







1.GFS 的主要需求
在学习 GFS 的原理前,首先我们应当了解 GFS 在设计时所面对的需求场景。简单概括,GFS 的设计主要基于以下几个需求:
- 节点失效是常态。系统会构建在大量的普通机器上,这使得节点失效的可能性很高。因此,GFS 必须能有较高的容错性、能够持续地监控自身的状态,同时还要能够顺畅地从节点失效中快速恢复
- 存储内容以大文件为主。系统需要存储的内容在通常情况下由数量不多的大文件构成,每个文件通常有几百 MB 甚至是几 GB 的大小;系统应当支持小文件,但不需要为其做出优化
- 主要负载为大容量连续读、小容量随机读以及追加式的连续写
- 系统应当支持高效且原子的文件追加操作,源于在 Google 的情境中,这些文件多用于生产者-消费者模式或是多路归并
- 当需要做出取舍时,系统应选择高数据吞吐量而不是低延时
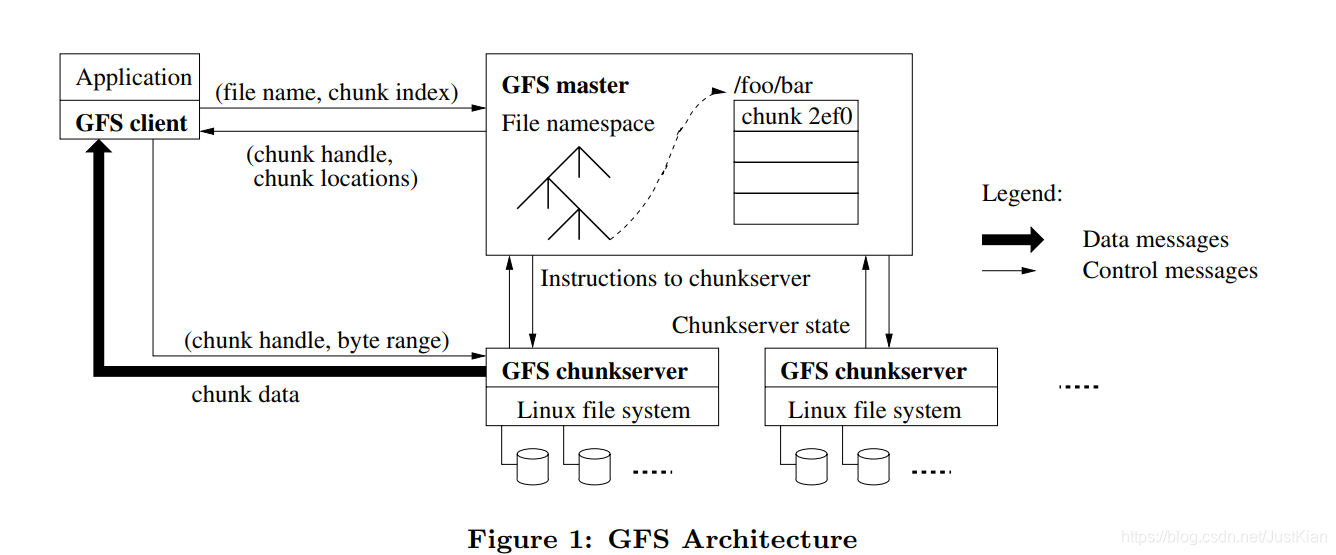
2.GFS架构
-
总体架构:GFS仍是按照目录层次结构来组织文件数据的,从上图可知,GFS由一个master和多个chunksevers组成,每个chunksever都对应一个linux文件系统,实际上所有的数据最终都是分散存储在各个Linux文件系统中。
客户端(GFS client)——以库的形式提供的,提供的就是对外要用的接口
主服务器(GFS master)——单点,存储文件信息,目录信息,文件服务器信息,那个文件存在哪些文件服务器上等元数据
存储服务器(GFS chunk-server)——集群,存储文件 -
文件分块:在GFS中文件都是被划分成固定大小的块进行管理存储的(正好对应MapReduce中的文件划分),每块有一个64位标识符(chunk handle),它是在 chunk 被创建时由 master 分配的,每一个 chunk 会有3个备份,分别在不同的机器上。我们知道在OS中,文件系统也有块的概念(即block),即代表一次能够读取的最小单位。同理,对于GFS而言,如果块大小设置得太小如几KB,此时存储一个GB级的文件都会造成占用10^6个块,那GFS对于这一个文件而言,需要管理10^6个块(会对应生成并管理10^6个handle
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









