







FastChat简介
FastChat is an open platform for training, serving, and evaluating large language model based chatbots.
- FastChat powers Chatbot Arena, serving over 10 million chat requests for 70+ LLMs.
- Chatbot Arena has collected over 500K human votes from side-by-side LLM battles to compile an online LLM Elo leaderboard.
FastChat’s core features include
- The training and evaluation code for state-of-the-art models (e.g., Vicuna, MT-Bench).
- A distributed multi-model serving system with web UI and OpenAI-compatible RESTful APIs.
FastChat Github地址: https://github.com/lm-sys/FastChat
FastChat架构:https://github.com/lm-sys/FastChat/blob/main/docs/server_arch.md
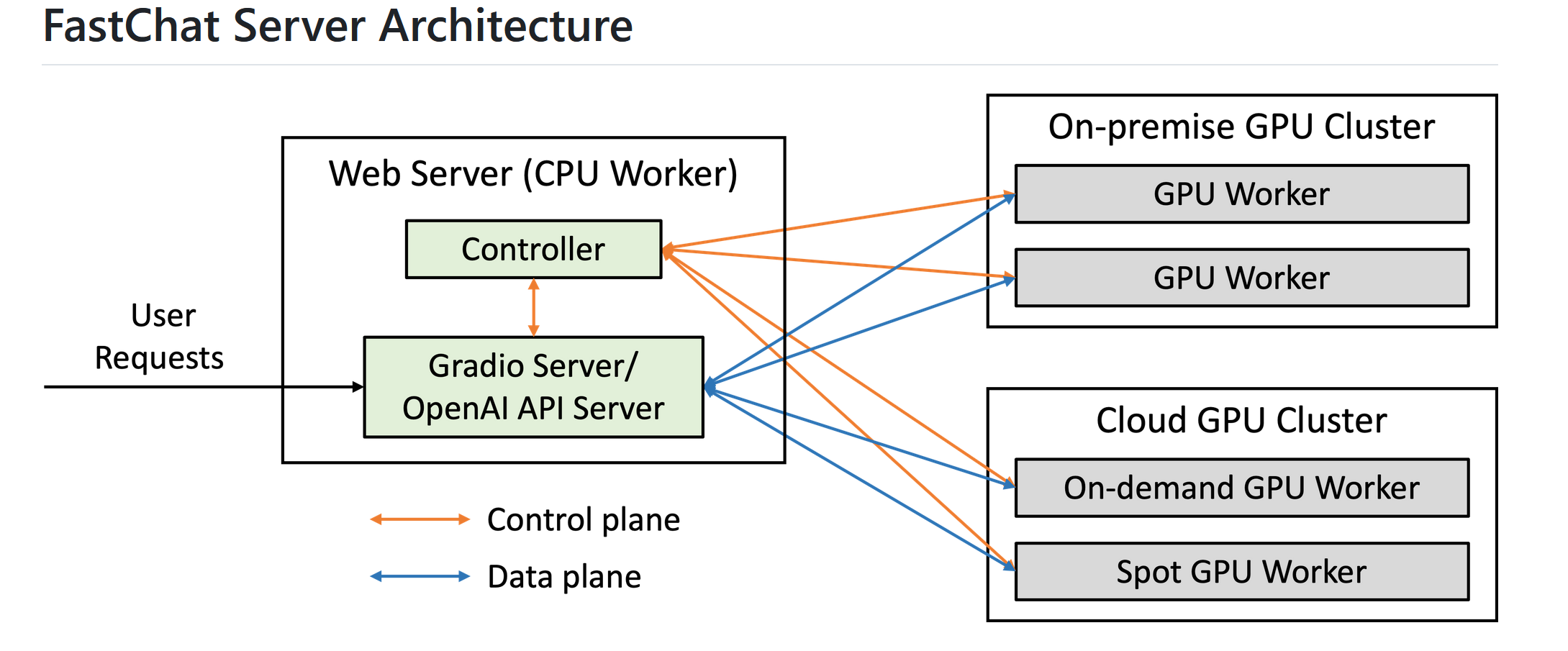
安装FastChat
pip3 install "fschat[model_worker,webui]"
如果网速较慢或无网就使用国内镜像如:
#阿里源
pip3 install "fschat[model_worker,webui]" -i https://mirrors.aliyun.com/pypi/simple/
#清华源
pip3 install "fschat[model_worker,webui]" -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 下载模型到本地
这里以通义千问1.8b为例,其他模型类似,就是文件大小大了些,可以通过huggingface或modelscope两个网站进行下载
https://www.modelscope.cn/qwen/Qwen-1_8B-Chat.git
https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat
比如把模型下载到/home/liu/目录
#cd到目录
cd /home/liu/
#大文件下载需要执行以下:
git lfs install
#先下小文件,先用命令把小文件下了
GIT_LFS_SKIP_SMUDGE=1 git https://www.modelscope.cn/qwen/Qwen-1_8B-Chat.git
#然后cd进去文件夹,下大文件,每个大文件之间可以续传,大文件内部不能续传,以下命令下载所有的大文件
git lfs pull
#上面的git lfs pull是下载所有的大文件,可能你只需要下载模型下的部分大文件,可以通过git lfs pull指定匹配模式,下载部分文件,比如
#下载bin结尾文件
git lfs pull --include="*.bin"
#如果你只想要单个文件,写文件名就可以,比如
git lfs pull --include "model-00001-of-00004.safetensors"
注: 如果上面的git lfs pull不成功或报错如git: ‘lfs’ is not a git command. See ‘git --help’.,可能是因为没有安装git lfs,执行安装即可,并执行git lfs install
sudo apt-get install git-lfs
启动服务(OpenAI-Compatible RESTful APIs)
官网参考:https://github.com/lm-sys/FastChat/blob/main/docs/openai_api.md
# 1.启动controller,默认端口为21001,可通过 --port 指定。
python3 -m fastchat.serve.controller > controller.log 2>&1 &
# 2.启动model_worker,默认端口为21002,可通过 --port 指定,model_worker会向controller注册。
python3 -m fastchat.serve.model_worker --model-path /home/liu/Qwen-1_8B-Chat --model-name=Qwen-1_8B-Chat --num-gpus 1 > model_worker.log 2>&1 &
# 3.启动openai_api_server,默认端口为 8000,可通过 --port 指定。
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 9000 > openai_api_server.log 2>&1 &
# 4.(可选),如果还需要web界面,启动gradio_web_server,默认端口为 7860,可通过 --port 指定。
python3 -m fastchat.serve.gradio_web_server > gradio_web_server.log 2>&1 &
注:
--num-gpus 指定运行模型的gpu个数
--model-name 默认以部署的model-path作为模型名称,可通过--model-name修改,比如--model-name Qwen
Api访问测试
python脚本测试
pip install openai
import openai
openai.api_key = "EMPTY"
openai.base_url = "http://localhost:9000/v1/"
model = "Qwen-1_8B-Chat"
prompt = "Once upon a time"
# create a completion
completion = openai.completions.create(model=model, prompt=prompt, max_tokens=64)
# print the completion
print(prompt + completion.choices[0].text)
# create a chat completion
completion = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)
python流式输出测试
from openai import OpenAI
client = OpenAI(base_url="http://localhost:9000/v1", api_key="")
model = "Qwen-1_8B-Chat"
completion = client.chat.completions.create(
model = model,
messages=[
{
"role": "user",
"content": "Hello",
}
],
stream=True
)
for chunk in completion:
if chunk.choices[0].finish_reason == "stop":
break
else:
print(chunk.choices[0].delta.content, end="", flush=True)
curl调用接口测试
curl -X POST http://0.0.0.0:9000/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"Qwen-1_8B-Chat\", \"messages\": [{\"role\": \"user\", \"content\": \"hello?\"}]}"


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









