须有一个整型变量指明特定的文件正在用于产生记录.
*
* 第二个很重要的方法是nextKeyValue(),它负责产生下一个K-V对,getCurrentKey()与getCurrentValue()
* 方法返回这个K-V对.
* </p>
*
* Created by zhangws on 16/10/8.
*/
public class CombineFileRecordReader extends RecordReader<LongWritable, Text> {
private LongWritable key;
private Text value;
private Path path;
private FileSystem fileSystem;
private LineReader lineReader;
private FSDataInputStream fsDataInputStream;
private Configuration configuration;
private int fileIndex;
private CombineFileSplit combineFileSplit;
private long start;
private long end;
public CombineFileRecordReader(CombineFileSplit combineFileSplit,
TaskAttemptContext taskAttemptContext,
Integer index) throws IOException {
this.fileIndex = index;
this.combineFileSplit = combineFileSplit;
this.configuration = taskAttemptContext.getConfiguration();
this.path = combineFileSplit.getPath(index);
this.fileSystem = this.path.getFileSystem(this.configuration);
this.fsDataInputStream = fileSystem.open(this.path);
this.lineReader = new LineReader(this.fsDataInputStream, this.configuration);
this.start = combineFileSplit.getOffset(index);
this.end = this.start + combineFileSplit.getLength(index);
this.key = new LongWritable(0);
this.value = new Text("");
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int offset = 0;
boolean isKeyValueAvailable = true;
if (this.start < this.end) {
offset = this.lineReader.readLine(this.value);
this.key.set(this.start);
this.start += offset;
}
if (offset == 0) {
this.key.set(0);
this.value.set("");
isKeyValueAvailable = false;
}
return isKeyValueAvailable;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
long splitStart = this.combineFileSplit.getOffset(fileIndex);
if (this.start < this.end) {
return Math.min(1.0f, (this.start - splitStart) /
(float) (this.end - splitStart));
}
return 0;
}
@Override
public void close() throws IOException {
if (lineReader != null) {
lineReader.close();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
CustomPathAndSizeFilter.java(演示过滤器)
/**
* 过滤器: 文件名需要匹配一个特定的正则表达式, 并满足最小文件大小.
* <p>
* 两个要求都有特定的作业参数:
* filter.name
* filter.min.size
* 实现时需要扩展Configured类, 并实现PathFilter接口
* </p>
* <p>
* FileInputFormat.setInputPathFilter(job, CustomPathAndSizeFilter.class);
* </p>
*
* Created by zhangws on 16/10/8.
*/
public class CustomPathAndSizeFilter extends Configured implements PathFilter {
private Configuration configuration;
private Pattern filePattern;
private long filterSize;
private FileSystem fileSystem;
@Override
public boolean accept(Path path) {
boolean isFileAcceptable = true;
try {
if (fileSystem.isDirectory(path)) {
return true;
}
if (filePattern != null) {
Matcher m = filePattern.matcher(path.toString());
isFileAcceptable = m.matches();
}
if (filterSize > 0) {
long actualFileSize = fileSystem.getFileStatus(path).getLen();
if (actualFileSize > this.filterSize) {
isFileAcceptable &= true;
} else {
isFileAcceptable = false;
}
}
} catch (IOException e) {
e.printStackTrace();
}
return isFileAcceptable;
}
@Override
public void setConf(Configuration conf) {
this.configuration = conf;
if (this.configuration != null) {
String filterRegex = this.configuration.get("filter.name");
if (filterRegex != null) {
this.filePattern = Pattern.compile(filterRegex);
}
String filterSizeString = this.configuration.get("filter.min.size");
if (filterSizeString != null) {
this.filterSize = Long.parseLong(filterSizeString);
}
try {
this.fileSystem = FileSystem.get(this.configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
CustomCombineFilesDemo.java
public class CustomCombineFilesDemo {
public static class CombineFilesMapper extends Mapper<LongWritable, Text, LongWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
context.write(key, value);
}
}
public static void main(String[] args)
throws IOException, InterruptedException, ClassNotFoundException {
GenericOptionsParser parser = new GenericOptionsParser(args);
Configuration config = parser.getConfiguration();
String[] remainingArgs = parser.getRemainingArgs();
HdfsUtil.rmr(config, remainingArgs[remainingArgs.length - 1]);
Job job = Job.getInstance(config, CustomCombineFilesDemo.class.getSimpleName());
job.setJarByClass(CustomCombineFilesDemo.class);
job.setMapperClass(CombineFilesMapper.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(CustomCombineFileInputFormat.class);
FileInputFormat.setInputPathFilter(job, CustomPathAndSizeFilter.class);
FileInputFormat.addInputPath(job, new Path(remainingArgs[0]));
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(remainingArgs[1]));
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
运行参数
hadoop jar mr-demo-1.0-SNAPSHOT.jar \
com.zw.mr.combine.CustomCombineFilesDemo -D filter.name=.*.txt -D filter.min.size=2014 /hw/hdfs/mr/combine/awd_2003_12 /hw/hdfs/mr/combine/output
结果
13:28:35,188 | INFO | main | FileInputFormat | reduce.lib.input.FileInputFormat 281 | Total input paths to process : 9
13:28:35,202 | INFO | main | CombineFileInputFormat | lib.input.CombineFileInputFormat 413 | DEBUG: Terminated node allocation with : CompletedNodes: 2, size left: 26112
13:28:35,238 | INFO | main | JobSubmitter | he.hadoop.mapreduce.JobSubmitter 199 | number
Shuffle优化
dfs.blocksize属性
HDFS文件的块默认容量可以被配置文件(hdfs-site.xml)覆盖。某些情况下,Map任务可能只需要几秒时间就可以处理一个块,所以,最好让Map任务处理更大的块容量。通过以下方法达到此目的:
- 增加参数mapreduce.input.fileinputformat.split.minsize,使其大于块容量;
- 增加文件存储在HDFS中的块容量。
前者导致数据本地化问题,例如InputSplit可能会包含其他主机的块;后者能够维持数据都在本地节点,但要求重新加载HDFS中的文件。例如文件tiny.data.txt以块容量512MB的方式上传HDFS中:
hdfs dfs -D dfs.blocksize=536870912 -put province.txt /hw/hdfs/mr/task
由于CPU的约束,有时可以减少fileinputformat.split.minsize属性值,使它小于HDFS的块容量,从而提高资源的利用率。
中间输出结果的排序与溢出
![]()
![]()
- Map任务的中间输出使用环形缓冲区缓存在本地内存(大小通过mapreduce.task.io.sort.mb设置,默认100M)。被缓冲的K-V对记录已经被序列化,但没有排序。而且每个K-V对都附带一些额外的审计信息。
- 使用率有一个软阈值(mapreduce.map.sort.spill.percent,默认0.80),当超过阈值时,溢出行为会在一个后台线程执行。Map任务不会因为缓存溢出而被阻塞。但如果达到硬限制,Map任务会被阻塞,直到溢出行为结束。
- 线程会将记录基于键进行分区(通过 mapreduce.job.partitioner.class设置分区算法的类),在内存中将每个分区的记录按键排序(通过map.sort.class指定排序算法,默认快速排序org.apache.hadoop.util.QuickSort),然后写入一个文件。每次溢出,都有一个独立的文件存储。
- Map任务完成后,缓存溢出的各个文件会按键排序后合并到一个输出文件(通过mapreduce.cluster.local.dir指定输出目录,值为${hadoop.tmp.dir}/mapred/local)。合并文件的流的数量通过mapreduce.task.io.sort.factor指定,默认10,即同时打开10个文件执行合并。
根据上面步骤,最好仅在Map任务结束的时候才能缓存写到磁盘中。
可以采用以下方法提高排序和缓存写入磁盘的效率:
- 调整mapreduce.task.io.sort.mb大小,从而避免或减少缓存溢出的数量。当调整这个参数时,最好同时检测Map任务的JVM的堆大小,并必要的时候增加堆空间。
- mapreduce.task.io.sort.factor属性的值提高100倍左右,这可以使合并处理更快,并减少磁盘的访问。
- 为K-V提供一个更高效的自定义序列化工具,序列化后的数据占用空间越少,缓存使用率就越高。
- 提供更高效的Combiner(合并器),使Map任务的输出结果聚合效率更高。
- 提供更高效的键比较器和值的分组比较器。
本地Reducer和Combiner
Combiner在本地节点将每个Map任务输出的中间结果做本地聚合,即本地Reducer,它可以减少传递给Reducer的数据量。可以通过setCombinerClass()方法来指定一个作业的combiner。
mapreduce.map.Java.opts参数设置Map任务JVM的堆空间大小,默认-Xmx1024m
如果指定了Combiner,可能在两个地方被调用。
- 当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
- 缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用Combiner。
获取中间输出结果(Map侧)
Reducer需要通过网络获取Map任务的输出结果,然后才能执行Reduce任务,可以通过下述Map侧的优化来减轻网络负载:
- 通过压缩输出结果,mapreduce.map.output.compress设置为true(默认false),mapreduce.map.output.compress.codec指定压缩方式。
- Reduce任务是通过HTTP协议获取输出分片的,可以使用mapreduce.tasktracker.http.threads指定执行线程数(默认40)
Reduce优化
Reduce任务
Reduce任务是一个数据聚合的步骤。数量默认为1,而使用过多的Reduce任务则意味着复杂的shuffle,并使输出文件的数量激增。mapreduce.job.reduces属性设置reduce数量,也可以通过编程的方式,调用Job对象的setNumReduceTasks()方法来设置。一个节点Reduce任务数量上限由mapreduce.tasktracker.reduce.tasks.maximum设置(默认2)。
可以采用以下探试法来决定Reduce任务的合理数量:
# 每个reducer都可以在Map任务完成后立即执行
0.95 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)
另一个方法是
# 较快的节点在完成第一个Reduce任务后,马上执行第二个
1.75 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)
获取中间输出结果(Reduce侧)
Reduce任务在结束时都会获取Map任务相应的分区数据,这个过程叫复制阶段(copy phase)。一个Reduce任务并行多少个Map任务是由mapreduce.reduce.shuffle.parallelcopies参数决定(默认5)。
由于网络问题,Reduce任务无法获取数据时,会以指数退让(exponential backoff)的方式重试,超时时间由mapreduce.reduce.shuffle.connect.timeout设置(默认180000,单位毫秒),超时之后,Reduce任务标记为失败状态
中间输出结果的合并与溢出
![]()
Reduce任务也需要对多个Map任务的输出结果进行合并,过程如上图,根据Map任务的输出数据的大小,可能将其复制到内存或磁盘。mapreduce.reduce.shuffle.input.buffer.percent属性配置了这个任务占用的缓存空间在堆栈空间中的占用比例(默认0.70)。
mapreduce.reduce.shuffle.merge.percent决定缓存溢出到磁盘的阈值(默认0.66),mapreduce.reduce.merge.inmem.threshold设置了Map任务在缓存溢出前能够保留在内存中的输出个数的阈值(默认1000),只要一个满足,输出数据都将会写到磁盘。
在收到Map任务输出数据后,Reduce任务进入合并(merge)或排序(sort)阶段。同时合并的文件流的数量由mapreduce.task.io.sort.factor属性决定(默认10)。
Map任务输出数据的所有压缩操作,在合并时都会在内存中进行解压缩操作。
MapReduce的输出
输出依赖于作业中Reduce任务的数量,下面是一些优化建议:
- 压缩输出,以节省存储空间,同时也提升HDFS写入吞吐量;
- 避免写入带外端文件(out-of-band side file)作为Reduce任务的输出。
- 根据作业输出文件的消费者的需求,可以分割的压缩技术或许适合;
- 以较大块容量设置,写入较大的HDFS文件,有助于减少Map任务数。
任务的推测执行
Straggle(掉队者)是指那些跑的很慢但最终会成功完成的任务。一个掉队的Map任务会阻止Reduce任务开始执行。
Hadoop不能自动纠正掉队任务,但是可以识别那些跑的比较慢的任务,然后它会产生另一个等效的任务作为备份,并使用首先完成的那个任务的结果,此时另外一个任务则会被要求停止执行。这种技术称为推测执行(speculative execution)。
默认使用推测执行。
| 属性 | 描述 |
|---|
| mapreduce.map.speculative | 控制Map任务的推测执行(默认true) |
| mapreduce.reduce.speculative | 控制Reduce任务的推测执行(默认true) |
| mapreduce.job.speculative.speculativecap | 推测执行功能的任务能够占总任务数量的比例(默认0.1,范围0~1) |
| mapreduce.job.speculative.slownodethreshold | 判断某个TaskTracker是否适合启动某个task的speculative task(默认1) |
| mapreduce.job.speculative.slowtaskthreshold | 判断某个task是否可以启动speculative task(默认1) |
MapReduce作业的计数器
计数器是在作业层面收集统计信息,帮助我们对MapReduce作业进行质量控制、性能监控和问题识别。和日志不同,它们生来就是全局的,因此不需要进行聚合操作就可以执行分析操作。
因为是在分布式环境中的全局变量,所以必须慎重使用。否则集群跟踪时负载太大。
示例:
package com.zw.mr.counter
import com.zw.util.HdfsUtil
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.Mapper
import org.apache.hadoop.mapreduce.Reducer
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
import org.apache.hadoop.util.GenericOptionsParser
import java.io.IOException
import java.util.StringTokenizer
public class CounterDemo {
public static enum WORDS_IN_LINE_COUNTER {
ZERO_WORDS,
LESS_THAN_FIVE_WORDS,
MORE_THAN_FIVE_WORDS
}
public static class CounterMapper extends Mapper<LongWritable, Text,
Text, IntWritable> {
private IntWritable countOfWords = new IntWritable(0)
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString())
int words = tokenizer.countTokens()
if (words == 0) {
context.getCounter(WORDS_IN_LINE_COUNTER.ZERO_WORDS).increment(1)
} else if (words > 0 && words <= 5) {
context.getCounter(WORDS_IN_LINE_COUNTER.LESS_THAN_FIVE_WORDS).increment(1)
} else {
context.getCounter(WORDS_IN_LINE_COUNTER.MORE_THAN_FIVE_WORDS)
}
while(tokenizer.hasMoreTokens()) {
String target = tokenizer.nextToken()
context.write(new Text(target), new IntWritable(1))
}
}
}
public static class CounterReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0
for (IntWritable v : values) {
count += v.get()
}
//输出key
context.write(key, new IntWritable(count))
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration()
String[] values = new GenericOptionsParser(conf, args).getRemainingArgs()
if (values.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>")
System.exit(2)
}
//先删除output目录
HdfsUtil.rmr(conf, values[values.length - 1])
Job job = Job.getInstance(conf, CounterDemo.class.getSimpleName())
job.setJarByClass(CounterDemo.class)
job.setMapperClass(CounterMapper.class)
job.setReducerClass(CounterReducer.class)
job.setOutputKeyClass(Text.class)
job.setOutputValueClass(IntWritable.class)
FileInputFormat.addInputPath(job, new Path(values[0]))
FileOutputFormat.setOutputPath(job, new Path(values[1]))
if (job.waitForCompletion(true)) {
HdfsUtil.cat(conf, values[1] + "/part-r-00000")
System.out.println("success")
} else {
System.out.println("fail")
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
输入数据文件
xxx xxxx
hadoop spark
storm hadoop
storm storm storm storm storm storm
stop stop stop stop stop stop stop
输出结果
File System Counters
FILE: Number of bytes read=792
FILE: Number of bytes written=510734
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=214
HDFS: Number of bytes written=45
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Map-Reduce Framework
Map input records=6
Map output records=19
Map output bytes=182
Map output materialized bytes=226
Input split bytes=104
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=226
Reduce input records=19
Reduce output records=6
Spilled Records=38
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=2
Total committed heap usage (bytes)=391118848
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
com.zw.mr.counter.CounterDemo$WORDS_IN_LINE_COUNTER
LESS_THAN_FIVE_WORDS=3
MORE_THAN_FIVE_WORDS=0
ZERO_WORDS=1
File Input Format Counters
Bytes Read=107
File Output Format Counters
Bytes Written=45
hadoop 2
spark 1
stop 7
storm 7
xxx 1
xxxx 1
MapReduce学习笔记之数据连接
Map侧连接
Map端join是指数据到达map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
注意:在Map端join操作中,我们往往将较小的表添加到内存中,因为内存的资源是很宝贵的,这也说明了另外一个问题,那就是如果表的数据量都非常大则不适合使用Map端join。
1.1 基本思路
- 需要join的两个文件,一个存储在HDFS中,一个在作业提交前,使用Job.addCacheFile(URI uri)将需要join的另外一个文件加入到所有Map缓存中;
- 在Mapper.setup(Context context)函数里读取该文件;
- 在Mapper.map(KEYIN key, VALUEIN value, Context context)进行join;
- 将结果输出(即没有Reduce任务)。
1.2 示例
public class ProvinceMapJoinStatistics {
public static class ProvinceLeftJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private String provinceWithProduct = "";
/**
* 加载缓存文件
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] uri = context.getCacheFiles();
if (uri == null || uri.length == 0) {
return;
}
for (URI p : uri) {
if (p.toString().endsWith("part-r-00000")) {
try {
provinceWithProduct = HdfsUtil.read(new Configuration(), p.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (!provinceWithProduct.contains(value.toString()
.substring(0, 2))) {
context.write(value, NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 3) {
System.err.println("Usage: <in> [<in>...] <out>");
System.exit(2);
}
HdfsUtil.rmr(conf, otherArgs[otherArgs.length - 1]);
Job job = Job.getInstance(conf, "ProvinceMapJoinStatistics");
job.setJarByClass(ProvinceMapJoinStatistics.class);
job.addCacheFile(new Path(args[1]).toUri());
job.setMapperClass(ProvinceLeftJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
if (job.waitForCompletion(true)) {
HdfsUtil.cat(conf, otherArgs[2] + "/part-r-00000");
System.out.println("success");
} else {
System.out.println("fail");
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
2. Reduce侧连接
Reduce端连接比Map端连接更为普遍,因为输入的数据不需要特定的结构,但是效率比较低,因为所有数据都必须经过Shuffle过程。
2.1 基本思路
- Map端读取所有的文件,并在输出的内容里加上标示,代表数据是从哪个文件里来的。
- 在reduce处理函数中,按照标识对数据进行处理。
- 然后根据Key去join来求出结果直接输出。
2.2 示例
public class ReduceJoinDemo {
public static class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
if (line == null || line.equals("")) {
return;
}
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String path = fileSplit.getPath().toString();
if (path.contains("province.txt")) {
context.write(new Text(line.substring(0, 2)), new Text("a#" + line));
} else if (path.contains("part-r-00000")) {
context.write(new Text(line.substring(0, 2)), new Text("b#"));
}
}
}
public static class ReduceJoinReducer extends Reducer<Text, Text, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int count = 0;
String province = "";
for (Text value : values) {
count++;
String str = value.toString();
if (str.startsWith("a#")) {
province = str.substring(2);
}
}
if (count == 1) {
context.write(new Text(province), NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 3) {
System.err.println("Usage: <in> [<in>...] <out>");
System.exit(2);
}
HdfsUtil.rmr(conf, otherArgs[otherArgs.length - 1]);
Job job = Job.getInstance(conf, ReduceJoinDemo.class.getSimpleName());
job.setJarByClass(ReduceJoinDemo.class);
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(otherArgs[0]), new Path(otherArgs[1]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
if (job.waitForCompletion(true)) {
HdfsUtil.cat(conf, otherArgs[2] + "/part-r-00000");
System.out.println("success");
} else {
System.out.println("fail");
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
3. SemiJoin
SemiJoin就是所谓的半连接,其实仔细一看就是reduce join的一个变种,就是在map端过滤掉一些数据,在网络中只传输参与连接的数据不参与连接的数据不必在网络中进行传输,从而减少了shuffle的网络传输量,使整体效率得到提高,其他思想和reduce join是一模一样的。说得更加接地气一点就是将小表中参与join的key单独抽出来通过DistributedCach分发到相关节点,然后将其取出放到内存中(可以放到HashSet中),在map阶段扫描连接表,将join key不在内存HashSet中的记录过滤掉,让那些参与join的记录通过shuffle传输到reduce端进行join操作,其他的和reduce join都是一样的。
























 2615
2615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









