








🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月24日20点03分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
概述
本文解释了SAM2要解决的PVS可提示的视觉分割任务,从模型组件开始逐步拆解SAM2,并总结了SAM1.0和SAM2.0模型的差别。本文还从代码角度讲解如何使用SAM2模型去分割图片和视频,并根据效果进行相应的输入微调,以改变输出效果。
可提示的视觉分割
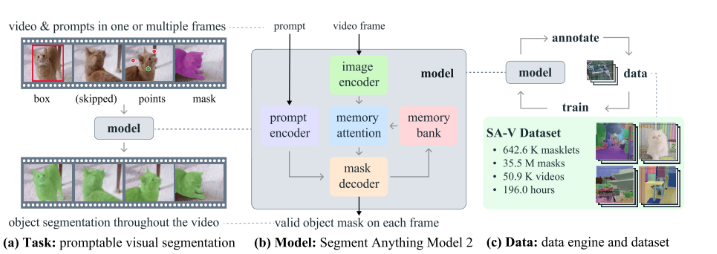
可提示的视觉分割(Promptable Visual Segmentation,PVS)任务允许用户在视频的任何一帧上向模型提供提示。这些提示可以是正/负点击、边界框或掩码,用于定义要分割的对象或细化模型预测的对象。
1.提供互动体验:当模型在特定帧上接收到提示时,它应该立即响应,生成该帧上对象的有效的分割掩码。这种即时的反馈为用户提供了一种交互式的体验。
2.初始提示:模型可以接收一个或多个初始提示,这些提示可以在同一帧上,也可以在不同的帧上。这些提示用于指示模型应该关注和分割的视频中的目标对象。
3.传播提示:在接收到初始提示后,模型应该将这些提示传播到整个视频,以生成目标对象在整个视频上的分割掩码序列,这被称为“masklet”。masklet包含了每一帧上目标对象的分割掩码。
4.额外的提示:用户可以在任何帧上提供额外的提示,以在整个视频上细化分割结果。这意味着用户可以通过提供更多的提示来帮助模型更准确地跟踪和分割对象。
SAM模型
简单回顾SAM1.0
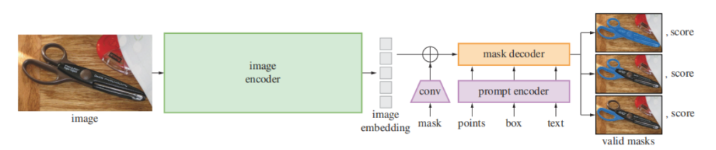
模块组成
图像编码器(Image Encoder): 这个模块用于从输入图像中提取特征。它通常是基于卷积神经网络(CNN)或Transformer架构,能够捕捉图像中的细节和上下文信息。
提示编码器(Prompt Encoder): 这个模块处理用户提供的提示。它将用户的点、框或文本提示转换为编码形式,使其能够与图像特征兼容。
任务解码器(Task Decoder): 结合图像特征和提示信息,任务解码器负责生成分割掩码。这个模块通常包含多个子网络,用于处理不同类型的提示和特征融合。
SAM2.0
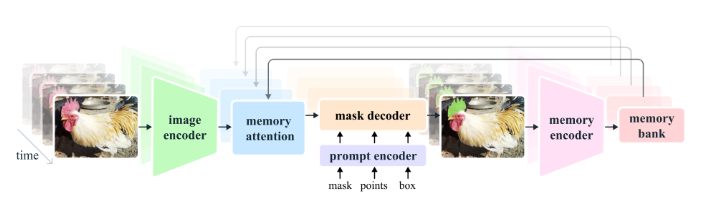
图像编码器
负责将视频帧转换为一系列的特征嵌入,这些嵌入随后可以被模型的其他部分使用,以进行视频帧的分割和目标跟踪。它的层次化设计和流式处理能力使得它非常适合于实时处理长时间的视频数据。
记忆注意力(Memory Attention)
记忆注意力(Memory Attention)的作用是调整当前帧的特征表示,使其依赖于过去帧的特征、预测结果以及任何新的提示。这意味着它能够将视频中的时间连续性考虑进来,从而更好地理解当前帧的上下文。
模型由L个transformer块堆叠而成。每个transformer块都执行特定的注意力操作。第一个transformer块接收当前帧的图像编码作为输入
提示编码器
提示编码器与SAM模型中的编码器相同,能够处理不同类型的提示,包括正/负点击、边界框或掩码,以定义给定帧中对象的范围。
对于稀疏的提示(如点击),它们通过位置编码与每种提示类型的学习嵌入相加来表示。位置编码有助于模型理解提示在图像中的具体位置。
对于掩码提示,使用卷积操作将掩码嵌入,然后将其与帧嵌入相加。这样,掩码信息就被整合到帧的特征表示中。
掩码解码器
掩码解码器的设计在很大程度上遵循了SAM模型。它使用“双向”transformer块来更新提示和帧嵌入。
对于可能产生多个兼容目标掩码的模糊提示(如单个点击),模型预测多个掩码。这种设计确保了模型输出有效的掩码。
在视频中,模糊性可能会跨越多个帧。因此,模型在每帧上预测多个掩码。如果没有后续的提示来解决这种模糊性,模型只传播具有当前帧最高预测IoU(交并比)的掩码。
记忆编码器(Memory Encoder)
记忆编码器通过使用卷积模块对输出掩码进行下采样,并将其与图像编码器提供的无条件帧嵌入进行逐元素相加,从而生成记忆。这个过程将掩码信息与原始帧的特征结合起来。之后,使用轻量级的卷积层来融合这些信息,从而创建一个包含对象分割信息的记忆表示。
记忆银行(Memory Bank)
记忆银行通过维护一个先进先出(FIFO)队列来保留视频中目标对象的过去预测信息,该队列最多包含N个最近帧的记忆。同样,记忆银行也存储来自提示的信息,这些信息存储在最多包含M个提示帧的FIFO队列中。
SAM1.0和SAM2.0差异
段落分割模型(SAM)架构包括三个主要组成部分:图像编码器、提示编码器和 Mask 解码器。图像编码器基于视觉Transformer(ViT)[10]架构。它从输入图像中提取高级特征,然后通过将这些特征划分为较小的patch并应用一系列transformer层来捕捉空间和语义信息。提示编码器设计为处理各种类型的用户输入,如点、框或文本,以引导分割过程。提示编码器处理提示并将其编码到与图像编码器提取的特征空间相匹配的特征空间中。Mask 解码器生成最后的分割预测。它将图像编码器中的特征与提示编码器中的特征结合生成最后的预测。Mask 解码器使用双向Transformer整合特征。它还包括一个IoU(交点与并集)头,预测分割 Mask 的质量。
SAM 2架构的设计是为了扩展原始SAM的功能,通过在时间序列中支持视频分割和目标跟踪。与SAM不同,SAM 2专注于单个帧的分割,而SAM 2采用了几个新的组件来处理视频数据。这些包括记忆注意、记忆编码器和记忆库。记忆注意块使用多个注意层来集成过去的帧特征和预测,而记忆编码器则创建并存储这些记忆在内存库中,以便日后参考。这种对帧嵌入的条件的设置使SAM 2可以在视频序列中保持时间连贯性。另外,SAM 2的提示编码器和 Mask 解码器可以处理空间提示,并迭代地优化分割 Mask 。然而,对于单帧图像分割,SAM和SAM 2的行为相似,SAM 2利用与SAM相同的可提示 Mask 解码器来处理帧和提示嵌入,但没有添加与视频相关的额外的时间条件特征。
SAM1.0和SAM2.0性能对比

SAM和SAM2在SA-1B和our mix数据集上的1(5)click mIoU结果。具体来说,它列出了每个模型在不同的数据集上进行单次点击时的mIoU得分,以及它们的FPS值。
从表格中可以看出,SAM在SA-1B数据集上的mIoU得分为58.1(81.3),而在our mix数据集上的mIoU得分为61.4(83.7)。SAM2在SA-1B数据集上的mIoU得分为58.9(81.7),而在our mix数据集上的mIoU得分为63.1(83.9)。
使用方式
生成全部掩码mask
def show_anns(anns, borders=True):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:, :, 3] = 0
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.5]])
img[m] = color_mask
if borders:
import cv2
contours, _ = cv2.findContours(m.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# Try to smooth contours
contours = [cv2.approxPolyDP(contour, epsilon=0.01, closed=True) for contour in contours]
cv2.drawContours(img, contours, -1, (0, 0, 1, 0.4), thickness=1)
image = Image.open('./image.jpg')
image = np.array(image.convert("RGB"))
sam2_checkpoint = "./checkpoints/sam2_hiera_tiny.pt"
model_cfg = r"./sam2_configssam2_hiera_t.yaml"
sam2 = build_sam2(model_cfg, sam2_checkpoint, device=device, apply_postprocessing=False)
mask_generator = SAM2AutomaticMaskGenerator(sam2)
masks = mask_generator.generate(image)
print(len(masks))
print(masks[0].keys())
plt.figure(figsize=(20, 20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()
单点输入
image = Image.open('./notebooks/images/groceries.jpg')
image = np.array(image.convert("RGB"))
sam2_checkpoint = "./checkpoints/sam2_hiera_tiny.pt"
model_cfg = r"D:\Desktop\segment-anything-2\sam2_configs\sam2_hiera_t.yaml"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device=device)
predictor = SAM2ImagePredictor(sam2_model)
predictor.set_image(image)
print(predictor._features["image_embed"].shape, predictor._features["image_embed"][-1].shape)
# 单点预测
input_point = np.array([[405, 265]])
input_label = np.array([1])
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False, # 当为True时,输出的mask会有三个
)
show_masks(image, masks, scores, point_coords=input_point, input_labels=input_label, borders=True)
多点预测
input_point = np.array([[405, 265],[473,261]])
input_label = np.array([1,1])
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False, # 当为True时,输出的mask会有三个
)
show_masks(image, masks, scores, point_coords=input_point, input_labels=input_label, borders=True)
多点预测(正向+负向)
input_point = np.array([[552, 231],[545,159]])
input_label = np.array([1,0])
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False, # 当为True时,输出的mask会有三个
)
show_masks(image, masks, scores, point_coords=input_point, input_labels=input_label, borders=True)
单框预测
input_box = np.array([365, 171, 443,340])
masks, scores, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box,
multimask_output=False,
)
show_masks(image, masks, scores, box_coords=input_box)
多框预测
input_box = np.array([[365, 171, 443,340], [442, 168,518,332],[354,87,426,134]])
masks, scores, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box,
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.squeeze(0), plt.gca(), random_color=True)
for box in input_box:
show_box(box, plt.gca())
plt.axis('off')
plt.show()
视频预测
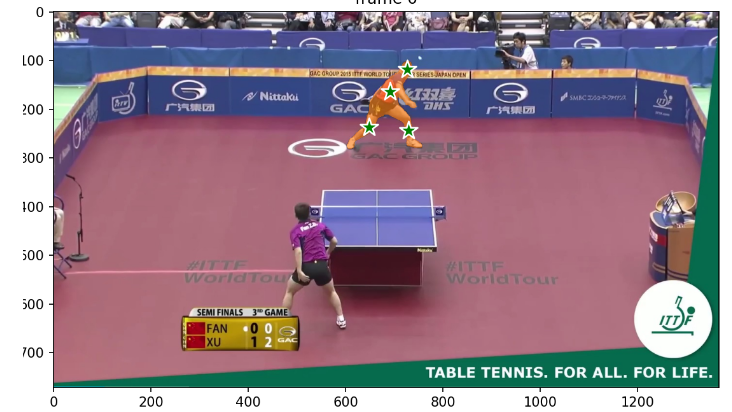
第一步:视频分帧
if not os.path.exists("./temp/images"):
os.makedirs("./temp/images")
video=cv2.VideoCapture("./video.mp4")
cnt=0
while True:
ret,frame=video.read()
if ret:
cv2.imwrite(f"./temp/images/{cnt}.jpg",frame)
cnt+=1
else:
break
video.release()第二步:走模型
frame_names = [
p for p in os.listdir(video_dir)
if os.path.splitext(p)[-1] in [".jpg", ".jpeg", ".JPG", ".JPEG"]
]
frame_names.sort(key=lambda p: int(os.path.splitext(p)[0]))
inference_state = predictor.init_state(video_path=video_dir)
predictor.reset_state(inference_state)
ann_frame_idx = 0 # the frame index we interact with
ann_obj_id = 1 # give a unique id to each object we interact with (it can be any integers)
# Let's add a positive click at (x, y) = (210, 350) to get started
points = np.array([[691, 164],[727,118],[648,237],[730,243]], dtype=np.float32)
# for labels, `1` means positive click and `0` means negative click
labels = np.array([1,1,1,1], np.int32)
_, out_obj_ids, out_mask_logits = predictor.add_new_points_or_box(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=ann_obj_id,
points=points,
labels=labels,
)
# show the results on the current (interacted) frame
# run propagation throughout the video and collect the results in a dict
video_segments = {} # video_segments contains the per-frame segmentation results
for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}
cnt=0
# render the segmentation results every few frames
vis_frame_stride = 1
plt.close("all")
for out_frame_idx in range(0, len(frame_names), vis_frame_stride):
plt.figure(figsize=(6, 4))
plt.title(f"frame {out_frame_idx}")
plt.imshow(Image.open(os.path.join(video_dir, frame_names[out_frame_idx])))
for out_obj_id, out_mask in video_segments[out_frame_idx].items():
show_mask(out_mask, plt.gca(), obj_id=out_obj_id,cnt=cnt)
cnt+=1合成视频
def create_video_from_images(image_folder, output_video_path, fps=30):
# 获取文件夹中的所有图片文件
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.png', '.jpg', '.jpeg'))]
image_files=sorted(image_files, key=lambda x: int(x[:-4]))
# 读取第一张图片以获取尺寸
img = cv2.imread(os.path.join(image_folder, image_files[0]))
height, width, _ = img.shape
# 创建 VideoWriter 对象
fourcc = cv2.VideoWriter_fourcc(*'MP4V') # 用于 MP4 格式的编解码器
video = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height))
# 将所有图片逐个写入视频
for image_file in image_files:
img = cv2.imread(os.path.join(image_folder, image_file))
video.write(img)
# 释放 VideoWriter 对象
video.release()
cv2.destroyAllWindows()
print(f"Video saved as {output_video_path}")
微调模型
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
sam2_checkpoint = "./checkpoints/sam2_hiera_tiny.pt"
model_cfg = r"D:\Desktop\segment-anything-2\sam2_configs\sam2_hiera_t.yaml"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device=device)
predictor = SAM2ImagePredictor(sam2_model)
"""
for epoch in range(epoches):
# 加载符合模型数据集标准的数据:每一次输入是一个列表,每一项是一个字典
# 字典包括:"image",("point_coords","point_label"),("boxes"),("mask_inputs")
for data in train_dataloader:
output=sam(data)
loss=loss_function(output,mask)
optimiezer.zero_gard()
loss.backward()
optimiezer.step()
"""成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子



















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











