






分布式编译相关技术分析
Remote Execution API
简介
Remote Execution API定义了一种分布式构建解决方案的标准化方法,使用ProtoBuf 定义消息内容,使用gRPC进行远程过程调用,允许客户端的编译命令发送至远程系统上执行。 Remote Execution API 主要为分布式构建系统而设计的API,例如Bazel,通过分发构建和测试任务由远程执行,并提供构建结果的缓存服务。这允许构建更快地执行,既可以重用其他客户端已经构建的结果,还并行执行构建任务,从而大大加快构建速度。
Remote Execution API的核心是摘要消息Digest,通过摘要消息来引用Action的依赖项和输出结果,摘要消息的定义如下。
message Digest {
// The hash. In the case of SHA-256, it will always be a lowercase hex string
// exactly 64 characters long.
string hash = 1;
// The size of the blob, in bytes.
int64 size_bytes = 2;
}
主要服务
Capabilities Server
远程执行客户端可以使用 Capabilities 服务来查询各种服务器属性,以便自行配置或返回有意义的错误消息。
包含的方法:
-
GetCapabilities()返回远程服务器功能配置。
参数:GetCapabilitiesRequest,包括服务器实例信息。
返回值:ServerCapabilities,包括远程缓存能力,远程执行能力,支持的版本,支持的哈希算法。
Action Cache Service
ActionCache 服务负责将 Action 映射到描述其过去执行的 ActionResult,用于查询给定Action 是否已经执行。
在远程执行完成后,服务端会返回ActionResult,但不会直接返回output本身内容,客户端按需从CAS中获取。
客户端应该在向远程执行服务器发送一个Action之前,使用带有该Action摘要的 GetActionResult() 调用,如果该Action已经执行,则可以直接获取结果而无需进行任何计算。
包含的方法:
-
GetActionResult(): 检索缓存的执行结果。
参数:GetActionResultRequest,包括服务器实例信息,Action的摘要。
返回值:ActionResult,包括Action输出文件,命令退出代码,stdout及对应的摘要,stderr及对应的摘要。
-
UpdateActionResult():上传新的执行结果。
参数:UpdateActionResultRequest,包括服务器实例信息,Action的摘要,上传的ActionResult。
返回值:ActionResult:上传的ActionResult。
Content Addressable Storage Service
ContentAddressableStorage 服务用于存储操作的输入和输出文件。 内容可寻址存储(简称CAS)是通过其哈希寻址内容的存储层,这使得为内容生成唯一密钥变得容易,也确保内容不会意外上传错误的密钥,因为 CAS 将拒绝未正确散列的内容。
CAS 是远程执行/分布式构建架构的关键元素,并在不同组件之间共享。 它本质上是一个存储任意二进制数据的数据库。每个条目,一个二进制 blob,都由一个 Digest 索引:一个包含数据散列的值(通常是 SHA-256)及其大小(以字节为单位)。 虽然单独的哈希足以唯一地标识一个 blob,但具有大小允许实现轻松预测服务特定请求所需的资源。
CAS 支持两种基本操作:创建新条目和获取现有条目。 对于后者,有必要知道要获取的 blob 的哈希值,因此它被称为内容可寻址。 在整个 REAPI 中都使用摘要来引用特定的数据。
由于对实际内容没有限制,CAS服务器不仅可以存储源文件和结果,还可以作为Remote Execution API的protobuf消息的缓存。 (例如,表示树结构的目录消息与其中包含的文件一起存储。)因此,将 CAS 中的条目称为 blob 而不是文件。
包含方法:
-
BatchUpdateBlobs():一次上传多个 blob。
参数:BatchUpdateBlobsRequest,包括摘要信息,二进制数据,编码格式,服务器实例信息。
返回值:BatchUpdateBlobsResponse,包括摘要信息,状态。
-
BatchReadBlobs():一次下载多个blob。
参数:BatchReadBlobsRequest,包括服务器实例信息,摘要信息。
返回值:BatchReadBlobsResponse,包括摘要信息,二进制数据,编码格式,状态。
-
FindMissingBlobs():给定摘要列表,返回 CAS 中不存在的摘要,使客户端避免不必要的传输。
参数:FindMissingBlobsRequest,包括服务器实例信息,给定的摘要列表。
返回值:FindMissingBlobsResponse ,包括不存在CAS中的摘要列表。
-
GetTree():获取以节点为根的整个目录树。
参数:GetTreeRequest,包括服务器实例信息,输入根的摘要。
返回值:GetTreeResponse,包括输入根对应的整个目录。
Execution Service
在向远程执行服务器提交请求之前,构建客户端首先需要确保所有输入文件在 CAS 中都可用,远程执行服务器和最终将接手任务的worker将能够访问他们。
一旦所需的blob全部就绪,客户端发送需要执行的Action。
Action包括根目录的摘要,待执行Command的摘要。
Commmand包括要执行的命令的名称及其参数, 环境变量列表,预期作为输出生成的文件和目录的列表。
包含的方法:
-
Execute():远程执行Action。
参数:ExecuteRequest,包括服务器实例信息,需要执行的Action摘要。
返回值:stream google.longrunning.Operation。
-
WaitExecution():等待执行操作完成。服务器将保持请求流打开,直到操作完成,然后以完成的操作进行响应,期间提供执行状态的更新。
参数:stream google.longrunning.Operation。
返回值:stream google.longrunning.Operation。
文件目录树
文件目录树(File Directory Tree),也叫文件系统目录结构(File System Directory Structure),是计算机文件系统中文件和目录的层次结构的一种表现形式,本系统使用默克尔树描述文件目录。
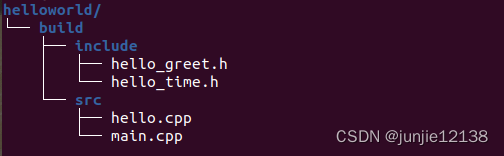
默克尔树是Remote Execution API的核心,用来描述一个编译任务所依赖的输入文件及其目录结构。如下图所示,树的根节点包含了两个哈希值,分别代表了main和external目录,main节点又包含了一个指向test.cc源文件的哈希,external节点包含了另一个目录,文件和目录共同构成了一颗完整的默克尔树。树的叶子节点是编译任务依赖的所有输入文件,其哈希值是根据文件内容计算而得,树的非叶子节点是目录结构,其哈希值是根据路径计算而得。这样的设计目的有两个:① 便于及时发现文件的变化,一旦修改了某个输入文件,整个树的哈希值就会产生变化,也就无法命中缓存,即该任务需要重新编译。② 使用默克尔树的结构能方便在worker端还原出完整的输入目录,在发送任务的时候只要在请求中携带树的根节点,而不是发送整个目录。worker只要获取树的根节点,再根据其携带的哈希值从缓存中获取对应的blob文件构造下层目录,最后根据叶子节点的哈希值从缓存中获取输入文件。
在每个编译任务执行前,客户端需要将整个默克尔树及叶子节点对应的文件进行上传,不同编译任务可能依赖相同的输入文件,只要服务端缓存中包含了对应的哈希值,就不必重复上传,编译节点可直接从缓存中获取依赖的文件,这样可以实现跨任务的输入文件资源共享。BuildBuddy判断缓存命中的依据即是文件目录树各节点的哈希值。
分布式任务调度
分布式任务调度策略基于Sparrow,Sparrow是一个去中心化的无状态的分布式调度器,主要使用批量采样和延迟绑定的策略。
分布式任务调度的核心思想是将任务调度的决策推迟到执行时刻。与传统的集中式调度算法不同,其将任务分配给可用的计算节点,然后在节点上进行本地决策,以避免调度器成为性能瓶颈。这种分散的决策方式能够减少调度器的负载,并允许系统更快地响应和适应不同的任务负载。
批量采样
调度器根据编译命令中携带的客户端平台信息计算相匹配的节点类型,并从资源池中选取若干节点备用,默认会随机选取三个编译节点,如果没有对应平台的编译节点供使用则结束调度。
延迟绑定
主要用来确定具体执行任务的编译节点,因为无法单纯地从各个节点队列中的任务数量来判断执行时间长短,因此任何一个节点收到来自调度器的探测请求后,都会在任务队列中预留一个位置,哪个节点最先执行到预留的任务,就向调度器发送领取请求,表示领取这个任务进行执行。
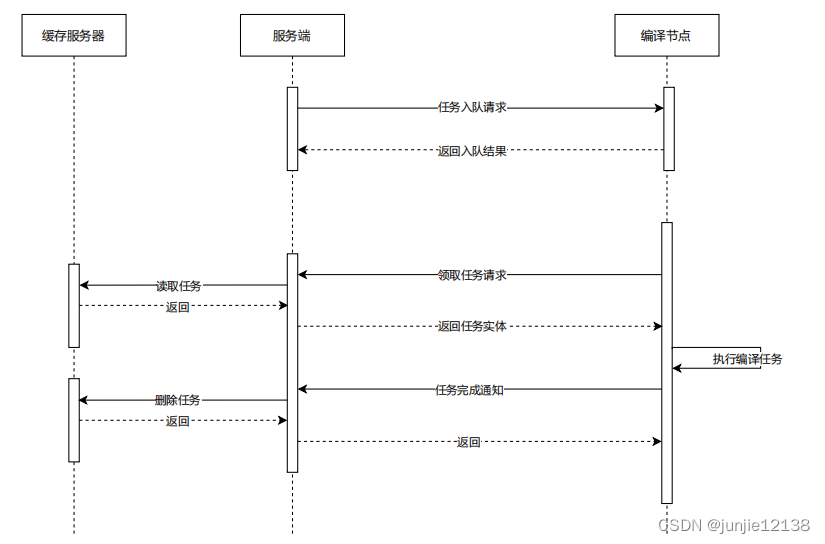
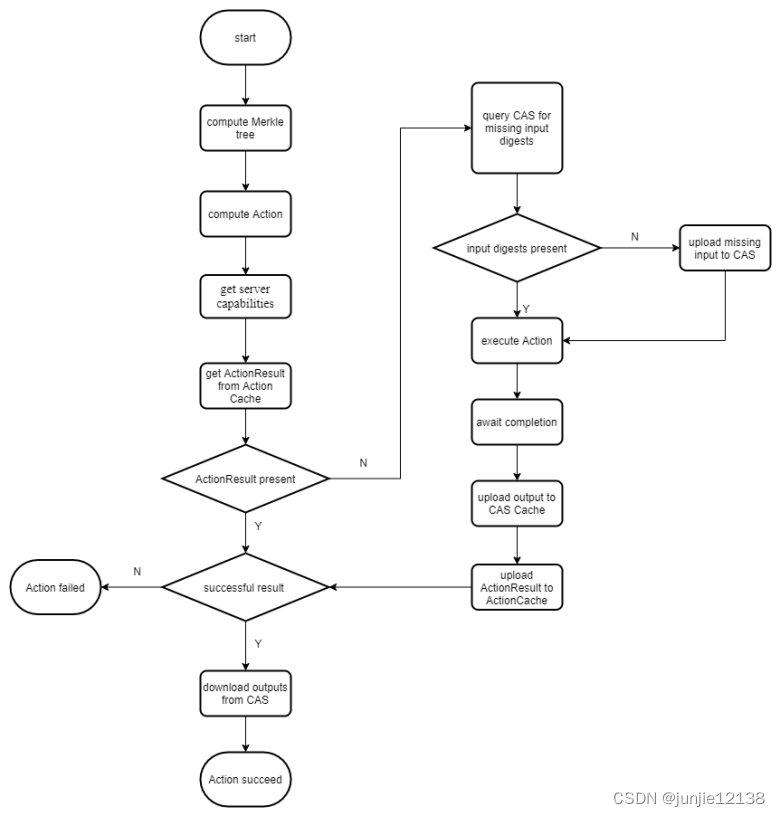
分布式编译执行流程
在分布式编译执行开始前,客户端需要根据输入文件及其目录构造出默克尔树,同时将树根哈希值和命令哈希值打包成一个Action,然后,客户端需要获取服务端信息,如果服务端具备远程执行功能,则进入执行流程。客户端根据Action的input_digest从ActionCache中寻找ActionResult,如果这个Action之前执行过,且ActionResult执行结果正确,则直接返回ActionResult,客户端拿到了执行结果的哈希值,可根据此哈希从CAS Cache中获取输出文件,执行流程结束。如果这个Action是首次执行,则返回结果为空,客户端需要上传执行Action所需的所有输入文件,在上传前从CAS Cache中查询已经存在的输入文件,只需要上传缺失的部分。等到所有文件上传完毕,就开始执行Action,等到执行结束后,将执行输出文件上传到CAS Cache,将执行结果ActionResult上传到ActionCache。















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









