








🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月22日9点29分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
论文链接
概述
对于一些模糊医学图像的诊断,来自一组专家的集体见解往往优于单个专家的诊断意见。对于医学图像分割任务,目前基于人工智能的方法更倾向于开发可以模仿最佳评估意见的模型,而非利用专家群体的力量。在本文中,我们介绍一种基于扩散模型的方法,其通过学习群体见解的分布来生成多个可能的诊断结果预测。
模型结构
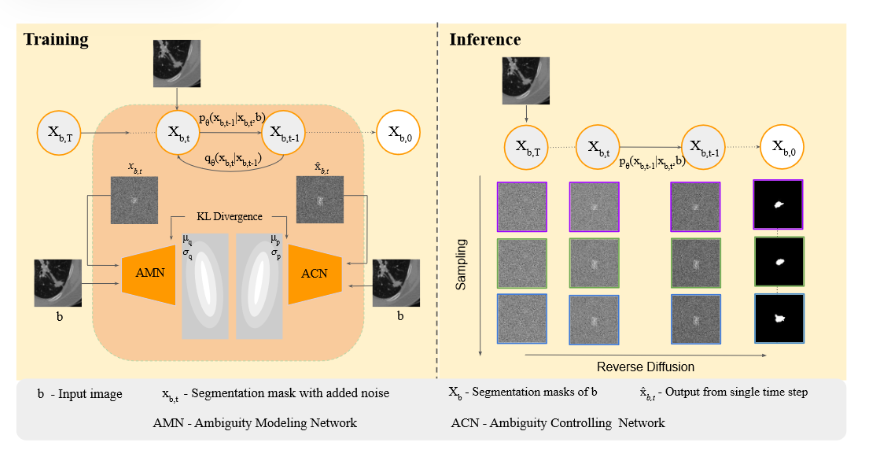
- 这里描绘了一个新颖的基于扩散模型的框架:集体医学智能扩散模型(CIMD),该模型能够真实地模型不同评估者的分割掩码的异质性,而无需在推理过程中使用任何额外的网络来提供先验信息。
- 引入了一个新的指标:CI Score(集体智慧评分)
详细结构
输入图像与扩散过程
- 输入图像:输入图像 𝑏b 的维度为 𝐶×𝐻×𝑊C×H×W,其对应的分割掩码为𝑥𝑏xb
- 扩散过程(即前向过程): 将输入图像 𝑏b 与分割掩码 𝑥𝑏,𝑡xb,t 进行拼接,记为𝑋𝑡:=𝑏⊕𝑥𝑏,𝑡Xt:=b⊕xb,t作为输入,预测该步的噪声。在每步的噪声添加过程中,噪声只添加到𝑥𝑏xb上。
不确定性建模
CIMD引入了两个模块来建模分割掩码中的不确定性和模糊性: Ambiguity Modelling Network(AMN)和Ambiguity Controlling Network(ACN)
- AMN (不确定性建模网络)
其目标是建模真实分割掩码中的模糊性
𝑧𝑞∼𝑄(⋅∣𝑏,𝑥𝑏)=𝑁(𝜇(𝑏,𝑥𝑏;𝜈),𝜎(𝑏,𝑥𝑏;𝜈)zq∼Q(⋅∣b,xb)=N(μ(b,xb;ν),σ(b,xb;ν) - ACN(不确定性控制网络)
其目标是建模预测分割掩码中的模糊性
𝑧𝑝∼𝑃(⋅∣𝑏,𝑥^𝑏)=𝑁(𝜇(𝑏,𝑥^𝑏,𝑡;𝜔),𝜎(𝑏,𝑥^𝑏,𝑡;𝜔))zp∼P(⋅∣b,x^b)=N(μ(b,x^b,t;ω),σ(b,x^b,t;ω)) - KL散度损失
通过施加一个KL散度损失来惩罚两个分布之间的差异
𝐿amb=𝐷𝐾𝐿(𝑄(𝑧∣𝑥𝑏,𝑏)∥𝑃(𝑧∣𝑥^𝑏,𝑏))Lamb=DKL(Q(z∣xb,b)∥P(z∣x^b,b))
总损失函数
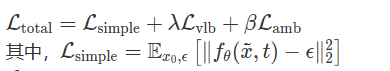
Lvlb为扩散模型的变分下界损失
𝐿ambLamb用于控制AMN和ACN之间的差异
𝜆λ 和 𝛽β是用于控制各个损失项权重的正则化参数
采样过程
将输入图像 𝑏b 和分割掩码 𝑥𝑏,𝑡xb,t的拼接作为输入,记为𝑋𝑡:=𝑏⊕𝑥𝑏,𝑡Xt:=b⊕xb,t
采样的逆向过程为
![]()
其中,𝑧z是一个从标准高斯分布𝑁(0,𝐼)N(0,I)采样的噪声。
评估指标
CI Score
CI Score 是为模糊医学图像分割设计的一种新的评估指标,用于克服传统GED(Generalized Energy Distance)指标的不足。CI Score将三种重要的评估维度结合在一起:组合灵敏度(Combined Sensitivity), 最大Dice匹配分数(Maximum Dice Matching)和多样性一致性(Diverisity Agreement)。

灵敏度(Sensitivity,或称为真阳率)在医学诊断中是一个关键指标,它衡量了模型检测出正样本(即病变区域)的能力。在实际临床实践中,来自不同医生的诊断常常会结合成一个集体决策,因此组合灵敏度即衡量所有预测的联合表现。
定义如下:
𝑌𝑐Yc:所有 ground truth 掩码的并集。
𝑌^𝑐Y^c:所有预测掩码的并集。
![]()
组合灵敏度计算公式:
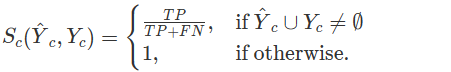
其中,𝑇𝑃TP 表示真阳性(True Positives),𝐹𝑁FN 表示假阴性(False Negatives)。
当 ground truth 和预测掩码都是空集时,灵敏度被定义为 1,因为空掩码在医学诊断中也可以被视为有效诊断.
𝐷𝑚𝑎𝑥Dmax(最大Dice匹配分数)
Dice 系数 是医学图像分割任务中常用的指标之一,用于衡量预测掩码与真实掩码之间的相似性。Dice 系数在两个掩码都为空集的情况下会被定义为 1,因为这种情况下没有病变区域。
Dice系数的定义为
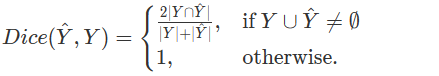
为了得到最大Dice匹配系数,模型首先计算每个ground truth与所有预测之间的Dice分数集合:
𝐷𝑖={𝐷𝑖𝑐𝑒(𝑌^1,𝑌𝑖),𝐷𝑖𝑐𝑒(𝑌^2,𝑌𝑖),…,𝐷𝑖𝑐𝑒(𝑌^𝑁,𝑌𝑖)}Di={Dice(Y^1,Yi),Dice(Y^2,Yi),…,Dice(Y^N,Yi)}
然后选择每个集合中的最大Dice分数,并取所有ground truth的平均值:
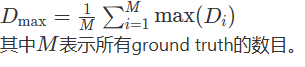
其中𝑀M表示所有ground truth的数目。
𝐷𝑎Da (多样性一致性)
多样性评估在模糊分割模型中至关重要,因为模型输出的多样性过大可能不匹配 ground truth,过小则可能表现出过于确定的行为,而不具备模糊模型应有的随机性。多样性一致性 用来量化模型生成的多样性与 ground truth 之间的一致性。
计算方法:
(1) 对于每个输入图像,计算ground truth之间的方差,得到最小方差和最大方差;(2)对预测结果做相同的操作,得到;
(3)最后计算ground truth和预测之间的方差差异:
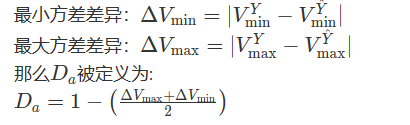
总结
- 组合灵敏度 (Sc) 评估模型检测正样本(病变区域)的能力。
- 最大 Dice 匹配分数 (Dmax) 评估预测掩码与真实掩码之间的相似性。
- 多样性一致性 (Da) 评估模型输出的多样性是否与 ground truth 的多样性相匹配。
CI score 通过调和平均将这三个维度的性能综合起来,确保模型的灵敏度、准确性和多样性都得到充分的考虑。
实验结果
该模型的分割效果如下

实现过程
在原项目的基础上,我提供了该项目在单机非分布式环境运行的版本,同时添加了模型训练时使用tensorboard可视化的部分。
注:单机非分布式环境,即为单卡环境。
相关代码及数据可以在附件中下载。
- 数据组织格式
data
└───training
│ └───0
│ │ image_0.jpg
│ │ label0_.jpg
│ │ label1_.jpg
│ │ label2_.jpg
│ │ label3_.jpg
│ └───1
│ │ ...
└───testing
│ └───3
│ │ image_3.jpg
│ │ label0_.jpg
│ │ label1_.jpg
│ │ label2_.jpg
│ │ label3_.jpg
│ └───4
│ │ ...以下是该项目在单机非分布式环境中的训练过程
- 设置环境变量(有关模型和扩散过程的一些基本设置)
export MODEL_FLAGS="--image_size 128 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16"
export DIFFUSION_FLAGS="--diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False"
export TRAIN_FLAGS="--lr 1e-4 --batch_size 20"- 训练模型,需要运行
python scripts/segmentation_train.py $TRAIN_FLAGS $MODEL_FLAGS $DIFFUSION_FLAGS- 模型的运行结果会保存至results 文件夹中。 进行模型推理,需要运行
python scripts/segmentation_sample.py --data_dir ./data/testing --model_path ./results/savedmodel.pt --num_ensemble=4 $MODEL_FLAGS $DIFFUSION_FLAGS参考文献
[1] Ambiguous Medical Image Segmentation using Diffusion Models, Aimon Rahman, Jeya Maria Jose Valanarasu et al.
部署方式
下载附件中的代码和数据,并放置在相应文件夹中
- 实验环境
Ubuntu 20.04
Python 3.9.19
torch 1.12.1+cu113
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子



















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











