






 本文深入解析基数排序(Radixsort)的原理与实现,包括LSD和MSD两种方法,通过图解和代码示例,详细阐述了基数排序的算法思路、性能分析及代码实现。
本文深入解析基数排序(Radixsort)的原理与实现,包括LSD和MSD两种方法,通过图解和代码示例,详细阐述了基数排序的算法思路、性能分析及代码实现。
概述
基数排序(Radix sort)属于“分配式排序”(distribution sort),它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用。
基数排序方法有两类:按照位数比较顺序的不同,将其分为 LSD(Least significant digital) 和 MSD(Most significant digital)两类。
- 最高位优先(Most Significant Digit First)法,简称MSD法:先按 k1 排序分组,同一组中记录,关键码 k1 相等,再对各组按 k2 排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码 kd 对各子组排序后。再将各组连接起来,便得到一个有序序列。
- 最低位优先(Last Significant Digit First)法,简称 LSD 法:先从 kd 开始排序,再对 kd-1 进行排序,依次重复,直到对 k1 排序后便得到一个有序序列。
下图我们针对 LSD 法进行讲解。
算法思路
基数排序的思想就是先排好个位,然后排好个位的基础上排十位,以此类推,直到遍历最高位次,排序结束。基数排序不是比较排序,而是通过分配和收集的过程来实现排序。初始化 10 个固定的桶,桶下标为 0-9。
1、将所有待比较数据统一为相同位数长度;
2、按照个位数进行排序;
3、按照十位数进行排序;
4、以此类推,已知到最高位进行排序。这样就得到一个有序序列。
图解算法
假设有一个数列 {53, 542, 3, 63, 14, 214, 154, 748, 616} 进行排序的过程如下图所示。
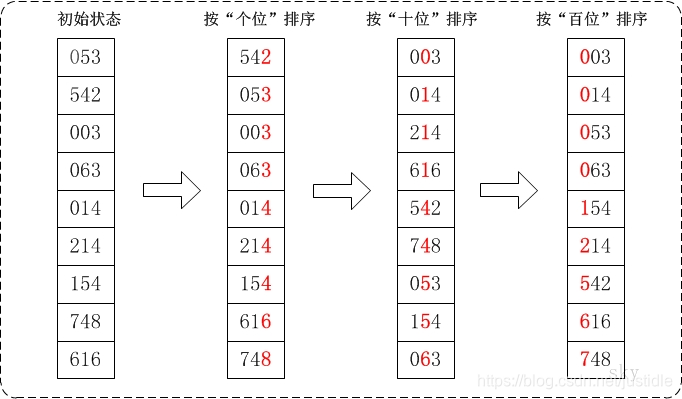
动画展示

算法性能
时间复杂度
初看起来,基数排序的执行效率似乎好的让人无法相信,所有要做的只是把原始数据项从数组复制到链表,然后再复制回去。如果有 10 个数据项,则有 20 次复制,对每一位重复一次这个过程。假设对 5 位的数字排序,就需要 20*5=100 次复制。如果有100 个数据项,那么就有 200*5=1000 次复制。复制的次数与数据项的个数成正比,即O(n)。这是我们看到的效率最高的排序算法。
不幸的是,数据项越多,就需要更长的关键字,如果数据项增加 10 倍,那么关键字必须增加一位(多一轮排序)。复制的次数和数据项的个数与关键字长度成正比,可以认为关键字长度是 N 的对数。
平均、最好、最坏都为O(k*n),其中 k 为常数,n 为元素个数。
空间复杂度
O(n + k)。
稳定性
稳定。
代码实现
C和C++
/*
*求数据的最大位数,决定排序次数
*/
int maxbit(int data[], int n) {
int d = 1; //保存最大的位数
int p = 10;
for(int i = 0; i < n; ++i) {
while(data[i] >= p) {
p *= 10;
++d;
}
}
return d;
}
void radixSort(int data[], int n) {
int d = maxbit(data, n);
int tmp[n];
int count[10]; //计数器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) {
//进行d次排序
for(j = 0; j < 10; j++) {
count[j] = 0; //每次分配前清空计数器
}
for(j = 0; j < n; j++) {
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for(j = 1; j < 10; j++) {
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
}
for(j = n - 1; j >= 0; j--) {
//将所有桶中记录依次收集到tmp中
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) {
//将临时数组的内容复制到data中
data[j] = tmp[j];
}
radix = radix * 10;
}
}
Java
/**
* 基数排序
* 考虑负数的情况还可以参考: https://code.i-harness.com/zh-CN/q/e98fa9
*/
public class RadixSort implements IArraySort {
@Override
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
int maxDigit = getMaxDigit(arr);
return radixSort(arr, maxDigit);
}
/**
* 获取最高位数
*/
private int getMaxDigit(int[] arr) {
int maxValue = getMaxValue(arr);
return getNumLenght(maxValue);
}
private int getMaxValue(int[] arr) {
int maxValue = arr[0];
for (int value : arr) {
if (maxValue < value) {
maxValue = value;
}
}
return maxValue;
}
protected int getNumLenght(long num) {
if (num == 0) {
return 1;
}
int lenght = 0;
for (long temp = num; temp != 0; temp /= 10) {
lenght++;
}
return lenght;
}
private int[] radixSort(int[] arr, int maxDigit) {
int mod = 10;
int dev = 1;
for (int i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {
// 考虑负数的情况,这里扩展一倍队列数,其中 [0-9]对应负数,[10-19]对应正数 (bucket + 10)
int[][] counter = new int[mod * 2][0];
for (int j = 0; j < arr.length; j++) {
int bucket = ((arr[j] % mod) / dev) + mod;
counter[bucket] = arrayAppend(counter[bucket], arr[j]);
}
int pos = 0;
for (int[] bucket : counter) {
for (int value : bucket) {
arr[pos++] = value;
}
}
}
return arr;
}
/**
* 自动扩容,并保存数据
*
* @param arr
* @param value
*/
private int[] arrayAppend(int[] arr, int value) {
arr = Arrays.copyOf(arr, arr.length + 1);
arr[arr.length - 1] = value;
return arr;
}
}


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











