








文章目录
Linux正则表达式
正则表达式简单来说就是处理字符串的方法,它以行为单位来进行字符串的处理操作,正则表达式通过一些特殊符号的辅助,可以轻易的帮助用户完成某些特定字符串的处理过程(删除、查找、替换)
正则表达式是一种关于特定字符串的表示法,在Linux中只要某些处理程序支持正则表达式的表示法,则该程序就可以用来作为正则表达式的字符串处理之用
正则表达式的用途
由于正则表达式对字符串具有很强大的处理能力,Linux的一般软件程序都支持正则表达式,但是具体的字符串处理对比还是需要Linux用户来进行指定比对规则,可以让你在众多的错误信息中"取敌将首级",精准定位
正则表达式分类
正则表达式的字符串表示方式依照不同的严谨度而分为:基础正则表达式与扩展正则表达式
基础正则表达式
正则表达式是处理字符串的一种表示方法,对字符串的字符排序有影响的语系数据就会对正则表达式的结果产生影响
语系对正则表达式的影响
字符串文字或数字都是通过编码表转换而来的,不同的语系的编码数据并不相同,就会造成数据选取结果的差异
- LANG=C:0 1 2 3 4 … A B C D …a b c d e…z
- LANG=zh_CN:0 1 2 3 4 …a A b B c C d D…z Z
以上就是两种不同的语系,即分别的编码数据顺序是不同的,在使用正则表达式时需要主要当时语系环境是什么,否则同样的字符串会出现于不同于别人的正则表达式语系的处理结果
多数情况下为了兼容POSIX的标准,选取的是[LANG=C]的语系环境
基础正则表达式字符集合
基础正则表达式特殊字符
| 正则表达式字符 | 字符意义 | 字符范例 |
|---|---|---|
| ^word | 待查找的字符串在行首 | 查找行首为#的那一行 grep -n ‘^#’ filename |
| word$ | 待查找的字符串在行尾 | 将行尾为!那一行打印出来并打印行号 grep -n ‘!$’ filename |
| . | 一定有一个任意字符的字符串 | 查找e与e中间一定仅一个字符的字符串 grep -n ‘e.e’ filename |
| \ | 转义符,去除特殊符号的特殊意义 | 查找单引号’的那一行 grep -n ’ filename |
| * | 重复零个到无数多个的前一个字符 | 查找ess、esss…这类的字符串 grep -n ‘ess*’ filename |
| [list] | 字符集合的正则字符,list列出想要选取的字符 | 查找gl或gd的那一行 grep -n ‘g[ld]’ filename |
| [n1-n2] | 字符集合的正则字符,里面列出选取字符的范围 | 查找大写字符在[A-Z]的字符 grep -n ‘[A-Z]’ filename |
| [^list] | 字符集合的正则字符 ,里面列出不要的字符串或范围 | 查找不要大写字符[A-Z] grep -n ’[^ A-Z]‘ filename |
| \ {n,m \ } | 意义∶连续n到m个的前一个 RE 字符,若为{n}则是连续n个的前一个RE字符,若为{n,},则是连续n个以上的前一个RE字符 | 在g与g之间有2个到3个的o存在的字符串,即(goog)(gooog)grep-n ‘go{2,3}g’ filename |
正则表达式的特殊字符与一般在命令行输入命令的通配符并不相同,通配符*表示0~无限多个字符,正则表达式则表示重复0-无数次前一个RE字符
正则表达式练习
练习文本regular_express.txt
"open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.^M
However,this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M I can't finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car.
This window is clear.^M
the symbol '*' is represented as start.
Oh! My god!^M
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1.
The world <Happy> is the same with"glad".
i like dog.^M
google is the best tools for search keyword.
goooooogle yes!
go! go! Let's go.
# I am Vbird
查找特定字符串

反向选择查找字符串
不出现特定字符才会显示在屏幕上
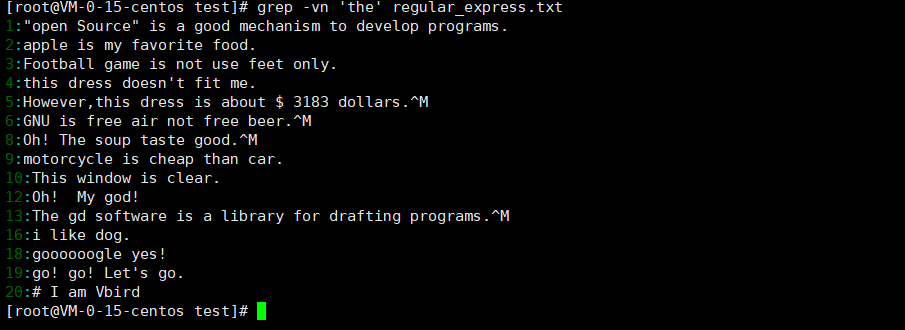
^word、word$
^表示待查找的字符串在行首,$表示待查找的字符串在行尾

.
有一个任意字符的字符串

\
转义符,去除特殊符号的特殊意义

*
重复零个到无数多个的前一个字符

[list]
字符集合的正则字符,list列出想要选取的字符

[n1-n2]
字符集合的正则字符,里面列出选取字符的范围

[^list]
字符集合的正则字符 ,里面列出不要的字符串或范围

\ {n,m\ }
连续n到m个的前一个 RE 字符,若为{n}则是连续n个的前一个RE字符,若为{n,},则是连续n个以上的前一个RE字符

扩展正则表达式
扩展正则表达式可以通过群组功能[ | ]来进行一次查找,表示意义为or;要是用扩展正则表达式,可以使用grep -E或者直接使用egrep
扩展正则表达式特殊字符
| RE字符 | 意义 | 范例 |
|---|---|---|
| + | 重复一个或一个以上的 前一个RE字符 | egrep -n ‘go+d’ filename |
| ? | 零个或一个的 前一个RE字符 | egrep -n ‘go?d’ filename |
| | | 用或的方式找出数个字符串 | egrep -n ‘gd|good’ filename |
| () | 找出群组字符串 | egrep -n ’g(la|oo)d‘ filename |
| ()+ | 多个重复群组的判别 | egrep -n 'egrep ‘A(xyz)+C’ 查找A与C之间多个xyz的字符串 |
扩展正则表达式练习
+
重复一个或一个以上的 前一个RE字符

?
零个或一个的 前一个RE字符

|
用或的方式找出数个字符串

()
找出群组字符串

()+
多个重复群组的判别

总结
正则表达式就是处理字符串的方法,它是以行为单位来进行字符串的处理操作;正则表达式通过一些特殊字符的辅助,可实现字符串处理的多种操作,只要工具程序支持正则表达式,那么该工具程序则可以作为正则表达式字符串来使用
赶紧学习起来吧!我是一个正在努力找回自我的人,希望能和一起学习的人成长,有错误的地方请各位大佬帮忙指正,如果觉得有帮助就点个赞当作对我的一个小肯定❤,peace&love
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









