



1. ES基础
es中文档是以json格式存储的,对于每个json字段都有自己的倒排索引,当然也可以指定某个字段不做索引,这样可以节省空间,但缺点就是无法被搜索了。
倒排索引与正排索引的区别
- 正排索引:代表Mysql,通过文档id来关联到对应的内容
- 倒排索引:代表Es,通过内容来关联到对应的文档id
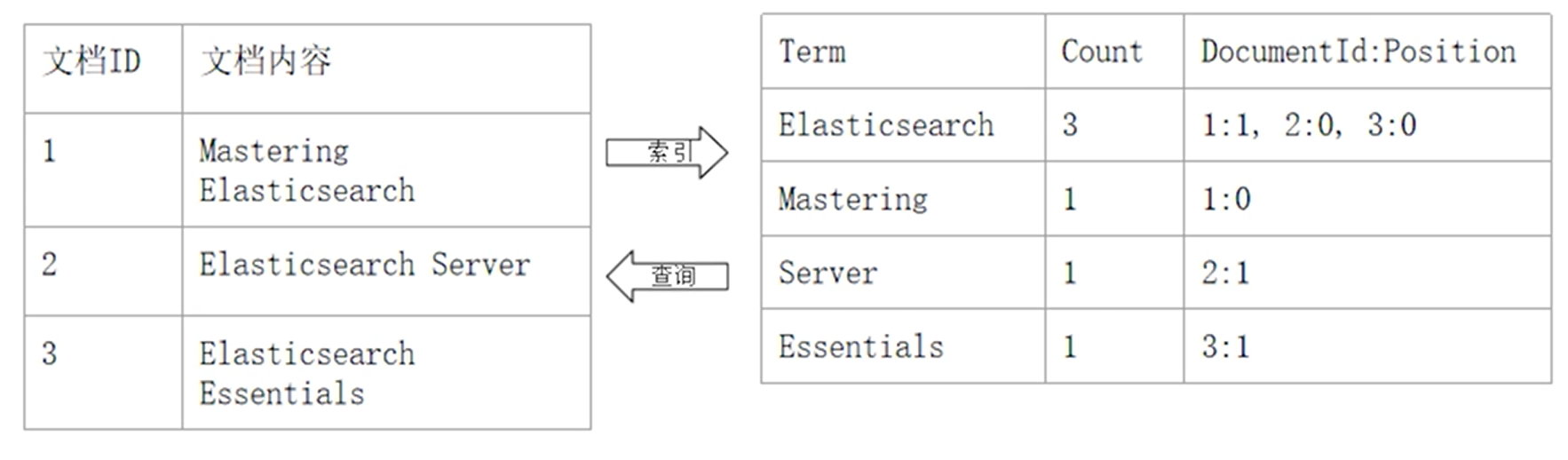
倒排索引组成
其有两部分组成,单词词典和倒排索引列表
- 单词词典:记录了所有文档的单词,并且也记录了单词与倒排列表的关联关系,其一般比较大,可以用B+树或哈希拉链实现,可以满足其高性能的查询和插入
- 倒排列表:记录了单词对应的文档结合,由倒排索引项组成
倒排索引项包含以下几个:
- 文档id
- 词频:记录单词出现的次数,用于相关性评分
- 位置:记录单词在文档中分词的位置,用于语句搜索
- 偏移:记录单词开始与结束位置,实现高亮显示
索引注意项
- 索引名称必须全部小写,不能有大写
相关性算分
搜索的相关性算法描述了 查询与 文档的匹配程度, ES 5.0 之前采用的
TF-IDF算法用来计算相关性算分,之后采用的BM25算法
在查询中可以加入 explain 参数,可以查看是如何打分的
GET user/_search
{
"explain": true
"query": {
"match": {"desc": "我爱滑雪"}
}
}
TF-IDF
其本质就是将 TF 求和 变成了 加权求和, 计算公式: TF(词1)*IDF(词1) + TF(词2)*IDF(词2)
- TF: 词频(词在文档中出现的频率),计算公式:词出现的次数 / 文档的总字数
- IDF:逆文档频率,计算公式:log(全部文档数 / 检索到的文档数)
- TF-IDF: TF * IDF
举例
比如搜索 区块链的应用,会将其分成3个词,区块链,的,应用
假如总文档数为 1000 ,区块链出现的文档数为200 ,的 为 1000,应用为500,那么他们的 IDF 值为
- 区块链:log(1000/200) = log(5) = 0.69
- 的:log(1000/1000) = log(1) = 0
- 应用:log(1000/500) = log(2) = 0.30
那么 TF-IDF值就为: TF(区块链)*0.69 + TF(的)*0 + TF(应用)*0.30
BM25
TF-IDF 算法有个明显的缺点,当一个词的 TF 无限增加时,其算分也会无限增加,而 BM25 则是会趋于一个固定值。BM是Best Match的缩写,25是指经过25次迭代调整之后得出的算法
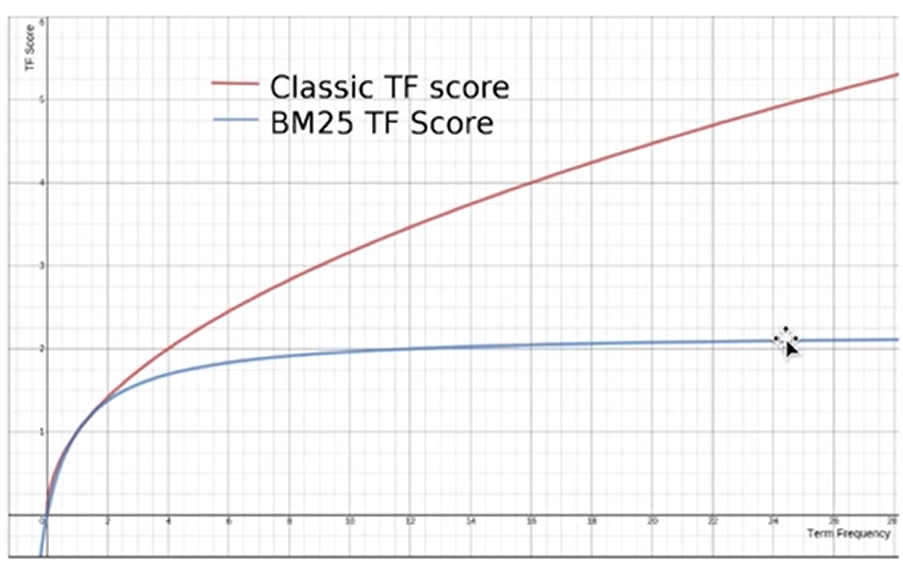
BM25计算公式
查询集群是否健康
GET /_cluster/health
返回信息
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
主要关注 status 字段
green: 所有的主分片和副本分片都正常运行。yellow. : 所有的主分片都正常运行,但不是所有的副本分片都正常运行。red: 有主分片没能正常运行。
分片
索引的大小如果超过了单个节点的硬件限制,那么分片就派到用场了,它可以将一个索引进行分成多个部分的分片,分别存储到不同的节点上。创建索引时就要指定其分片数,一旦索引创建成功,分片数就无法更改了,不指定的话,默认为 1。副本时分片的备份,当主分片所在数据不可用时,如果一段时间内没有恢复,则会将副本提升为新的主分片。
- 主分片:提供数据查询,数量不可动态更新
- 副本:主分片的备份,当主分片不可用,其会提升为主分片,数量可以动态更新。
PUT /my_index
{
"settings": {
"number_of_shards": 2, // 设置主分片数为 2
"number_of_replicas": 1 // 设置副本数为 1
}
}
节点角色
ElasticSearch为每个节点指定了一个角色,不同的角色负责不同的工作,角色比较多,下面介绍常用的几个
- master: 主节点,主要集群以及元数据的管理(索引的创建/更新)
- data_content: 数据节点,负责数据的存储,搜索,聚合查询等
- ingest: 预处理节点,负责数据的预处理,如数据的过滤,转换等
堆内存设置
默认情况下,Elasticsearch JVM使用的堆内存最小和最大值均为4 GB(8.X版本以上)。建议将堆大小配置为服务器可用内存的50%,上限为32GB,且预留足够的内存给操作系统以提升缓存效率
ES_JAVA_OPTS="-Xms8g -Xmx8g" ./bin/elasticsearch
2. 通过Analyzer进行分词
Analysis - 文本分析是把全文转换成一系列单词(term/token)的过程,也叫分词,其是由 Analyzer实现的,除了在数据写入时需要进行分词,在Query查询时也会先进行分词
分词器
分词器是专门处理分词的组件,由3部分组成
Character Filter:针对原始文本处理,例如去除html标签Tokenizer: 按照规则切分单词Token Filter:将切分好的单词进行加工(转小写,删除stopwords,增加同义词等)
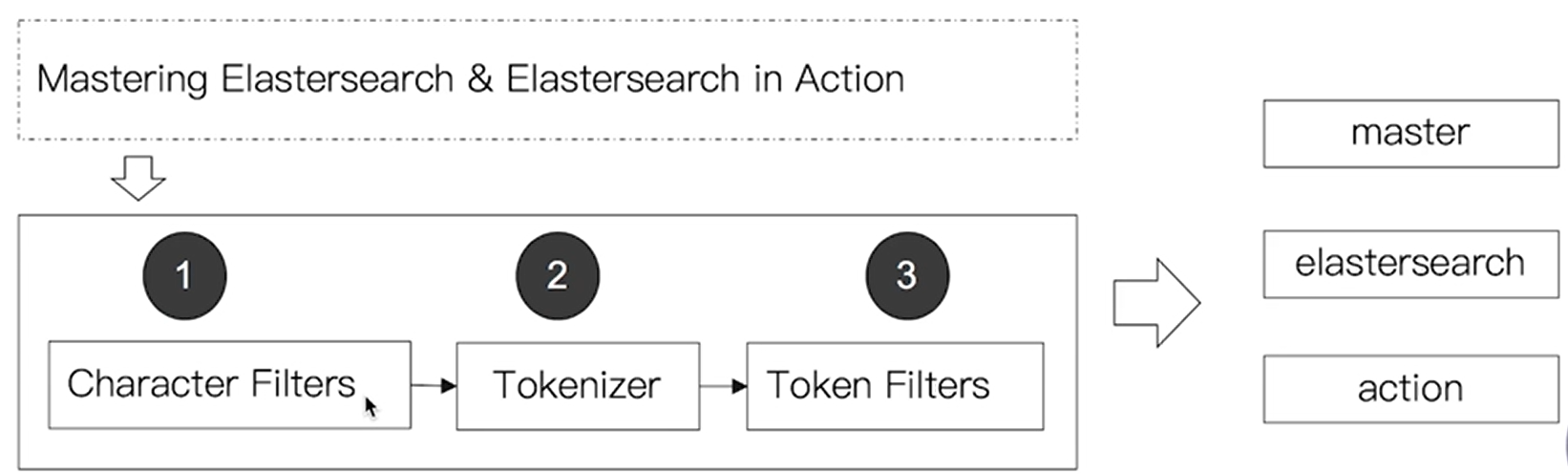
内置分词器

使用 _analyze API
- 直接使用Analyzer测试分词效果
Get /_analyze
{
"analyzer": "standard", // 指定分词器
"text": "i love you" // 指定要分词的文本
}
- 对某个索引字段进行分词测试
POST user/_analyze
{
"field": "address", // 指定要测试的索引字段
"text": "河南省周口市淮阳县"
}
- 自定义分词器进行测试
POST /_analyze
{
"tokenizer": "standard", // 指定tokenizer
"filter": ["lowercase"] // 指定filter对分词后的数据进行加工
"text": "i Love you"
}
POST /_analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "mapping",
"mappings": ["-" => "_"] //将文本中的- 替换成 _
}
],
"text": "158-110-2978"
}
对某个索引设置自定义分词器
PUT user
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_alalyzer": {
"type": "custom",
"char_filter": ["emoticons"], // 引用的下面自定义的char_filter
"tokenizer": "punctuation",
"filter": ["lowercase","english_stop"]
}
},
// 自定义 char_filter
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":)"=>"happy", ":("=>"sad"]
}
},
// 自定义tokenizer
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": [.,!?]
}
},
// 自定义 filter
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
}
}
}
}
}
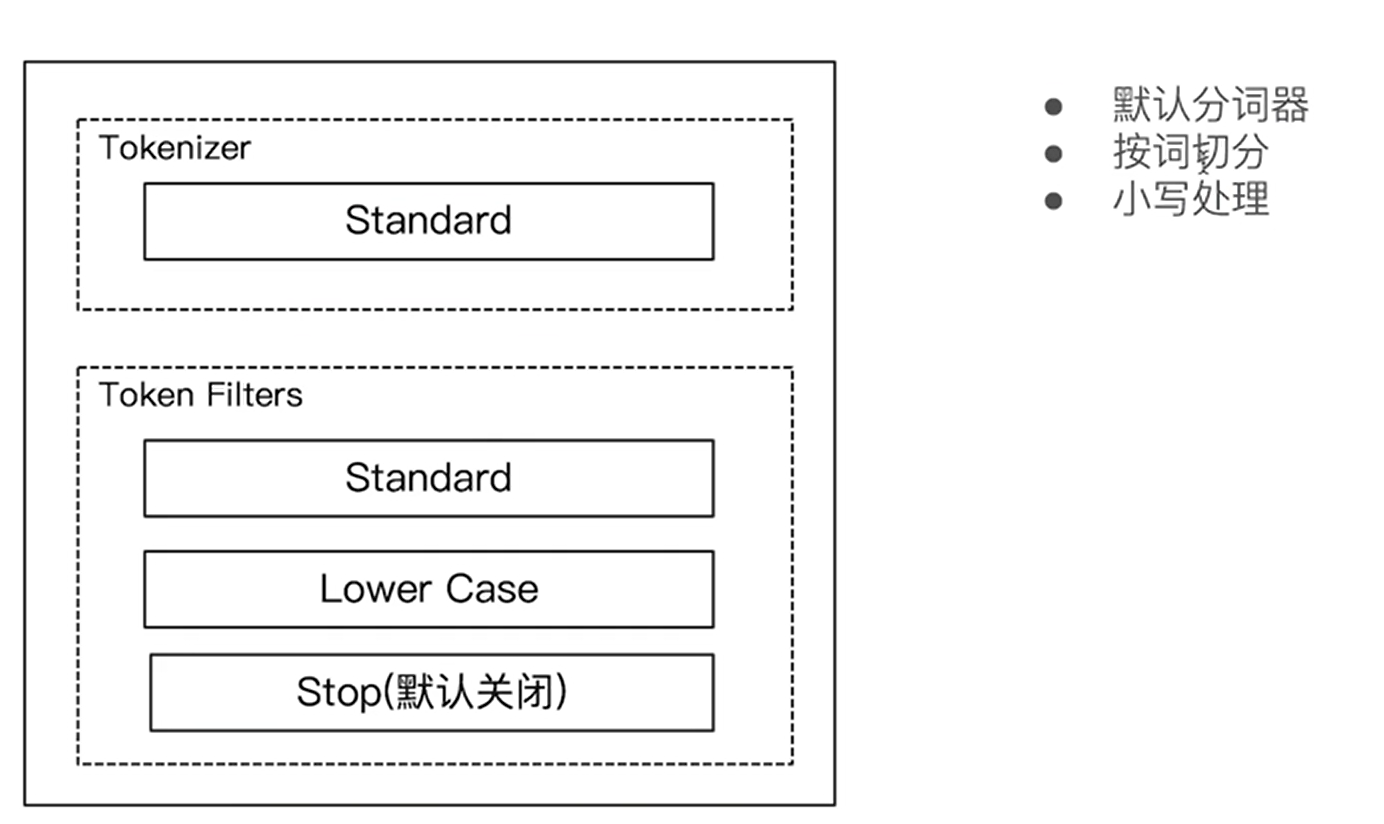
Standard 分词器
它是ES的默认分词器,它是按词进行切分,并进行了小写处理,它的StopWords的filter默认是关闭的
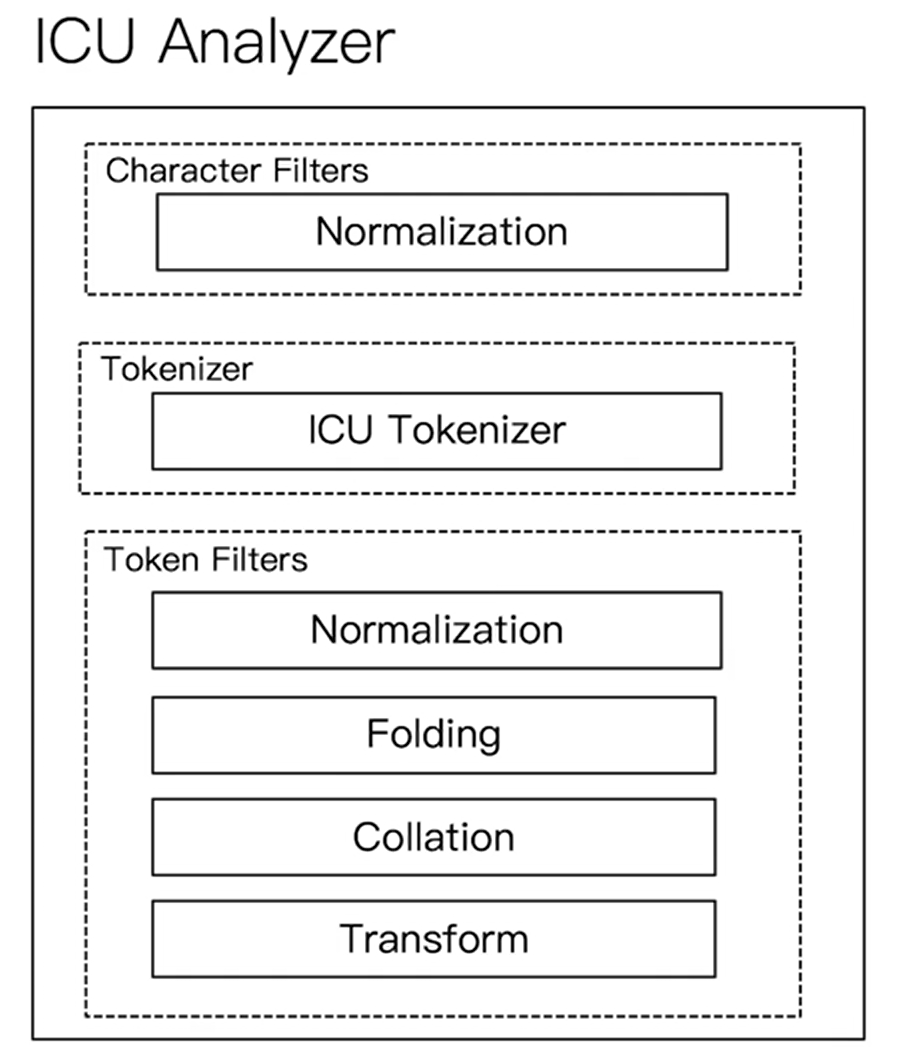
中文分词
中文分词要比英文更加复杂,因为要将其分成一个个词(不是一个个字),而且中文在不同的上下文由不同的理解(
这苹果不大好吃/这苹果,不大,好吃)
- 安装icu分词插件
Elasticsearch-plugin install analysis-icu
2. IK 分词器
- 支持自定义词库,支持热更新分词字典
- 安装该插件
elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.4.1
它是由清华大学自然语言处理实验室开发的一款es分词器
- https://github.com/microbun/elasticsearch-thulac-plugin
面向自然语言的中文分词器,基于机器学习
- 使用测试:https://hanlp.com/semantics/functionapi/participle
3. Mapping
-
Mapping类似数据库中
schema的定义,作用如下:- 定义索引中字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔…
- 字段以及倒排索引的相关配置 (Analyzer)
-
Mapping 会把 JSON 文档映射成 LUcene 所需要的扁平格式
-
一个Mapping属于一个索引的Type
- 每个文档都属于一个Type
- 一个Type有一个Mapping的定义
- 7.0开始,不需要在Mapping定义中指定type信息
数据类型
-
简单类型
- Text / Keyword
- Date
- Integer / Floating
- Boolean
- Ipv4 & Ipv6
-
复杂类型
- 对象类型 / 嵌套类型
-
特殊类型
- geo_point & geo_shape / percolator
Mapping操作
- 查看Mapping定义
Get user/_mapping
- 定义Mapping
PUT user
{
"mappings": {
"properties": {
"firstName": {
"type": "keyword"
"copy_to": "fullName" // 将该字段的值copy到fullName中,后面可以通过 fullName 查询 firstName + lastName 的数据
},
"lastName": {
"type": "keyword"
"copy_to": "fullName"
},
"desc": {
"type": "text",
"null_value": "NULL" //如果想对null值进行搜索
},
"info": {
"type": "text",
"index": false // 设置不生成索引,可以减少磁盘空间,但该字段不能被搜索了
},
}
}
}
- 修改Dynamic
PUT user
{
"mappings": {
"_doc": {
"dynamic": "false"
}
}
}
Dynamic Mapping
-
在写入文档的时候,如果索引不存在,会自动创建索引
-
Dynamic Mapping 机制使得我们无需手动定义Mappings,Elasticsearch会自动根据文档信息,推算出字段的类型,但有时候会推算的不对,例如地理位置信息
-
当类型设置不对时,会导致一些功能无法正常运行,例如 Range 查询
-
Dynamic 设为
false,Mapping不会自动更新,新增字段的数据无法被索引(搜索),但是信息会出现在_source中 -
Dynamic 设置成
Strict,文档中如果有新增字段的话文档写入时会失败 -
对已有字段,一旦已经有数据写入,就不再支持修改字段定义了,如果希望改变字段类型,必须
Reindex API,重建索引,因为修改了字段的数据类型,会导致已被索引的数据无法被搜索,但如果是增加新的字段,就不会有这样的影响
4. Template
Index Template
index template 可以帮助你设定 Mappings 和 Settings,并按照一定的规则自动匹配到新创建的索引上。
- 模板仅在一个索引被新创建时才会产生作用,修改模板不会影响已创建的索引
- 可以设定多个索引模板,这些设置 会被
merge在一起 - 可以指定
order的数值,控制 merge 的过程
创建模板
PUT _template/my_default_template
{
"index_patterns": ["my_inedex_*"], //索引匹配规则
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas":1
},
"mappings": {
"date_detecation": false, // 关闭日期类型探测
"number_detecation": true // 开启数字类型探测
}
}
Index Template 工作方式
当一个索引被新创建时:
- 应用ElasticSearch 默认的 settings 和 mappings
- 应用 order 数值低的 Index Template 中的设定
- 应用 order 数值 高的 Index Template 中的设置,之前的设定会被覆盖
- 应用用户指定的 Settings 和 Mapping,并覆盖之前模板中的设置
所以优先级为:
用户指定的 > Index Template中 order 高的 > Index Template中order低的 > Elasticsearch默认的
Dynamic Template
它可以根据Elasticsearch识别的数组类型,结合字段名称,来动态的设定字段类型
比如它可以实现下列功能:
- 所有字符串类型都设定成 Keyword,或者关闭 keyword 字段
- is 开头的字段都设置成 boolean
- long_ 开头的都设置成 long 类型
注意事项
- Dynamic Template 时定义在某个索引的 Mapping 中的
- 匹配规则是一个数组
- 为匹配到的字段设置 Mapping
新增Dynamic Template
PUT my_index_test
{
"mappings": {
"dynamic_template": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
5. Search API
可以通过url search 或者 request body search 进行搜索,url search使用起来比较简单,而 request body search 则支持更丰富的语法搜索
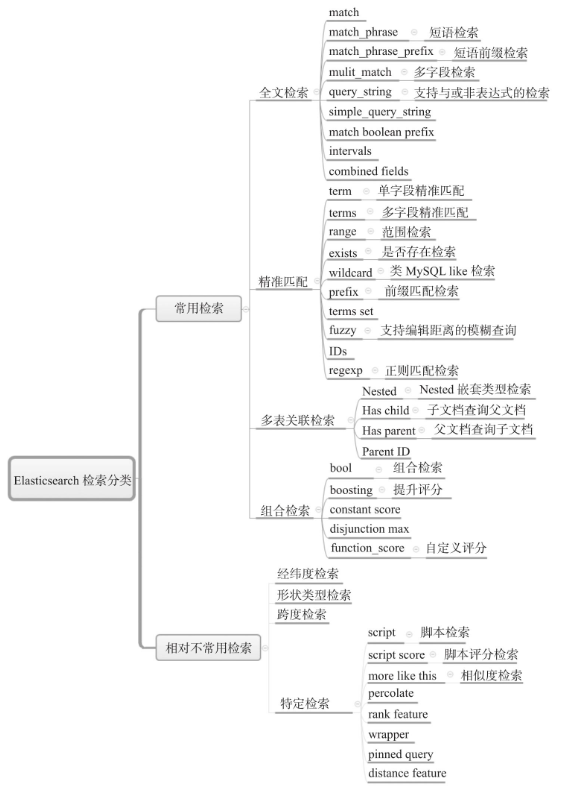
URL Search

// 对所有字段查询(范查询性能很差)
GET user/_search?q=张三
// 指定字段简单查询
GET user/_search?q=name:张三
// 必须包含张三你好,且前后顺序也要相同
// 如果不加引号,则等效为 张三 OR 李四
GET user/_search?q=name:"张三你好"
// 指定字段正则查询
GET user/_search?q=name:张*
// 模糊查询&近似度查询
// ~1 单词相似就可以
// ~2 不考虑位置,近似就可以
GET user/_search?q=name:beauful~1
// 与查询,也可以用 AND 必须大写
GET user/_search?q=name:(张三 && 李四)
// + 表示must,- 表示must_not
GET user/_search?q=name:(+李四)
// 区间查询,闭区间[],开区间{}
GET user/_search?q=age:[18 TO 24]
// 算数符号
GET user/_search?q=age:(>=18 && <=20)
精确查询
精确查询主要是用来查询 非 text 类型的字段,可以使用
term,terms,range,exists,wildcard,prefix,fuzzy
- term 查询
GET my_index/_search
{
"query": {
"term": {
"status": {
"value": "done"
}
}
}
}
- 多个精确查询
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"status": {
"value": "done"
}
}
},
{
"terms": {
"tags": [
"运动",
"篮球"
]
}
},
{
"exists": {
"field": "news_content"
}
},
{
"range": {
"age": {
"gte": 18,
"lte": 50
}
}
}
]
}
}
}
- nested匹配
GET my_index/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"term": {
"user_name": {
"value": "派大星"
}
}
}
}
}
}
- 如果不想要算分,可以使用
constant_score+filter跳过算分,查询效率更高
GET user/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"id.keyword": "xahb-ccde-12"
}
}
}
}
}
- 正则查询
通过正则表达式进行匹配数据,跟下面的通配符类似,也是比较消耗资源的,数据量比较大的情况下不推荐使用。
GET my_index/_search
{
"query": {
"regexp": {
"name": "测试*"
}
}
}
- 通配符匹配
仅适用于 keyword 类型字段的数据,如果字段被分词了,那么结果可能不符合预期,另外该搜索比较消耗资源,在文档量级比较大的情况下不推荐使用的
GET my_index/_search
{
"query": {
"wildcard": {
"title": {
"value": "*测试*"
}
}
}
}
- 前缀匹配
查询固定前缀的文档数据,注意它也只能用于 keyword 字段类型
GET my_index/_search
{
"query": {
"prefix": {
"title": {
"value": "测试"
}
}
}
}
- fuzzy纠错查询
fuzzy检索是一种强大的搜索功能,它能够在用户输入内容存在拼写错误或上下文不一致时,仍然返回与搜索词相似的文档
GET my_index/_search
{
"query": {
"fuzzy": {
"title": {
"value": "langauge" // 单词拼错了,也可以正确返回
}
}
}
}
全文搜索
主要是针对字段为 text 类型的数据,也就是需要进行分词的字段。
主要使用match,match_phrase,match_phrase_prefix,query_string,simple_query_string
- match 适用于召回率高、精准度不高的场景。
- match_phrase 适用于精准度高、召回率不高的场景。
- match_phrase_prefix 适用于短语前缀匹配检索。 mulit_match适用于多字段检索。
- query_string 适用于支持与或非表达式的检索。
- simple_query_string 适用于比query_string容错率更高的场景。
- match 查询
match检索的核心就是将待检索的语句根据设定的分词器分解为独立的词项单元,然后对多个词项单元分别进行term检索,最后对各
term检索词项进行bool组合。
GET user/_search
{
"query": {
"match": {
// 默认是 OR 关系, 也就是 张三 OR 你好
"desc": {
"query": "张三你好",
"operator": "AND" // 指定为AND关系
}
}
}
}
- match_phrase 短语查询
match_phrase检索适用于注重精准度的召回场景。与match检索(分词检索)不同,match_phrase检索更适合称为短语匹配检索。这是因为match_phrase检索要求查询的词条顺序和文档中的词条顺序保持一致,以确保更高的精准度。
GET user/_search
{
"query": {
"match_phrase": {
"desc": {
"query": "张三你好",
"slop": 1, // 表示中间可以有1个term的差别
}
}
}
}
- match_phrase_prefix 查询
它结合了短语匹配和前缀匹配的特点。在这种检索方式下,查询词语需要按顺序匹配文档中的内容,同时允许最后一个词语只匹配其前缀。它在用户输入、搜索建议或自动补全等场景中非常有用
GET my_index/_search
{
"query": {
"match_phrase_prefix": {
"title": "测试"
}
}
}
- multi_match 查询
它适用于在多个字段上执行match检索的场景。它提供了一种方便的方法来在多个字段中同时搜索指定的关键词,从而实现跨字段的高效检索
GET my_index/_search
{
"query": {
"multi_match": {
"query": "测试",
// 为了强调title字段在搜索结果中的重要性,我们使用 ^3 来提高其权重
"fields": ["title^3", "content"]
}
}
}
- query_string 查询
query_string检索允许用户使用Lucene查询语法直接编写复杂的查询表达式。这种查询方式具有高度的灵活性和精确度,支持多字段查询、通配符查询、模糊查询、范围查询等多种检索类型。应用场景包括高级搜索、数据分析和报表等,适合处理需满足特定需求、要求支持与或非表达式的复杂查询任务,通常用于专业领域或需要高级查询功能的应用中。
GET my_index/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "测试 AND 派大星"
}
}
}
- simple_query_string 查询
是一种用户友好且易于使用的查询方式。它具有类似于query_string查询的灵活性,而且对用户输入的语法错误更加宽容。这种查询方式支持多字段、通配符、模糊等基本检索类型,同时简化了Lucene查询语法。应用场景包括基本搜索和快速筛选等
GET my_index/_search
{
"query": {
"simple_query_string": {
"query": "小苹果 AND 新年 OR", // 语法是错的也没关系,会尽量匹配,如果用query_string则会报错
"fields": ["content"]
}
}
}
高亮和排序
- 高亮搜索
GET user/_search
{
"query": {
"match": {
"desc": "爬山"
}
},
"highlight": {
"fields" : {
"desc" : {}
}
}
}
返回结果
{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"name": "张三",
"age": 25,
"desc": "张三喜欢爬山"
},
"highlight": {
"desc": [
"张三喜欢去 <em>爬山</em>"
]
}
}
]
}
}
- 排序
最好对数字或日期类型的数据进行排序
GET user/_search
{
"sort": [{"create_time": "desc"}],
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
- 只获取某几个字段的值
source 也支持通配符
GET user/_search
{
"_source": ["name", "age", "create_time", "class*"],
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
分页查询
分页查询有3中方式,
from+size,search_after,scroll
数据量较小推荐使用from+size
数据量大且只能向后翻场景用search_after
全量文档遍历,不要求实时响应 用scroll
- from+size
这种查询是最简单也是最灵活的,但它有个明显缺点,它不能无限往后翻页,查询数量受
max_result_window限制,该值默认为 10000, 而且它对内存开销比较大,比如你{from:6000,size: 10}, 它也要把 6010 个文档加载到内存中(要遍历所有分片,获取所有数据,排序后返回),对于分页较多的页面或大量结果,这样操作会显著增加内存和CPU使用率,导致性能下降,甚至导致节点故障。所以此查询越往后翻页越慢。
GET user/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
- search_after
不严格受制于
max_result_window,可以无限地往后翻页。此处的“不严格”是指单次请求值不能超过max_result_window,但总翻页结果集可以超过。search_after缺点:只支持向后翻页,不支持随机翻页。search_after不支持随机翻页,更适合在手机端应用的场景中使用,类似今日头条等产品的分页搜索。
search_after的后续查询都是基于PIT视图进行的,能有效保障数据的一致性。
- 创建PIT视图,会返回该视图id
// 视图保留时间为5分钟,如果超过再查询会报错
POST my_index/_pit?keep_alive=5m
- 首次使用该视图查询
// 用视图查询,不用指定索引了
POST _search
{
"query": {},
"pit": {
"id": "spCTBAEpbWV0cmljcy1lbmRwb2ludC5tZXRhZGF0YV9jdXJyZW50X2RlZmF1bHQWa0h4Z1FHYmZUMEN0aUtuZEJEVUtJdwAWbV9OY3lscDZSWlN2QjNBbzlNSTBuZwAAAAAAAFT-ZxZhV1hqZFBnalNweU10VnZVU2gtMG9BAAEWa0h4Z1FHYmZUMEN0aUtuZEJEVUtJdwAA",
"keep_alive": "1m" // 继续续期
},
"sort": [{"created_at": {"order": "desc" }}]
}
- 利用search_after继续往后查询
POST _search
{
"query": {},
"pit": {
"id": "spCTBAEpbWV0cmljcy1lbmRwb2ludC5tZXRhZGF0YV9jdXJyZW50X2RlZmF1bHQWa0h4Z1FHYmZUMEN0aUtuZEJEVUtJdwAWbV9OY3lscDZSWlN2QjNBbzlNSTBuZwAAAAAAAFT-ZxZhV1hqZFBnalNweU10VnZVU2gtMG9BAAEWa0h4Z1FHYmZUMEN0aUtuZEJEVUtJdwAA",
"keep_alive": "1m" // 继续续期
},
"sort": [{"created_at": {"order": "desc" }}],
// 里面的值是上一次查询返回的Hits里最后一个数据的 sort 里的值
"search_after": [
"2024-08-16 12:00:00"
]
}
- scroll
如果把from+size和search_after两种请求看作近实时的请求处理方式,那么scroll滚动遍历查询显然是非实时的。数据量大的时候,响应时间可能会比较长。
scroll查询优点:支持全量遍历,是检索大量文档的重要方法,但单次遍历的size值不能超过max_result_window的大小。 scroll查询缺点:响应是非实时的;保留上下文需要具有足够的堆内存空间;需要通过更多的网络请求才能获取所有结果。
// 1. 创建scroll
POST my_index/_search?scroll=5m
// 2. 使用
POST _search/scroll
{
"scroll": "1m",
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlNrbEJFV3huVFc2bWlvQTI2NWZ4MncAAAAAADnf6hZyZXo3dnRZNFR1ZS1jdGVNUDVzN1hR"
}
Bool Query(组合查询)
通过 bool query,可以嵌套查询多个条件,比如在 must 中再嵌套一个 bool 查询
bool查询包含4种子句,其中2中会影响算分,2种不影响算分,它们既可以是单term,也可以是数组
- must: 必须匹配,影响算分
- shoule: 选择性匹配,影响算分
- must_not:必须不匹配,使用的Filter Context,不影响算分
- filter:过滤匹配,不影响算分
查询示例
name=张三 && 年龄 >18 && 性别=男 && 爱好 = (滑雪 或 打游戏)
GET user/_search
{
"query": {
"bool": {
"must": {"term": {"name": "张三"}}, //也可以是数组,下面的filter,must_not也同理
//"must": [
// {"term": {"id": 1}},
// {"term": {"name": "李四"}}
//],
"must_not": {"range": {"age": {"lte": 18}}},
"filter": {"term": {"sex": "男"}},
"should": [
{"term": {"hobby": "滑雪"}},
{"term": {"hobby": "打游戏"}}
],
"minimum_should_match": 1 // should 至少匹配 1个,如果不设置一个都不匹配的也能查出来
}
}
}
Dis Max Query
Disjunction Max Query 可以将任何与任一查询匹配的文档作为结果返回,采用字段上最匹配的评分作为最终评分返回。主要用来处理有竞争字段时算分不符合我们想要的结果(should是对各个字段的算分进行简单的加和)
查询示例
GET user/_search
{
"query": {
"dis_max": {
"queries": [
{"match": {"title": "我爱滑雪"}},
{"match": {"desc": "我爱滑雪"}}
],
"tie_breaker": 0.2
}
}
}
tie_breaker
它是一个介于0和1之间的一个浮点数,0代表使用最佳匹配,1代表所有语句同等重要
- 获得最佳语句的评分 _sorce
- 将其他匹配语句的评分与 tie_breaker 相乘
- 对以上评分求和并规范化
Multi Query
单字符串多字段查询,它有以下3中场景
best_fields(最佳字段): 当字段之间相互竞争,又相互关联时,评分来自最匹配的字段most_fields(多字段):对多个字段进行查询,比如在处理英文文档时可以建立一个子字段,这样对 英文字段和子字段一块搜索,既可以多召,又可以精确匹配cross_fields(混合字段):对于某些实体,例如人名,地址,个人信息,需要在多个字段中确定信息,单个字段只能作为整体的一部分,希望在任何这些列出的字段中找到尽可能多的词
查询示例
// 最佳字段匹配
GET user/_search
{
"query": {
"multi_match": {
"query": "我爱滑雪",
"type": "best_fields",
"fields": ["title", "desc"],
"tie_breaker": 0.2
}
}
}
// 多字段匹配, 它不支持 operator: "and"
GET user/_search
{
"query": {
"multi_match": {
"query": "I love you",
"type": "most_fields",
"fields": ["title", "title.std"]
}
}
}
// 混合字段匹配
GET user/_search
{
"query": {
"multi_match": {
"query": "大雷楼",
"type": "cross_fields",
"operator": "and",
"fields": ["title", "desc", "address"]
}
}
}
自定义算分
Index Boost
在索引层面修改相关度,它可以跨多个索引搜索时为每个索引配置不同的级别。所以它适用于索引级别调整评分。
一批数据里有不同的标签,数据结构一致,要将不同的标签存储到不同的索引(A、B、C),并严格按照标签来分类展示(先展示A类,然后展示B类,最后展示C类
GET my_index_*/_search
{
"indices_boost": [
{
"my_index_a": 1.5
},
{
"my_index_b": 1.2
},
{
"my_index_c": 1
}
],
"query": {
"term": {
"content_type": {
"value": "1"
}
}
}
}
Boosting
boosting是控制相关度的一种手段
- 当 boost > 1时:打分的相关度相对性提升
- 当 0<boost <1 时:打分的权重相对性降低
- 当 boost < 0 时:贡献负分
GET user/_search
{
"query": {
"match": {
"title": {
"query": "新年好",
"boost": 2 // 更改boost值,使title里有新年好的算分更大
}
}
}
}
Boost 复合查询
如果搜索 苹果,更想让其返回 吃的苹果,而不是苹果手机,可以通过 boost 复合查询,将包含 手机的语句提供负分,这样 跟苹果手机相关的文档就会放在最下面(并不是不返回,跟must_not不同)
GET user/_search
{
"query": {
"boosting": {
"positive": {
"term": {"title": "苹果"}
},
"negative": {
"term": {"title": "手机"}
},
"negative_boost": 0.2 //修改negative的boost值
}
}
}
Function Score
可以在查询结束后,对每一个匹配的文档进行一系列的重新算法,根据新生成的分数进行排序
它提供了默认几种计算分值的函数
Weight:为每一个文档设置一个简单而不被规范化的权重field_value_factor:使用该数值来修改 _score,例如将 热度 和 点赞数 作为算分的参考因素rangdom_score:为每一个用户使用一个不同的随机算分结果衰减函数:以某个字段的值为标准,距离该值越近,得分越高Script Score:自定义脚本完全控制算分逻辑
示例
- 按博客受欢迎(点赞数)提升权重
GET blog/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "elasticsearch笔记",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "likes"
}
}
}
}
新的算分 = 老的算分(相关度) * 点赞数
这种会有极端的问题,比如点赞数为0,那么新的算分就是 0 了,或点赞数比较大,也会极大影响算分结果,所以可以添加 modifier 参数,使算法更平滑,新的算分 = 老的算分 * log(1 + 点赞数)
"field_value_factor": {
"field": "likes",
"modifier": "log1p"
}
也可以添加 factor 参数,这样 新的算分 = 老的算分 * log(1 + factor * 点赞数)
"field_value_factor": {
"field": "likes",
"modifier": "log1p",
"factor": 0.3
}
- 一致性随机函数
让每个用户能看到不同的随机排名,但是也希望同一个用户访问时,结果的相对顺序保持一致
GET blog/_search
{
"query": {
"function_score": {
"rangdom_score": {
"seed": 666 //只要seed值一样,返回的结果顺序就是一致的,可以将seed值设为用户id
}
}
}
}
- 利用脚本自定义算法逻辑
GET my_index/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "测试"
}
},
"script_score": {
"script": "_score * doc['age'].value"
}
}
}
}
Suggester Query
搜索建议,不仅可以用来进行纠错,也可以实现自动补全,上下文提示等,根据不同的使用场景,ES设计了4种类别的 Suggester
Suggester类别
- Term Suggester:适用于简单的拼写检查和单个词的建议。
- Phrase Suggester:适用于需要考虑词序和短语的建议场景。
- Completion Suggester:适用于自动补全功能。
- Context Suggester:适用于需要结合上下文信息的自动补全场景。
精准度&召回率&性能
- 精准度: Completion> Phrase > Term
- 召回率:Term > Phrase > Completion
- 性能:Completion> Phrase > Term
Suggesting Mode
missing:如果索引中已经存在,就不提供建议popular:推荐出现频率更高的词always:无论是否存在,都提供建议
示例
- term suggest
GET blog/_search
{
"query": {
"match": {
"content": "hello wrold" // wrold 错别字
}
},
"suggest": {
"my-term-suggestion": {
"text": "hello wrold",
"term": {
"suggest_mode": "missing",
"field": "content"
}
}
}
}
返回结果
{
"suggest": {
"my-term-suggestion": [
{
"text": "hello", // 因为mode是missing,索引中有该term,所以就不返回建议项
"optiops": []
},
{
"text": "wrold",
"optiops": [
{
"text": "world",
"score": 0.9, // 相似度
"freq": 2 // 出现频率
}
]
}
]
}
}
- phrase suggest
GET blog/_search
{
"suggest": {
"my-phrase-test": {
"text": "elasticsearch use note and hello wrold",
"phrase": {
"field": "content",
"max_error": 2, // 最大可以拼错的term数
"confidence": 1, // 限制返回结果数,默认1
"direct_generator":[{
"field": "content",
"suggest_mode": "always"
}]
}
}
}
}
- completion suggester
提供了 自动补全的功能,用户每输入一个字符,就需要发送一个查询请求到后端查询匹配项,所以对性能要求比较苛刻,ES采用了不同的数据结构,并非通过倒排索引来完成,而是将Analyze的数据编码成
FST和索引一起存放, FST会被ES整个加载进内存,速度很快,缺点就是 只能用于前缀查询
定义Mapping
PUT blog
{
"mappings": {
"properties": {
"title_completion": {
"type": "completion"
}
}
}
}
查询
GET blog/_search?pretty
{
"suggest": {
"completion-suggester-test": {
"prefix": "elastic",
"completion": {"field": "title_completion"}
}
}
}
- context suggester
基于上下文信息自动补全
可以定义2种类型的context
- category:任意字符串
- geo:地理位置西悉尼
定义Mapping
PUT comments/_mapping
{
"properties": {
"comment_autocomplete": {
"type": "completion",
"contexts": [
{
"type": "category",
"name": "coment_category"
}
]
}
}
}
添加文档时增加上下文信息
POST comments/_doc
{
"comment": "I love the star war movies",
"comment_autocomplete": {
"input": ["star wars"],
"contexts": {
"comment_categroy": "movies" // 如果类目是电影就推荐 star wars
}
}
}
POST comments/_doc
{
"comment": "I love the starbucks",
"comment_autocomplete": {
"input": ["starbucks"],
"contexts": {
"comment_categroy": "coffe" // 如果类目是咖啡就推荐 starbucks
}
}
}
查询
GET comments/_search
{
"suggest": {
"context-suggest-test": {
"prefix": "sta",
"completion": {
"field": "comment_autocomplete",
"context": {
"comment_category": "movies" // 如果是电影类目,就会返回 star wars
}
}
}
}
}
模板查询
可以先定义好查询模板,后面查询时只需要传递模板定义好的参数就行
模板定义
POST _scripts/tmdb_test
{
"script": {
"lang": "mustache",
"source": {
"_source": ["title", "desc"]
},
"size": 20,
"query": {
"multi_match": {
"query": "{{q}}",
"fields": ["title", "desc"]
}
}
}
}
使用模板
POST tmdb/_search/template
{
"id": "tmdb_test",
"params": {
"q": "我喜欢滑雪"
}
}
Filter与Match查询区别
对于结构化数据的精确匹配、范围筛选等,优先使用高效的 filter 查询
对于全文本搜索、相关性排序等,使用 match 查询
组合使用 filter 和 match 查询,先用 filter 过滤出初步结果,再用 match 对结果进行相关性评分排序
filter 查询
- 基于缓存的重用 bitset,因此对于查询结果已缓存的场景,性能更优
- 主要用于结构化数据(例如日期范围、数字范围或精确值匹配等)
- 可以有效利用 Elasticsearch 的倒排索引进行快速查找
match 查询
- 基于相关性评分,可以排序结果
- 适合全文检索场景,支持模糊搜索、短语搜索等
- 对于大量文本数据,需要重新计算评分,相对更加消耗资源
6. 聚合查询(Aggregation)
Elasticsearc除了提供搜索以外,也提供了对ES数据进行统计分析的能力,通过聚合我们可以得到一个数据的概览。总的来说聚合一共分为4类,桶聚合,指标聚合,管道子聚合,组合聚合
聚合的分类
Bucket Aggregation:桶聚合,一些列满足特定条件的文档集合- 相当于SQL里面的 GROUP
- 把满足条件的结果分成一个个桶
Metric Aggregation:指标聚合,一些数据运算,可以对文档字段进行统计分析- 相当于SQL里面的 COUNT,MAX,AVG 等
- 比如计算 最大值,最小值,平均值
- stats 统计,可以一次性输出最大,最小,平均,累加,累计 值
Pipeline Aggregation:管道子聚合,对其他聚合结果进行二次聚合Matrix Aggreation:组合聚合,支持对多个字段的操作并提供一个结果矩阵
桶聚合
桶聚合就是针对某个字段的值,或一段区间,或日期 进行分组,类似于mysql 中的 group by
注意,如果是对 text 字段 做 terms 分桶统计,那么统计的是分词后的结果,所以建议 分桶时的字段类型是 keyword
- 单字段分桶
GET user/_search
{
"size": 0, // 不返回 hits 信息
"aggs": {
"sex_count": { // 按性别进行分桶,会返回每个性别的数量
"terms": {
"field": "sex"
}
}
}
}
- 多字段分桶
这是用脚本实现的,也可以通过 组合聚合 进行实现
GET user/_search
{
"size": 0,
"aggs": {
"sex_city_count": { // 按性别&城市进行分桶,会返回 性别##城市 的数量
"script": {
"source": "doc['sex'].value+ '##' +doc['city'].value"
// 有null的可以使用下方兼容模式
// "source": "if (doc['sex'].size() > 0 && doc['city'].size() > 0) { return doc['sex'].value + '~~' + doc['city'].value; } else { return 'null_value'; }"
}
}
}
}
- 对nested中的字段进行聚合
GET my_index/_search
{
"aggs": {
"my_comments_name_agg": {
"nested": {
"path": "comments"
},
"aggs": {
"my_name_agg": {
"terms": {
"field": "comments.name"
}
}
}
}
}
}
- 自定义间隔直方桶 (range)
按照数字的范围进行分桶,比如安装年龄段进行分桶,可以自定义 key
GET user/_search
{
"size": 0,
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{"key": "0~18", "from": 0, "to": 18},
{"key": "19~30", "from": 19, "to": 30},
{"key": ">30", "from": 30}
]
}
}
}
}
- 固定间隔直方桶
以某个间隔对数据进行分桶,比如每隔 10 岁对年龄进行分桶,这样会分为0-10,10-20,20-30,不可以自定义 key, key是以间隔值递增的
GET user/_search
{
"size": 0,
"aggs": {
"age_histogram": {
"histogram": {
"field": "age",
"interval": 10, //分桶间隔
"extended_bounds": { // 设置范围区间
"min": 0,
"max": 200
}
}
}
}
}
- 日期直方桶
已固定时间间隔进行分桶,支持月,天,小时,分钟级别
GET my_index/_search
{
"aggs": {
"my_data_count": {
"date_histogram": {
"field": "create_time",
"fixed_interval": "1d"
}
}
}
}
指标聚合
指标聚合来计算数据的最大值、最小值、平均值等统计信息
-
单值分析:只输出一个分析结果
- min,max,avg,sum
- cardinality (去重,类似distinct count)
-
多值分析:输出多个分析结果
- stats (包含min,max,avg,sum)
- percentile(百分位),percentile rank(百分位排名)
- top hits (排在前面的示例)
GET user/_search
{
"size": 0,
"aggs": {
"max_age": {
"max": {"field": "age"}
},
"min_age": {
"min": {"field": "age"}
},
"avg_age": {
"avg": {"field": "age"}
},
"sum_age": {
"sum": {"field": "age"}
},
// 对user_id去重
"cardinality_age": {
"cardinality": {"field": "user_id"}
}
}
}
上面的几个字段可以直接使用 stats 代替
GET user/_search
{
"aggs": {
"stats_age": {
"stats": {"field": "age"}
}
}
}
找出不同性别,年龄最大的3个用户
GET user/_search
{
"size": 0,
"aggs": {
"sex_terms": {
"terms": {"field": "sex"}
},
"aggs": {
"max_age_user": {
"top_hits": {
"size": 3,
"sort": [{"age": {"order": "desc"}}]
}
}
}
}
}
找出用户去重后的原声量
GET user/_search
{
"aggs": {
"group_by_user_id": {
"terms": {
"field": "user_id",
"order": [
{
"voc_id_uniq": "desc"
}
],
"size": 1000
},
"aggs": {
"voc_id_uniq": {
"cardinality": {
"field": "voc_id"
}
}
}
}
}
}
- 返回去重后的文档
有2种方式,1种是利用
top_hits,另一种则可以使用collapse
- 使用 top_hits
POST my_index/_search
{
"aggs": {
"groupby_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"my_top_hits": {
"top_hits": {
"size": 1,
"_source": ["title","content","brand"],
"sort": [{"create_time": {"order": "desc"}}]
}
}
}
}
}
}
- 使用 collapse
先根据brand去重,再对brand内部的color进行去重
POST my_index/_search
{
"query": {
"match_all": {}
},
"collapse": {
"field": "brand",
"inner_hits": {
"name": "color_collapse",
"collapse": {
"field": "color"
},
"size": 10
}
}
}
管道子聚合
支持对聚合分析的结果,再次进行聚合分析,类似SQL对 子查询结果的数据 再次统计计算
使用场景:求分组后 获取所有组中的 最大值/最小值/平均值
select min(avg_age) from
(
select address,
count(*) as cnt,
avg(age) from user group by address
order by cnt desc
) as t

Sibling示例
在出生地最多的用户中,找出平均年龄最低的出生地
GET user/_serach
{
"size": 0,
"aggs": {
"address_bucket": {
"terms": {
"field": "address",
"size": 10
},
"aggs": {
"avg_age": {
"avg": {"field": "age"}
}
}
},
// 注意层级,它与 address_bucket 同级
"min_avg_age_by_address": {
"min_bucket": {
"bucket_path": "address_bucket>avg_age"
}
}
}
}
- min_bucket: 求之前结果的最小值
- max_bucket: 求之前结果的最大值
- avg_bucket: 求之前结果的平均值
- bucket_path: 指定层级路径
Parent示例
在出生地最多的用户中,对这些出生地的平均年龄进行累计求和
GET user/_serach
{
"size": 0,
"aggs": {
"address_bucket": {
"terms": {
"field": "address",
"size": 10
},
"aggs": {
"avg_age": {
"avg": {"field": "age"}
}
},
// 注意层级,它在 address_bucket 里面
// 所以bucket_path不需要再写 address_bucket
"cumulative_age": {
"cumulative_sum": {
"bucket_path": "avg_age"
}
}
}
}
}
组合聚合
它在已有聚合方式的基础上提供了进一步聚合的能力,其结果形成了嵌套的聚合结构。组合聚合具有强大的分页处理能力,可以针对所有层级结构的桶执行精确的分页操作。
- 先根据城市进行分组,再对每个城市里的性别进行分组
GET my_index/_search
{
"aggs": {
"groupby_city_and_sex": {
"composite": {
"sources": [
{
"city": {
"terms": {
"field": "city"
}
}
},
{
"sex": {
"terms": {
"field": "sex"
}
}
}
]
}
}
}
}
- 求环比
用当前12月分数据,对比11月份数据,求环比上涨多少
GET my_index/_search
{
"aggs": {
"my_range_aggs": {
"range": {
"field": "create_time",
"format": "yyyy-MM-dd",
"ranges": [
{
"from": "2023-11-01",
"to": "2023-12-31"
}
]
},
"aggs": {
"11month_count": {
"filter": {
"range": {
"create_time": {
"gte": "2023-11-01",
"lte": "2023-11-30"
}
}
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "price"
}
}
}
},
"12month_count": {
"filter": {
"range": {
"create_time": {
"gte": "2023-12-01",
"lte": "2023-12-31"
}
}
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "price"
}
}
}
},
"month_growth": {
"buckets_path": {
"pre_month_sum": "11month_count > sum_aggs",
"cur_month_sum": "12month_count > sum_aggs"
},
"script": "(params.cur_month_sum - params.pre_month_sum) / params.pre_month_sum"
}
}
}
}
}
- 求环比(简化版)
GET my_index/_search
{
"size": 0,
"aggs": {
"months": {
"date_histogram": {
"field": "create_time",
"calendar_interval": "month",
"format": "yyyy-MM"
},
"aggs": {
"total_value": {
"sum": {
"field": "value"
}
},
"monthly_growth": {
"bucket_script": {
"buckets_path": {
"prev_month": "months[1].total_value",
"current_month": "total_value"
},
"script": "params.current_month - params.prev_month"
}
},
"monthly_growth_rate": {
"bucket_script": {
"buckets_path": {
"prev_month": "months[1].total_value",
"current_month": "total_value"
},
"script": "(params.current_month - params.prev_month) / params.prev_month * 100"
}
}
}
}
}
}
集合的作用范围
聚合分析的作用范围是 query 查询的结果集,如果没有 query 则是对全局进行统计,除此之外也可以通过
filter,post_filter,global改变 聚合查询的作用范围
filter:指定聚合统计的匹配条件
GET user/_search
{
"size": 0,
"aggs": {
// 只看出生地为上海的工作分类
"shanghai_jobs": {
"filter": {"term": {"address": "上海"}},
"aggs": {"terms": {"field": "job"}}
},
// 看所有人的工作分类
"all_jobs": {
"aggs": {"terms": {"field": "jobs"}}
}
}
}
post_filter: 指定展示聚合统计结果哪个桶的具体信息(Hits)
GET user/_search
{
"aggs": {
"jobs": {"terms": {"field": "job"}}
},
// 把性别为男的详细数据展示到 Hits中
"post_filter": {
"match": {
"sex": "男"
}
}
}
global: 忽略掉query中的界定条件,对全局所有的数据进行统计分析
GET user/_search
{
"query": {
"term": {
"sex": "男"
}
}
"aggs": {
"jobs": {"terms": {"field": "job"}},
"all": {
// 指定 global后,它是对全局的数据进行统计
"global": {},
"aggs": {
"avg_age": {"avg": {"field": "age"}}
}
}
}
}
集合的排序
默认情况下是按照 count 进行降序排序,所以想要返回前多少个,只需要指定 size 即可,也可以手动更改排序
GET user/_serach
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job",
// 先按统计值降序
// 如果统计值一样,按key升序
"order": [
{"_count": "desc"},
{"_key": "asc"},
//{"avg_age": "desc"}, 对平均值进行排序
//{"stats_age.min": "desc"} // 对统计值中某个值进行排序
],
"size": 10
}
}
}
}
集合的精准性
当数据量大时,分布在不同的集群上,这时再进行聚合分析时,它返回的是一个近似值,而不是一个精确值,可以通过 修改
shard_size来提升它的准确性,但会对性能产生一个的影响
shard_size: 默认值 为 size * 1.5 + 10,它的值越大越准确doc_count_error_upper_bound: 被遗漏的 term 分桶,值越大说明得到的结果越不准确sum_other_doc_count: 除了返回结果 bucket 的 terms 以外,其他 terms 的文档总数
GET user/_search
{
"size": 0,
"aggs": {
"sex_count": {
"terms": {
"field": "sex",
"shard_size": 10,
"show_term_doc_count_error": true
}
}
}
}
优化Terms聚合的性能
通过开始
eager_global_ordinals参数,使该字段的 Terms 预加载,每当有新的文档进来时就会进行计算,放到内存到
PUT index
{
"mappings": {
"properties": {
"sex": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
}
7.脚本
脚本操作一般应用于相对复杂的业务场景,包括自定义字段、自定义评分、自定义更新、自定义reindex、自定义聚合,以及其他自定义操作。

自定义字段
可以通过脚本,自定义一个返回字段。
GET my_index/_search
{
"script_fields": [
{
"content_len": {
"script": {
"lang": "painless",
"source": "doc['content'].value.length()"
}
}
},
{
"create_time_year": {
"script": {
"lang": "painless",
"source": "doc['create_time'].value.getYear()"
}
}
}
]
}
自定义评分
通过脚本自定义修改
_score的值,达到最佳匹配效果
GET my_index/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "测试"
}
},
"functions": [
{
"script_score": {
"script": "_score * doc['age'].value"
}
}
]
}
}
}
自定义更新
将 name 以 test 开头的数据的 is_deleted 都置为 1
POST my_index/_update_by_query
{
"query": {"match_all": {}}, // 全部更新
"script": {
"source": """
if(ctx._source.name = ~/^test/) {
ctx._source.is_delted = 1;
}
""",
"lang": "painless"
}
}
更新 nested 中的字段
POST my_index/_update_by_query
{
"query": {"match_all": {}},
"script": {
"source": """
for(e in ctx._source.comments) {
if (e.name= 'test') {
e.status = 'done';
}
}
""",
"lang": "painless"
}
}
自定义聚合
按 性别+城市 进行分桶,会返回 性别##城市 的数量
GET user/_search
{
"aggs": {
"sex_city_count": {
"script": {
"source": "doc['sex'].value+ '##' +doc['city'].value"
// 有null的可以使用下方兼容模式
// "source": "if (doc['sex'].size() > 0 && doc['city'].size() > 0) { return doc['sex'].value + '##' + doc['city'].value; } else { return 'null_value'; }"
}
}
}
}
自定义预处理管道
下面通过预处理管道,新增一个 文本长度的字段
PUT _ingest/pipeline/my_test_pipeline
{
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx.content_len = ctx.content.length();"
}
}
]
}
使用该管道更新数据
POST my_index/_update_by_query?pipeline=my_test_pipeline
{
"query": {
"match_all": {}
}
}

















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









