







一、前言
1、简介
在 Elasticsearch7.15版本之后,Elasticsearch官方将它的高级客户端 RestHighLevelClient标记为弃用状态。同时推出了全新的 Java API客户端 Elasticsearch Java API Client,该客户端也将在 Elasticsearch8.0及以后版本中成为官方推荐使用的客户端。
Elasticsearch Java API Client 支持除 Vector tile search API 和 Find structure API 之外的所有 Elasticsearch API。且支持所有API数据类型,并且不再有原始JsonValue属性。它是针对Elasticsearch8.0及之后版本的客户端,所以我们需要学习新的Elasticsearch Java API Client的使用方法。
2、为什么要抛弃High Level Rest:
-
客户端"too heavy",相关依赖超过 30 MB,且很多都是非必要相关的;api 暴露了很多服务器内部接口
-
一致性差,仍需要大量的维护工作。
-
客户端没有集成 json/object 类型映射,仍需要自己借助字节缓存区实现。
3、Java API Client最明显的特征:
- 支持lambda表达式操作ES
- 支持Builder建造者模式操作ES,链式代码具有较强可读性.
- 应用程序类能够自动映射为Mapping.
- 所有Elasticsearch API的强类型请求和响应。
- 所有API的阻塞和异步版本
- 将协议处理委托给http客户端(如Java低级REST客户端),该客户端负责处理所有传输级问题:HTTP连接池、重试、节点发现等。
4、官方地址
https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.15/connecting.html
二、简单使用-java main函数
1:导包
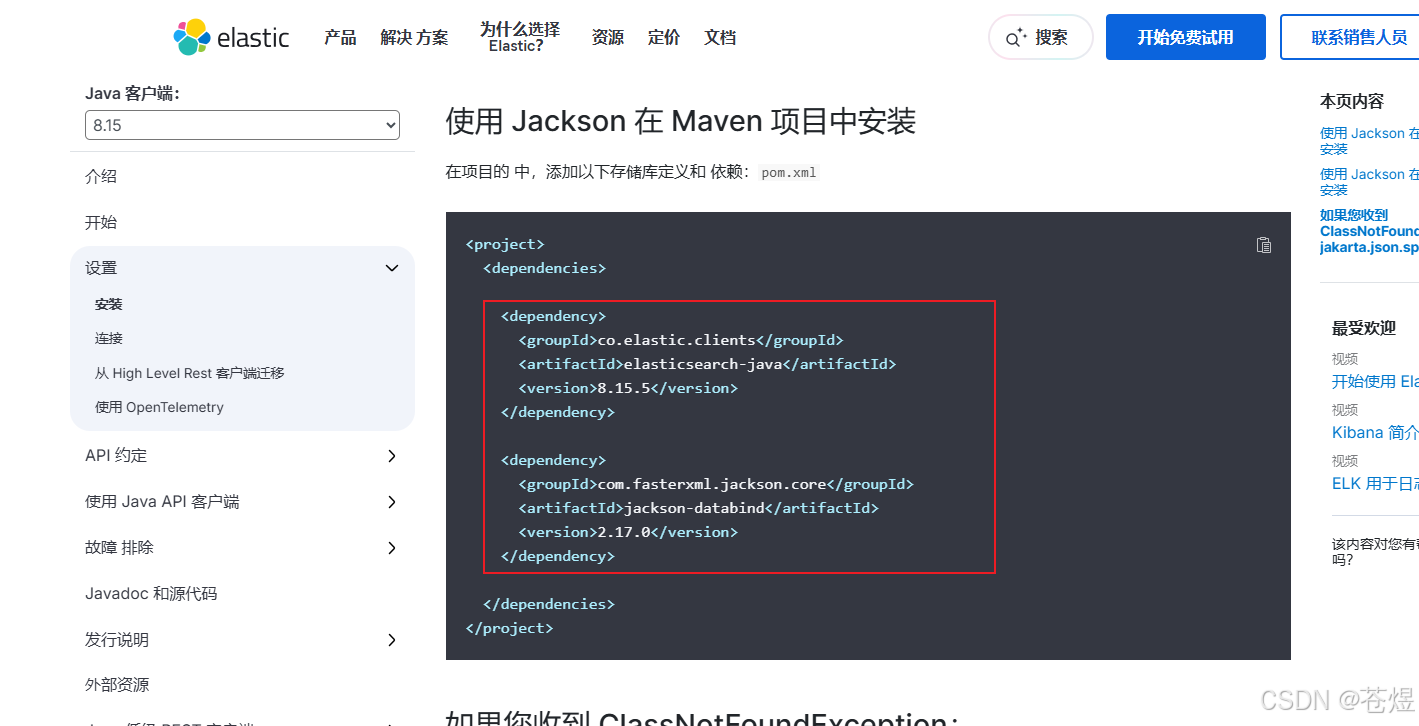
这里记住你的elasticsearch-java必须对应你电脑上装的ES版本,我此时使用的
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.15.5</version>
<exclusions>
<exclusion>
<artifactId>elasticsearch-rest-client</artifactId>
<groupId>org.elasticsearch.client</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.15.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.17.0</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
注:此处的elasticsearch-java版本应该和你要对接的es版本一样。
1:先访问官方,看看那推荐导入什么版本
2:根据自己的现实项目进行调整
在我实践过程中,发现一直报各种NoSuchMethodError等错误。说白了就是因为版本不对,一直报错。
因为我使用的是RuoYi v3.6.5框架,因为内置了很多功能,所以版本冲突挺多的。最后经过各种调整,形成了上边的pom文件配置,大家可以参考下。
2:开启链接
//创建一个低级的客户端
final RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).build();
//创建JSON对象映射器
final RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
//创建API客户端
final ElasticsearchClient client = new ElasticsearchClient(transport);
3:关闭链接
client.shutdown();
transport.close();
restClient.close();
4:完整代码
public class Client {
public static void main(String[] args) throws IOException {
//创建一个低级的客户端
final RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).build();
//创建JSON对象映射器
final RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
//创建API客户端
final ElasticsearchClient client = new ElasticsearchClient(transport);
//查询所有索引-------------------------------------------------------------------------------------
final GetIndexResponse response = client.indices().get(query -> query.index("_all"));
final IndexState products = response.result().get("products");
System.out.println(products.toString());
//关闭
client.shutdown();
transport.close();
restClient.close();
}
}
三、JsonData类
原始JSON值。可以使用JsonpMapper将其转换为JSON节点树或任意对象。 此类型在API类型中用于没有静态定义类型或无法表示为封闭数据结构的泛型参数的值。 API客户端返回的此类实例保留对客户端的JsonpMapper的引用,并且可以使用to(class)转换为任意类型,而不需要显式映射器
我们一般在ES的DSL范围查询中会使用到!
核心方法:
- to:将此对象转换为目标类。必须在创建时提供映射器
- from:从读取器创建原始JSON值
- of:从现有对象创建原始JSON值,以及用于进一步转换的映射器
- deserialize:使用反序列化程序转换此对象。必须在创建时提供映射器
四、springboot&springCloud配置使用
0:ES参数实体-nacos获取
package com.wenge.business.config;
import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.stereotype.Component;
@Component
@Data
@RefreshScope
public class ElasticSearchProperties {
@Value("${elasticsearch.host:127.0.0.1:9200}")
private String host;
/**
* 连接池里的最大连接数
*/
@Value("${elasticsearch.max_connect_total:30}")
private Integer maxConnectTotal;
/**
* 某一个/每服务每次能并行接收的请求数量
*/
@Value("${elasticsearch.max_connect_per_route:10}")
private Integer maxConnectPerRoute;
/**
* http clilent中从connetcion pool中获得一个connection的超时时间
*/
@Value("${elasticsearch.connection_request_timeout_millis:2000}")
private Integer connectionRequestTimeoutMillis;
/**
* 响应超时时间,超过此时间不再读取响应
*/
@Value("${elasticsearch.socket_timeout_millis:30000}")
private Integer socketTimeoutMillis;
/**
* 链接建立的超时时间
*/
@Value("${elasticsearch.connect_timeout_millis:2000}")
private Integer connectTimeoutMillis;
/**
* keep_alive_strategy
*/
@Value("${elasticsearch.keep_alive_strategy:-1}")
private Long keepAliveStrategy;
@Value("${elasticsearch.username}")
private String userName;
@Value("${elasticsearch.password}")
private String password;
}
nacos配置如图:

1:ES配置类-普通配置
import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.alibaba.nacos.common.utils.StringUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHeaders;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponseInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.entity.ContentType;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2025-03-11 16:37
*/
@Configuration
public class ElasticSearchConfig {
@Autowired
ElasticSearchProperties elasticsearchProperties;
@Bean()
public ElasticsearchClient elasticsearchClient() {
String host = elasticsearchProperties.getHost();
String[] hosts = host.split(",");
HttpHost[] httpHosts = new HttpHost[hosts.length];
for (int i = 0; i < httpHosts.length; i++) {
String h = hosts[i];
httpHosts[i] = new HttpHost(h.split(":")[0], Integer.parseInt(h.split(":")[1]), "http");
}
// 创建 Jackson ObjectMapper 并配置忽略未知字段
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
// 设置属性命名策略为下划线命名
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategies.SNAKE_CASE);
RestClientBuilder.HttpClientConfigCallback callback = httpClientBuilder -> httpClientBuilder
.setDefaultHeaders(listOf(new BasicHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())))
.addInterceptorLast((HttpResponseInterceptor) (response, context)
-> response.addHeader("X-Elastic-Product", "Elasticsearch"));
RestClient restClient = RestClient
.builder(httpHosts)
.setHttpClientConfigCallback(callback)
.build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper(objectMapper ));
return new ElasticsearchClient(transport);
}
public static <T> List<T> listOf(T... elements) {
List<T> list = new ArrayList<>();
for (T e : elements)
list.add(e);
return Collections.unmodifiableList(list);
}
/**
* 异步方式
*
* @return
*/
@Bean
public ElasticsearchAsyncClient elasticsearchAsyncClient() {
String hosts = elasticsearchProperties.getHost();
if (!StringUtils.hasLength(hosts)) {
throw new RuntimeException("invalid elasticsearch configuration. elasticsearch.hosts不能为空!");
}
// 多个IP逗号隔开
String[] hostArray = hosts.split(",");
HttpHost[] httpHosts = new HttpHost[hostArray.length];
HttpHost httpHost;
for (int i = 0; i < hostArray.length; i++) {
String[] strings = hostArray[i].split(":");
httpHost = new HttpHost(strings[0], Integer.parseInt(strings[1]), "http");
httpHosts[i] = httpHost;
}
RestClient restClient = RestClient.builder(httpHosts).build();
RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchAsyncClient(transport);
}
}
2:ES配置类-增加账号密码
import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.alibaba.nacos.common.utils.StringUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHeaders;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponseInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.entity.ContentType;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2025-03-11 16:37
*/
@Configuration
public class ElasticSearchConfig {
@Autowired
ElasticSearchProperties elasticsearchProperties;
@Bean()
public ElasticsearchClient elasticsearchClient() {
String host = elasticsearchProperties.getHost();
String[] hosts = host.split(",");
HttpHost[] httpHosts = new HttpHost[hosts.length];
for (int i = 0; i < httpHosts.length; i++) {
String h = hosts[i];
httpHosts[i] = new HttpHost(h.split(":")[0], Integer.parseInt(h.split(":")[1]), "http");
}
// 账号密码的配置
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(elasticsearchProperties.getUserName(), elasticsearchProperties.getPassword()));
RestClientBuilder.HttpClientConfigCallback callback = httpClientBuilder -> httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider)//有密码就加这个
// .setDefaultHeaders(listOf(new BasicHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())))
.addInterceptorLast((HttpResponseInterceptor) (response, context)
-> response.addHeader("X-Elastic-Product", "Elasticsearch"));
RestClient restClient = RestClient
.builder(httpHosts)
.setHttpClientConfigCallback(callback)
.build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
public static <T> List<T> listOf(T... elements) {
List<T> list = new ArrayList<>();
for (T e : elements)
list.add(e);
return Collections.unmodifiableList(list);
}
/**
* 异步方式
*
* @return
*/
@Bean
public ElasticsearchAsyncClient elasticsearchAsyncClient() {
String hosts = elasticsearchProperties.getHost();
if (!StringUtils.hasLength(hosts)) {
throw new RuntimeException("invalid elasticsearch configuration. elasticsearch.hosts不能为空!");
}
// 多个IP逗号隔开
String[] hostArray = hosts.split(",");
HttpHost[] httpHosts = new HttpHost[hostArray.length];
HttpHost httpHost;
for (int i = 0; i < hostArray.length; i++) {
String[] strings = hostArray[i].split(":");
httpHost = new HttpHost(strings[0], Integer.parseInt(strings[1]), "http");
httpHosts[i] = httpHost;
}
RestClient restClient = RestClient.builder(httpHosts).build();
RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchAsyncClient(transport);
}
}
3:ES配置类-使用SSL证书
es的自签证书,这是SpringBoot应用在向es8发起https请求时需要用到的
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponseInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.apache.http.ssl.SSLContextBuilder;
import org.apache.http.ssl.SSLContexts;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import javax.net.ssl.SSLContext;
import java.io.IOException;
import java.io.InputStream;
import java.security.KeyManagementException;
import java.security.KeyStore;
import java.security.KeyStoreException;
import java.security.NoSuchAlgorithmException;
import java.security.cert.Certificate;
import java.security.cert.CertificateException;
import java.security.cert.CertificateFactory;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
import org.apache.http.HttpHeaders;
import org.apache.http.entity.ContentType;
import static java.util.stream.Collectors.toList;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2025-03-11 16:37
*/
@Configuration
@Slf4j
public class ElasticSearchConfig2 {
@Autowired
ElasticSearchProperties elasticsearchProperties;
@Bean()
public ElasticsearchClient elasticsearchClient() {
String host = elasticsearchProperties.getHost();
String[] hosts = host.split(",");
HttpHost[] httpHosts = new HttpHost[hosts.length];
for (int i = 0; i < httpHosts.length; i++) {
String h = hosts[i];
httpHosts[i] = new HttpHost(h.split(":")[0], Integer.parseInt(h.split(":")[1]), "http");
}
ElasticsearchTransport transport = getElasticsearchTransport(elasticsearchProperties.getUserName(), elasticsearchProperties.getPassword(), httpHosts);
return new ElasticsearchClient(transport);
}
private static ElasticsearchTransport getElasticsearchTransport(String username, String password, HttpHost... hosts) {
// 账号密码的配置
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// 自签证书的设置,并且还包含了账号密码
RestClientBuilder.HttpClientConfigCallback callback = httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(buildSSLContext())
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)
.setDefaultCredentialsProvider(credentialsProvider)
.setDefaultHeaders(
Stream.of(new BasicHeader(
HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())).collect(toList())
).addInterceptorLast(
(HttpResponseInterceptor)
(response, context) ->
response.addHeader("X-Elastic-Product", "Elasticsearch"))
.addInterceptorLast((HttpResponseInterceptor) (response, context)
-> response.addHeader("X-Elastic-Product", "Elasticsearch"));
// 用builder创建RestClient对象
RestClient client = RestClient
.builder(hosts)
.setHttpClientConfigCallback(callback)
.build();
return new RestClientTransport(client, new JacksonJsonpMapper());
}
private static SSLContext buildSSLContext() {
ClassPathResource resource = new ClassPathResource("es01.crt");
SSLContext sslContext = null;
try {
CertificateFactory factory = CertificateFactory.getInstance("X.509");
Certificate trustedCa;
try (InputStream is = resource.getInputStream()) {
trustedCa = factory.generateCertificate(is);
}
KeyStore trustStore = KeyStore.getInstance("pkcs12");
trustStore.load(null, null);
trustStore.setCertificateEntry("ca", trustedCa);
SSLContextBuilder sslContextBuilder = SSLContexts.custom().loadTrustMaterial(trustStore, null);
sslContext = sslContextBuilder.build();
} catch (CertificateException | IOException | KeyStoreException | NoSuchAlgorithmException |
KeyManagementException e) {
log.error("ES连接认证失败", e);
}
return sslContext;
}
}
4:用elasticsearchClient进行简单查询
1、构建解析工具
import co.elastic.clients.elasticsearch._types.aggregations.Aggregate;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.Hit;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.wenge.business.entity.ElasticDataRow;
import com.wenge.business.entity.EsResult;
import java.util.*;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2023-10-24 17:20
*/
public class EsUtils {
public static <T> EsResult<T> searchAnalysis(SearchResponse<T> search){
EsResult<T> result= new EsResult();
try {
result.setTotal(search.hits().total().value());
List<Hit<T>> hits = search.hits().hits();
Iterator<Hit<T>> iterator = hits.iterator();
List<ElasticDataRow> listRows = new ArrayList<ElasticDataRow>();
List<T> data = new ArrayList<>();
while (iterator.hasNext()){
Hit<T> next = iterator.next();
data.add(next.source());
}
result.setData(data);
Map<String, Aggregate> aggregations = search.aggregations();
JSONObject jsonObject = JSONObject.parseObject(JSONObject.toJSON(aggregations).toString());
result.setAggregations(aggregations);
result.setAggregationRows(getAggregationRows(jsonObject));
} catch (Exception e) {
result.setSuccess(false);
result.setMessage(e.getMessage());
}
return result;
}
private static JSONObject getAggregationRows(JSONObject aggregations) {
JSONObject result = new JSONObject();
if (aggregations != null) {
/** 判断解析类型 **/
int parseType = 1;
Set<String> keySet = aggregations.keySet();
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
JSONObject jsonObject = aggregations.getJSONObject(next);
if (jsonObject.containsKey("buckets")) {
parseType = 1;
} else {
parseType = 2;
}
}
if (parseType == 1) {
JSONArray temp_jsonArray = new JSONArray();
iterator = keySet.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
JSONObject jsonObject = aggregations.getJSONObject(next);
JSONArray buckets = jsonObject.getJSONArray("buckets");
for (int i = 0; i < buckets.size(); i++) {
JSONObject jsonTemp = new JSONObject();
JSONObject bucket_temp_jsonObject = buckets.getJSONObject(i);
Set<String> bucket_keySet = bucket_temp_jsonObject.keySet();
Iterator<String> bucket_keySet_iterator = bucket_keySet.iterator();
while (bucket_keySet_iterator.hasNext()) {
String bucket_keySet_key = bucket_keySet_iterator.next();
Object bucket_keySet_value = bucket_temp_jsonObject.get(bucket_keySet_key);
if (bucket_keySet_value instanceof JSONObject) {
Long value = ((JSONObject) bucket_keySet_value).getLong("value");
jsonTemp.put(bucket_keySet_key, value);
} else {
jsonTemp.put(bucket_keySet_key, bucket_keySet_value);
}
}
temp_jsonArray.add(jsonTemp);
}
}
result.put("rows", temp_jsonArray);
} else if (parseType == 2) {
JSONArray temp_jsonArray = new JSONArray();
iterator = keySet.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
JSONObject jsonObject = aggregations.getJSONObject(next);
JSONObject jsonTemp = new JSONObject();
jsonTemp.put(next, jsonObject.getLong("value"));
temp_jsonArray.add(jsonTemp);
}
result.put("rows", temp_jsonArray);
} else {
System.out.println("没有匹配类型");
}
}
return result;
}
}
2、构建解析实体
import co.elastic.clients.elasticsearch._types.aggregations.Aggregate;
import com.alibaba.fastjson.JSONObject;
import lombok.Data;
import java.util.List;
import java.util.Map;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2023-10-24 17:19
*/
@Data
public class EsResult<T> {
private List<T> data;
private Map<String, Aggregate> aggregations;
private JSONObject aggregationRows;
private Long total = 0L;
private Boolean success = true;
private String message;
}
import lombok.Data;
import org.apache.poi.ss.formula.functions.T;
import java.io.Serializable;
/**
* es sql行数据
*/
@Data
public class ElasticDataRow implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
private T _source;
private Double _score;
private String _index;
private String _type;
private String _id;
}
3、单元测试
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.elasticsearch.indices.GetIndexResponse;
import co.elastic.clients.elasticsearch.indices.IndexState;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.wenge.business.entity.EsResult;
import com.wenge.business.utils.EsUtils;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
/**
* @author wangkanglu
* @version 1.0
* @description
* @date 2025-03-11 20:04
*/
@SpringBootTest
public class Test1 {
@Autowired
ElasticsearchClient elasticsearchClient;
@Test
public void test1() throws IOException {
GetIndexResponse all = elasticsearchClient.indices().get(query -> query.index("_all"));
System.out.println(all.toString());
}
@Test
public void test2() throws IOException {
final SearchResponse<Object> response = elasticsearchClient.search(builder
-> builder.index("linzhi_article_favorites")
, Object.class);
final List<Hit<Object>> hits = response.hits().hits();
hits.forEach(
x-> System.err.println(x)
);
EsResult esResult = EsUtils.searchAnalysis(response);
System.out.println(esResult);
}
}
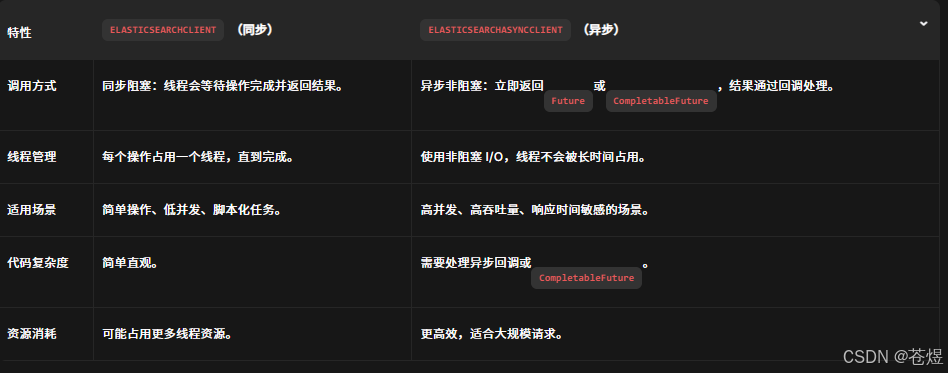
5:ElasticsearchClient 和 ElasticsearchAsyncClient异步客户端区别
- 核心区别
- 使用示例
同步客户端 (ElasticsearchClient)
// 同步查询
SearchResponse<?> response = client.search(s -> s
.index("my-index")
.query(q -> q.matchAll(m -> m)),
Object.class
);
System.out.println("查询结果:" + response.hits().hits());
异步客户端 (ElasticsearchAsyncClient)
// 异步查询(使用 CompletableFuture)
client.async().search(s -> s
.index("my-index")
.query(q -> q.matchAll(m -> m)),
Object.class
).thenAccept(response -> {
System.out.println("异步查询结果:" + response.hits().hits());
}).exceptionally(error -> {
System.err.println("异步查询失败:" + error.getMessage());
return null;
});
- 特点 :操作立即返回,结果通过回调或 CompletableFuture 处理。
- 关键差异场景
同步客户端的缺点
- 如果操作耗时(如大数据量查询),会阻塞当前线程,可能导致线程池耗尽。
- 适合简单操作或低并发场景。
异步客户端的优势
- 高并发场景下性能更高,资源利用率更好。
- 适合需要并行处理多个请求的场景(如批量索引、多条件查询)。
五、高级使用
Elasticsearch-07-Elasticsearch Java API Client-Elasticsearch 8.0 的高阶api



















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











