







Solr对中文的默认分词效果不好,例如下图:

这里采用IK-Analyzer进行中文分词,IK-Analyzer对solr5以上的版本支持在:
https://github.com/EugenePig/ik-analyzer-solr5
将编译好的ik-analyzer-solr5-5.x.jar拷贝至solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
编辑solr-5.5.0/server/solr/core1/conf/schema.xml,添加以下内容:
<fieldType name="text_ik" class="solr.TextField"><analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<!-- 如果不做同义词,可以不配置下面这个Filter -->
</analyzer>
</fieldType>
同义词的配置在
solr-5.5.0/server/solr/core1/conf/synonyms.txt,一组同义词占一行,例如,里面配置上
中国,China
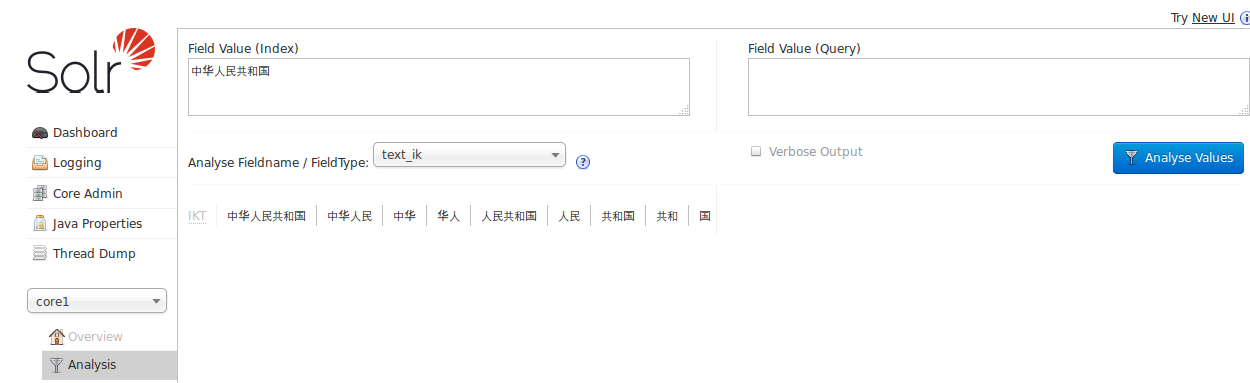
重启solr, 在Analysis页面选择FieldType: text_ik,结果如下:
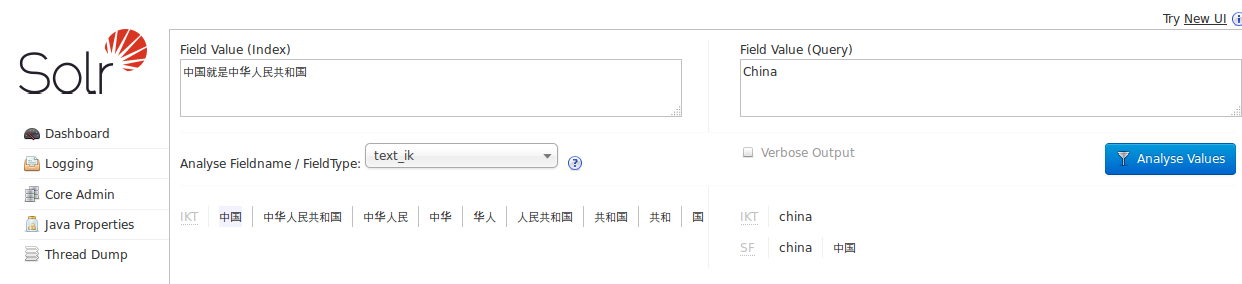
同义词查询结果如下:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









