







SQL
Structured Query Language
-
SELECT - 从数据库中提取数据
- select col1,col3 from table_name; 按列选择
- select * from table_name; 选择全部列
- SELECT * FROM Websites WHERE name IN (‘Google’,‘菜鸟教程’); 选择列在集合中的列,还有NOT IN
- SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2; 还有NOT BETWEEN
- SELECT * FROM Websites WHERE name BETWEEN ‘A’ AND ‘H’; 选择name以A-H开头的行
- select distinct col1 from table_name; 列出该列中不重复的元素
- SELECT column_name(s) FROM table_name LIMIT number; 限制选择的数目
- SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern; 使用通配符
- SELECT * FROM Websites WHERE name NOT LIKE ‘%oo%’;
- SELECT * FROM Websites WHERE name LIKE ‘_oogle’;
- SELECT * FROM Websites WHERE name REGEXP ‘^[GFs]’; 选中开头是G/F/s
- SELECT * FROM Websites WHERE name REGEXP ‘^[ ^A-H]’;选中开头不是A-H

-
UPDATE - 更新数据库中的数据
- UPDATE table_name
SET column1=value1,column2=value2,…
WHERE some_column=some_value; 如果where省略将更新所有行
- UPDATE table_name
-
DELETE - 从数据库中删除数据
- DELETE FROM table_name
WHERE some_column=some_value; 如果where省略将删除所有行 - DELETE FROM table_name;/DELETE * FROM table_name; 在保留表结构、属性、索引的前提下删除所有行
- DELETE FROM table_name
-
INSERT INTO - 向数据库中插入新数据
- INSERT INTO table_name VALUES (value1,value2,value3,…);
- INSERT INTO table_name (column1,column2,column3,…) VALUES (value1,value2,value3,…); 在指定的列插入数据,有的列可以空缺,自动不上默认的值
-
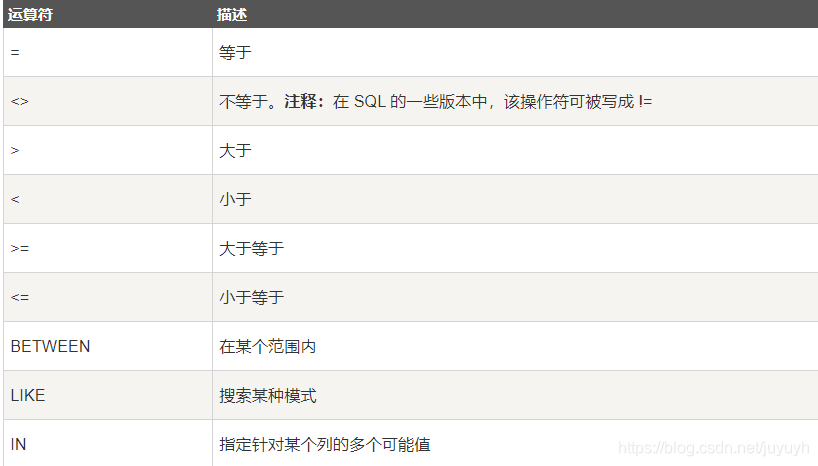
WHERE-按条件
- select * from table_name where col1=‘CN’;
- select * from table_name where col1=2;
- 可使用or和and进行逻辑运算,使用()调整优先级
-
ORDER BY-按照列或多列排序
-
单列
- SELECT column_name,column_name
FROM table_name
ORDER BY column_nameASC(升序,默认,可省略)|DESC(降序);
- SELECT column_name,column_name
-
多列
-
SELECT column_name,column_name
FROM table_name
ORDER BY column_name1,column_name2 ASC|DESC;表示排在前面的column_name排序优先级更高,即先按column_name1排序,如果column_name1相等再按照column_name2排序
-
-
-
CREATE DATABASE - 创建新数据库
- CREATE DATABASE dbname;
-
ALTER DATABASE - 修改数据库
-
CREATE TABLE - 创建新表
-
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
…
); -
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
…
); -
constraint_name包括

-
一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
- ALTER TABLE Orders DROP FOREIGN KEY fk_PerOrders;撤销约束
- ALTER TABLE Orders ADD FOREIGN KEY (P_Id) REFERENCES Persons(P_Id);添加约束
-
-
ALTER TABLE - 变更(改变)数据库表
- ALTER TABLE table_name ADD column_name datatype;添加列
- ALTER TABLE table_name DROP COLUMN column_name;删除列
- ALTER TABLE table_name MODIFY COLUMN column_name datatype;改变列的数据类型
-
DROP TABLE - 删除表
- DROP TABLE table_name;
-
CREATE INDEX - 创建索引(搜索键)
- CREATE INDEX index_name ON table_name (column_name);单列索引
- CREATE UNIQUE INDEX index_name ON table_name (column_name,column_name ); 复合索引
- CREATE UNIQUE INDEX index_name ON table_name (column_name);唯一索引
-
DROP INDEX - 删除索引
- ALTER TABLE Orders ADD FOREIGN KEY (P_Id) REFERENCES Persons(P_Id);
-
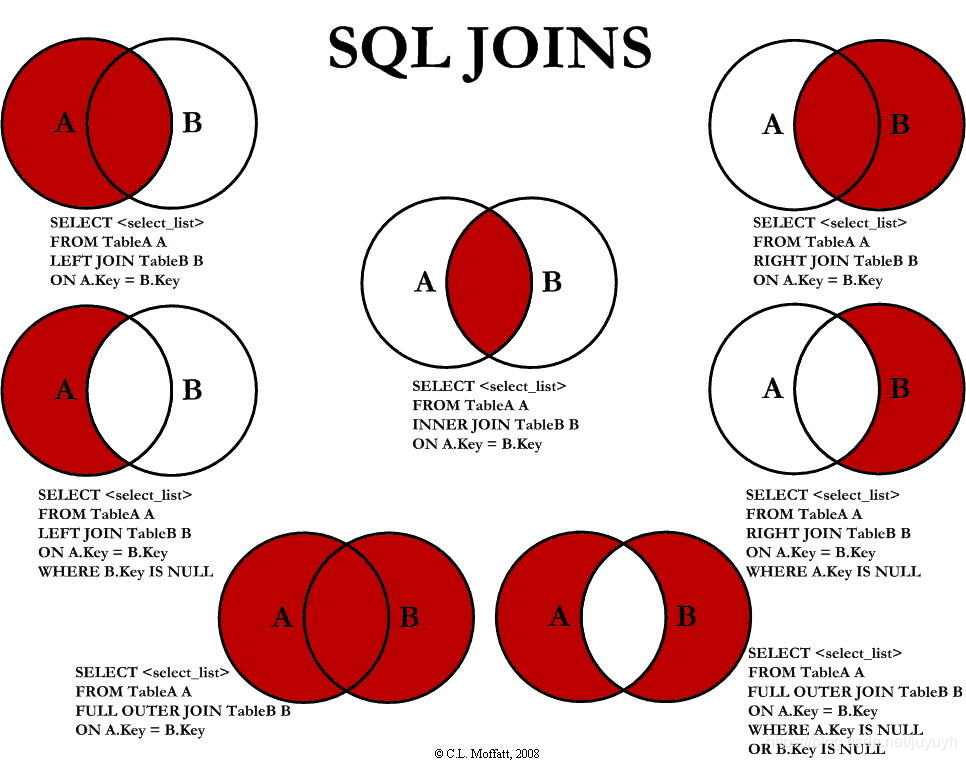
JOIN-将多个表的行结合起来
- LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN
-
union-用于合并两个或多个 SELECT 语句的结果
- SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2; - UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
- SELECT column_name(s) FROM table1
-
INSERT INTO … SELECT …;-从一个表复制数据,然后把数据插入到一个已存在的表中.
- INSERT INTO table2
SELECT * FROM table1;
- INSERT INTO table2
-
AUTO INCREMENT-自动地创建主键字段的值
- CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
- CREATE TABLE Persons
-
视图-视图是基于 SQL 语句的结果集的可视化的表。
- CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition;创建视图
- CREATE OR REPLACE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition; 更新视图
- DROP VIEW view_name;
-
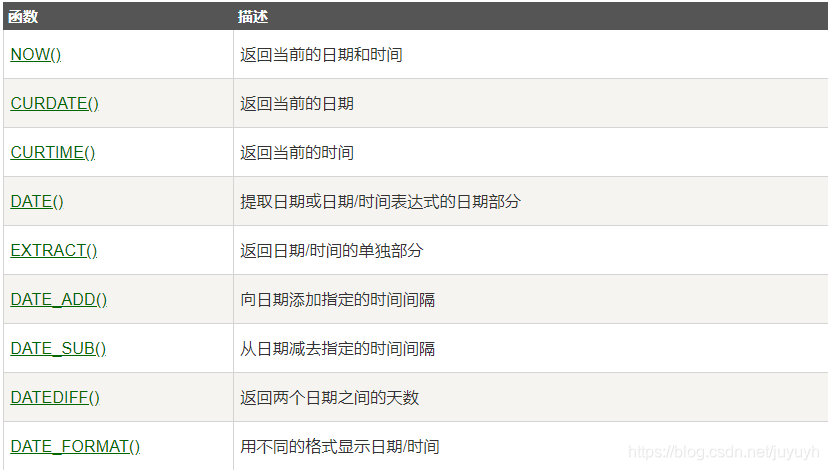
Date函数
-
NULL-NULL 值代表遗漏的未知数据。
- SELECT LastName,FirstName,Address FROM Persons WHERE Address IS NULL;
- SELECT LastName,FirstName,Address FROM Persons WHERE Address IS NOT NULL;
-
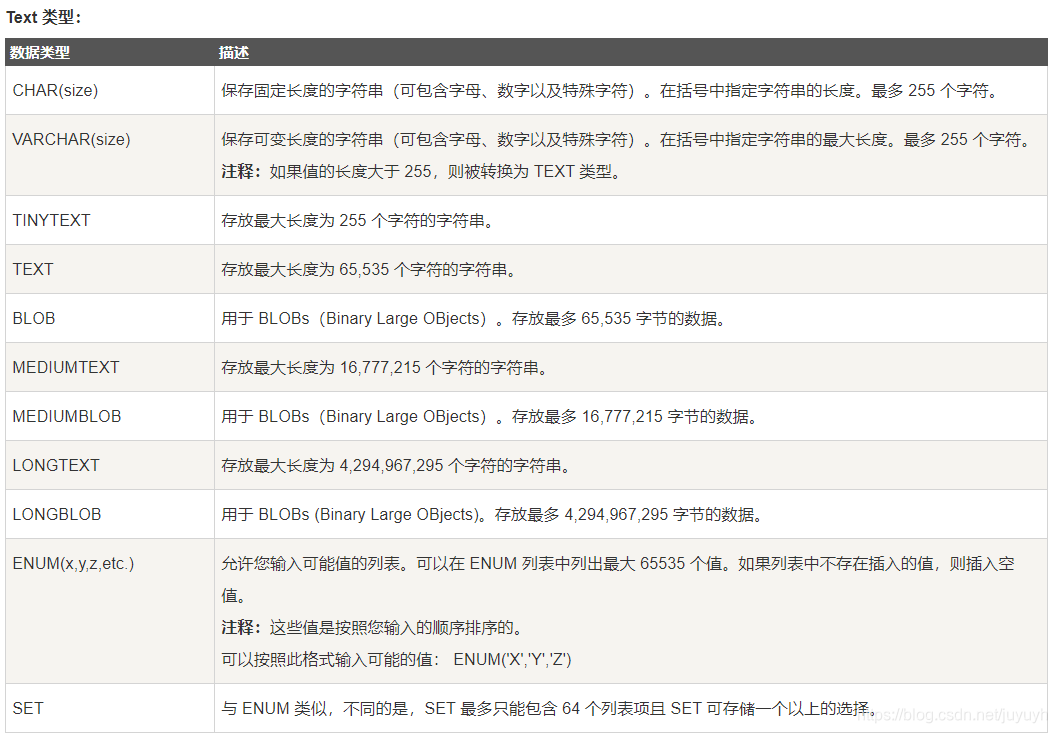
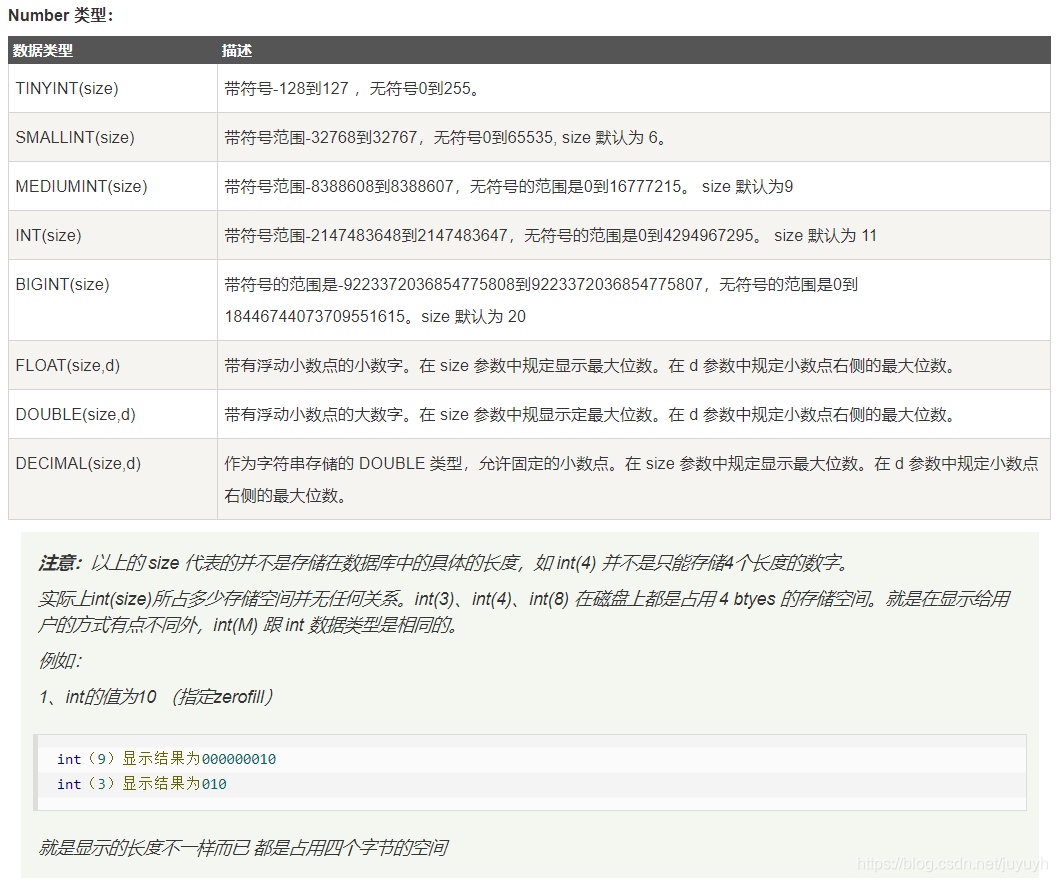
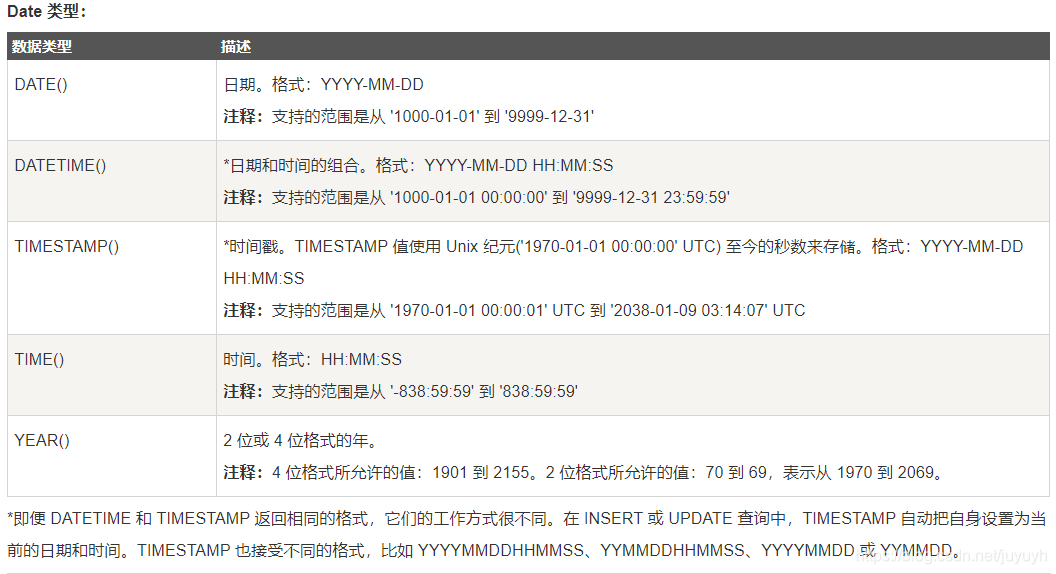
数据类型
-
SQL调优
client(SQL请求)
server(连接器->分析器(语法分析)->优化器(一条SQL语句可以有多条执行方式)->执行器)
存储引擎
性能监控
show profile …
可查看sql语句的各项资源占用,运行时间。
- 优化成本:硬件>系统配置>数据库表结构>SQL及索引。
- 优化效果:硬件<系统配置<数据库表结构<SQL及索引。
首先,对于MySQL层优化我一般遵从五个原则:
- 减少数据访问: 设置合理的字段类型,启用压缩,通过索引访问等减少磁盘IO
- 返回更少的数据: 只返回需要的字段和数据分页处理 减少磁盘io及网络io
- 减少交互次数: 批量DML操作,函数存储等减少数据连接次数
- 减少服务器CPU开销: 尽量减少数据库排序操作以及全表查询,减少cpu 内存占用
- 利用更多资源: 使用表分区,可以增加并行操作,更大限度利用cpu资源
总结到SQL优化中,就三点:
- 最大化利用索引;
- 尽可能避免全表扫描;
- 减少无效数据的查询;
避免不走索引的场景
- 避免开头字段的模糊查询
- 尽量避免使用in 和not in,会导致引擎走全表扫描
- 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描
- 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描
- 尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
- 查询条件不能用 <> 或者 !=
- where条件仅包含复合索引非前置列
- 隐式类型转换造成不使用索引
- order by 条件要与where中条件一致,否则order by不会利用索引进行排序
- 正确使用hint优化语句
- 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。
SELECT语句其他优化
- 避免出现select *
- 避免出现不确定结果的函数
- 多表关联查询时,小表在前,大表在后。
- 使用表的别名
- 用where字句替换HAVING字句
- 调整Where字句中的连接顺序
增删改DML语句优化
- 大批量插入数据
- 适当使用commit
- 避免重复查询更新的数据
- 查询优先还是更新(insert、update、delete)优先(自定义优先级)
查询条件优化
- 对于复杂的查询,可以使用中间临时表 暂存数据;
- 优化group by语句
- 优化join语句
- 优化union查询
- 拆分复杂SQL为多个小SQL,避免大事务
- 使用truncate代替delete
- 使用合理的分页方式以提高分页效率
建表优化
-
在表中建立索引,优先考虑where、order by使用到的字段。
-
尽量使用数字型字段(如性别,男:1 女:2),若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
-
查询数据量大的表 会造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段分页进行查询,循环遍历,将结果合并处理进行展示。
-
用varchar/nvarchar 代替 char/nchar
具体细节: https://chensj.blog.csdn.net/article/details/107020686














 3339
3339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









