









一、树

1.只有一个特殊节点,它没有父节点,它就是根节点
2.每一个非根节点有且只有一个父节点
3.每个节点包含多个指针指向其子节点
4.该例子有3层,40那一层,130那一层,10那一层,故该数的深度为3。
5.没有子节点的叫叶子节点。
6.拥有相同父节点的叫兄弟节点。
二、二叉树

在树的基础上多了些限制条件:
1.每个节点最多只能有2个子节点。
2.节点的子节点,分为左孩子节点和右孩子节点。
2.1 完全二叉树

在二叉树的基础上多了一个限制:
除最后一层外,若其余层都是满的,并且最后一层要么是满的,要么是在右边缺少连续若干节点
2.2 满二叉树

在二叉树的基础上多了两个限制:
所有分支结点都存在左子树和右子树。
所有叶子结点都在同一层上。
三、二叉查找树

在二叉树的基础上多了些限制条件
1.任何一个节点,如果它的左子树不为空,则左子树上所有节点的值都比它小
2.任何一个节点,如果它的右子树不为空,则右子树上所有节点的值都比它大
3.对于任意一个子树:左<根<右
查找效率与树的高度成反比。
二叉查找树(其实这是二叉树的遍历)的遍历分为:
1.深度优先遍历(Depth First Search)
对于一颗二叉树,深度优先搜索是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
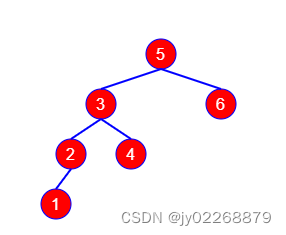
1.前序遍历: 根节点----左子树----右子树
以上图为例,结果是:80,40,10,50,115,90,95,130
2.中序变量: 左子树----根节点----右子树 在二叉查找树中使用序遍历并且打印的时候,最后打印出的结果会是从小到大的
以上图为例,结果是:10,40,50,80,90,95,115,130
3.后序遍历: 左子树----右子树----根节点
以上图为例,结果是:10,50,40,95,90,130,115,80
2.广度优先遍历(Breadth-First Search)
从树的root开始,从上到下从从左到右遍历整个树的节点
1.层次遍历:按层次遍历
以上图为例,结果是:80,40,115,10,50,90,130,95
3.删除节点
1.删除叶子节点。直接删。不会破坏BST的结构
2.删除带有一个子节点的的节点。将待删除节点的左/右子树 赋值给 待删除节点的父节点的左/右子树
3.删除带两个子节点的节点
首先需要找到待删除节点的后继节点和该后继节点的父节点,(一个节点的后继节点是指,这个节点在中序遍历序列中的下一个节点,相应的,前驱节点是指这个节点在中序遍历序列中的上一个节点)。
由于二叉查找树的性质,如果将当前节点替换为左子树中最大的或者右子树中最小的一定不会破坏二叉查找树的结构。
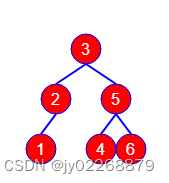
下图是删除5号节点

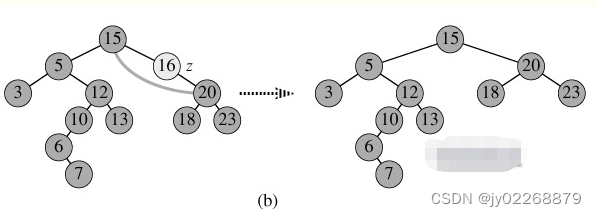
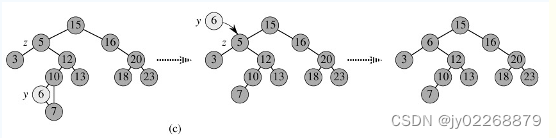
四、平衡二叉查找树(AVL)
平衡二叉查找树:
在二叉查找树的基础上多了些限制:
1.所有叶子的深度趋于平衡
2.每个节点的左子树和右子树的深度差的绝对值不超过1
平衡二叉树是在二叉查找树上引入是为了解决二叉排序树的不平衡性导致时间复杂度大大下降
不平衡的二叉查找树可能会出现极端情况编程链表:

针对上面不平衡的二叉查找树调整成平衡树,主要是通过旋转最小失衡子树来完成。
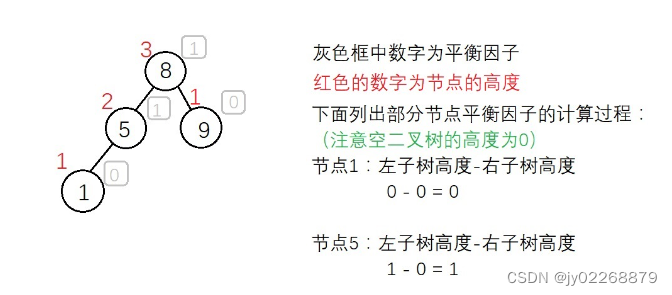
1、平衡因子:左子树的高度减去右子树的高度。
2、失衡:每个结点的左右子树的高度之差的绝对值超过13、最小失衡子树:离新插入的节点最近的,平衡因子最小的子树称为最小失衡子树。
旋转:
左旋和右旋:
左旋:把“最小失衡根结点”的右孩子节点A“提上去”,使得原来的“最小失衡根结点”成为节点A的左孩子节点。
右旋:把“最小失衡根结点”的左孩子节点A“提上去”,使得原来的“最小失衡根结点”成为节点A的右孩子节点。


插入节点时分四种情况,四种情况对应的旋转方法是不同的:
例如对于被破坏平衡的节点 a 来说:
| 插入方式 | 描述 | 旋转方式 |
| LL型 | 在a的左子树根节点的左子树上插入节点而破坏平衡
| 右旋 LL型旋转的对象是“最小失衡根结点”,也就是结点5。 个人理解1:就是把“最小失衡根结点”的左子节点“提上去”。
|
| RR型 | 在a的右子树根节点的右子树上插入节点而破坏平衡
| 左旋 RR型旋转的对象是“最小失衡根结点”,也就是结点2。 个人理解:所谓右旋转就是把“最小失衡根结点”的右子节点“提上去”。
|
| LR型 | 在a的左子树根节点的右子树上插入节点而破坏平衡
| 先RR旋转,再LL旋转。 第一步旋转对象是“最小失衡根结点”的左子节点,也就是结点2,对它进行RR型旋转。 即是把2节点的右节点提上去。
第二步旋转对象是“最小失衡根结点”,也就是结点5,对它进行LL型旋转。 即是把节点5的左子节点提上去
|
| RL型 | 在a的右子树根节点的左子树上插入节点而破坏平衡
| 先LL旋转,再RR旋转。 第一步旋转对象是“最小失衡根结点”的右子节点,也就是结点5,对它进行LL型旋转。 即是把5节点的左节点提上去。
第二步旋转对象是“最小失衡根结点”,也就是结点2,对它进行RR型旋转。 即是把节点2的右子节点提上去
|

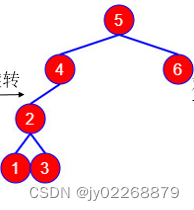
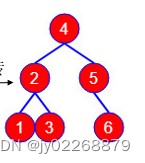

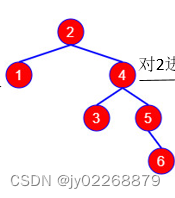
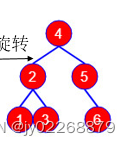
以上面那个不平衡的二叉查找树为例:
在有10和11时,再插入12
本来二叉查找树是这样:
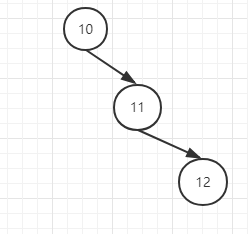
调整逻辑:
这是在节点10的右子树根节点11的右子树上插入节点12,属于RR型,则此时,以10为根节点,将10的右子节点11提上去:
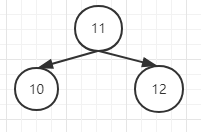
然后插入13,并未导致失衡

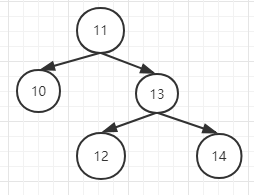
然后插入14,变成了下图这样,导致失衡,需要旋转来调整

调整逻辑:
1.找离新插入的节点最近的平衡因子最小的失衡子树,即是12->13->14。
这里说一下是怎么找的,11的失衡因子是-2,12的失衡因子是-2,13的失衡因子是-1。所以最小失衡因子是-2,
由于12离新插入的节点最近,所以,最终选出来的离新插入的节点最近的平衡因子最小的失衡子树是12->13->14,是一个RR型。
2.以12为中心,将12的右子节点(即13)提上去:
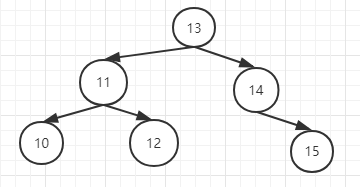
最后插入15,又会导致失衡

调整逻辑:
1.找离新插入的节点最近的平衡因子最小的失衡子树,即是11->13->14->15。
这里说一下是怎么找的,11的失衡因子是-2,13的失衡因子是-1,14的失衡因子是-1。所以最小失衡因子是-2,
最终选出来的离新插入的节点最近的平衡因子最小的失衡子树是11->13->14->15。
是RR型
2.以11为中心,把11的右子节点13提上去
删除节点时
删除节点的分类场景跟二叉查找树一样,删了以后如果破环了平衡,则做相应的旋转。
例子可参考这篇AVL树删除,详细图解_Adsh的博客-CSDN博客_avl树删除
五、2-3树
一个节点下有2条链(2个孩子节点),叫2-节点(2-node),比如下图的R
一个节点下有3条链(3个孩子节点),叫3-节点(3-node),比如下图的EJ
节点的左链比节点小,节点的右链比节点大,节点的中链大小在该节点内的两个值之间
2-3查找树的性质:
1)如果中序遍历2-3查找树,就可以得到排好序的序列;
2)在一个完全平衡的2-3查找树中,根节点到每一个为空节点的距离都相同。(这也是平衡树中“平衡”一词的概念,根节点到叶节点的最长距离对应于查找算法的最坏情况,而平衡树中根节点到叶节点的距离都一样,最坏情况也具有对数复杂度。)
性质2)如下图所示:
复杂度分析:
2-3树的查找效率与树的高度是息息相关的。
在最坏的情况下,也就是所有的节点都是2-node节点,查找效率为lgN
在最好的情况下,所有的节点都是3-node节点,查找效率为log3N约等于0.631lgN
距离来说,对于1百万个节点的2-3树,树的高度为12-20之间,对于10亿个节点的2-3树,树的高度为18-30之间。
对于插入来说,只需要常数次操作即可完成,因为他只需要修改与该节点关联的节点即可,不需要检查其他节点,所以效率和查找类似。
插入操作
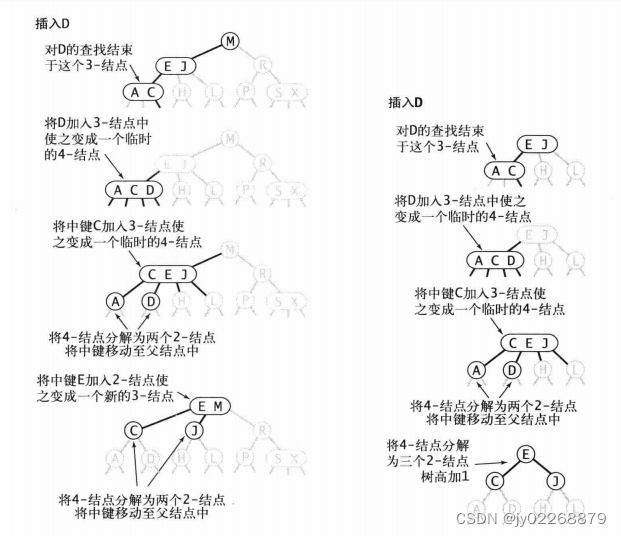
局部变换

六、红黑树
数据结构:用2-3树来理解红黑树_哔哩哔哩_bilibili
直接实现2-3树比较复杂和麻烦,由此2-3树转变为红黑树
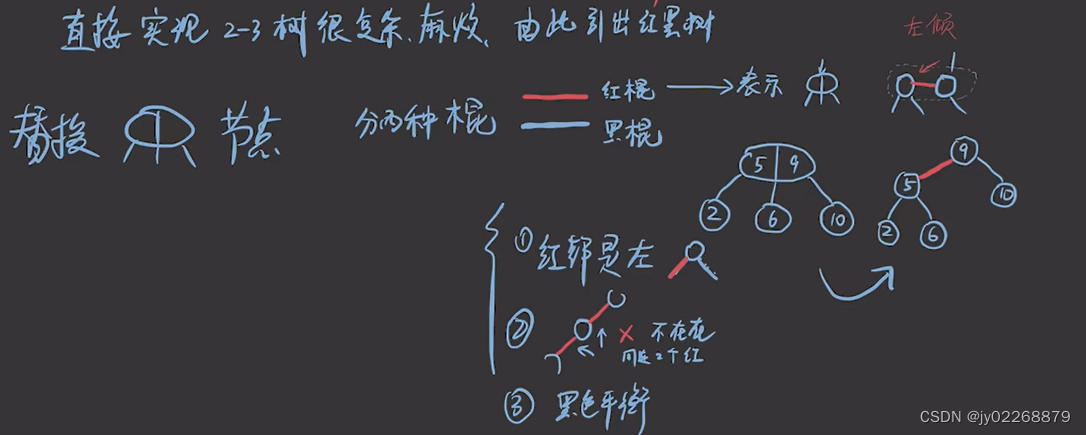
红棍指向的节点就是红色节点
 红黑树定义
红黑树定义


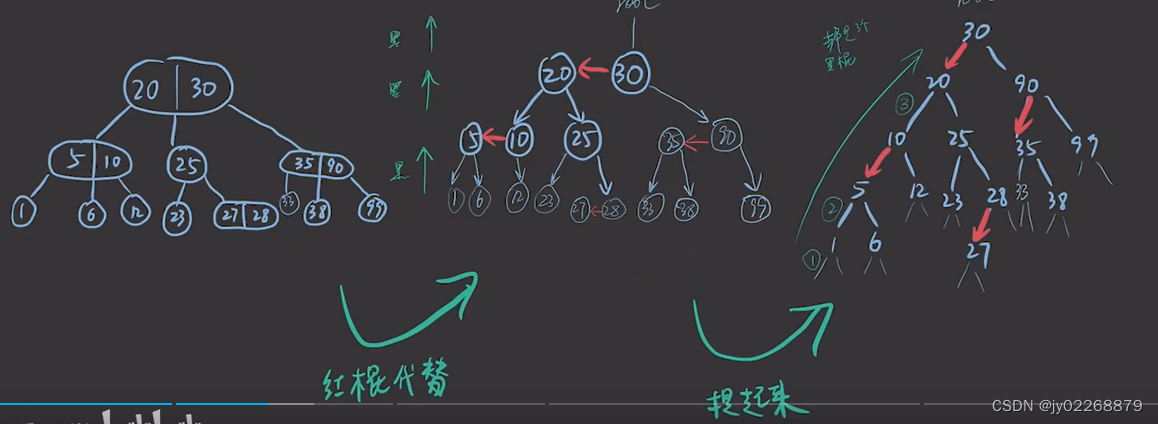
红黑树旋转
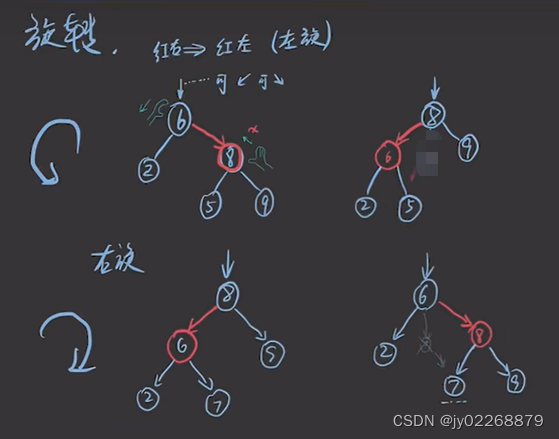
插入引发旋转
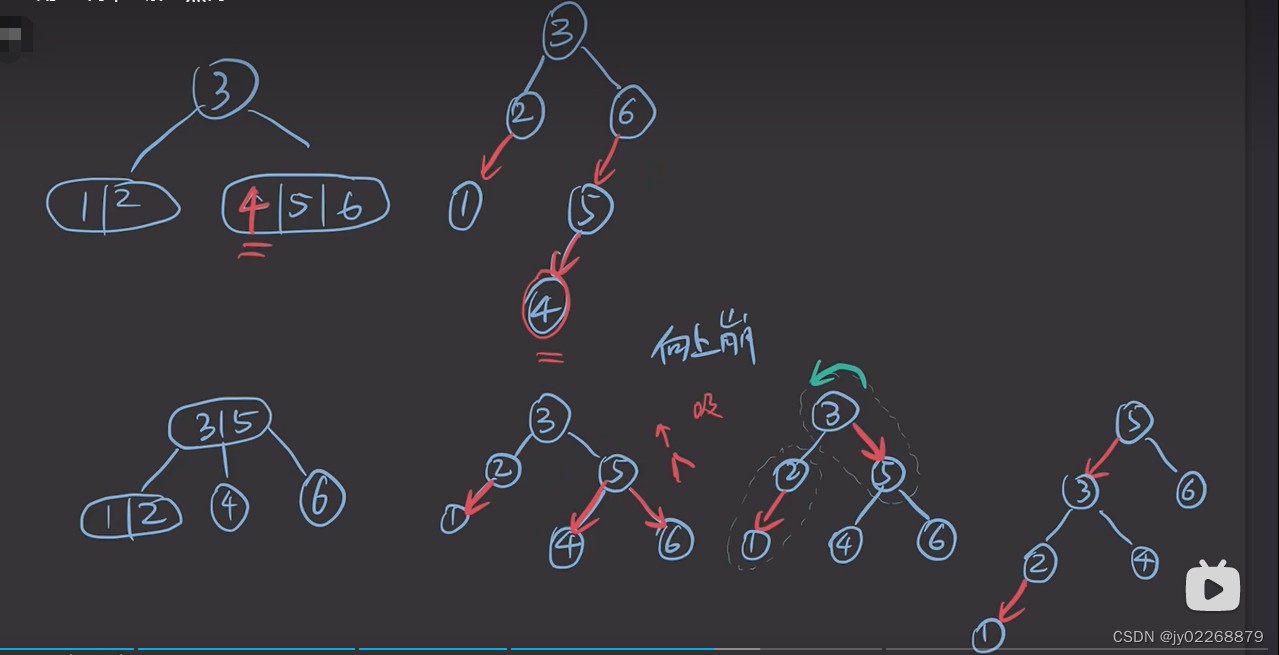
红色节点如果在右边则要通过左旋转给转到左边,红色节点只能在左边
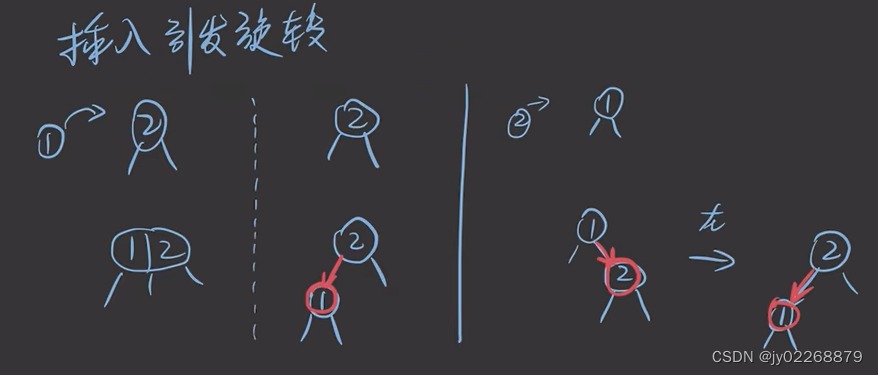
新插入的节点只能是红色。
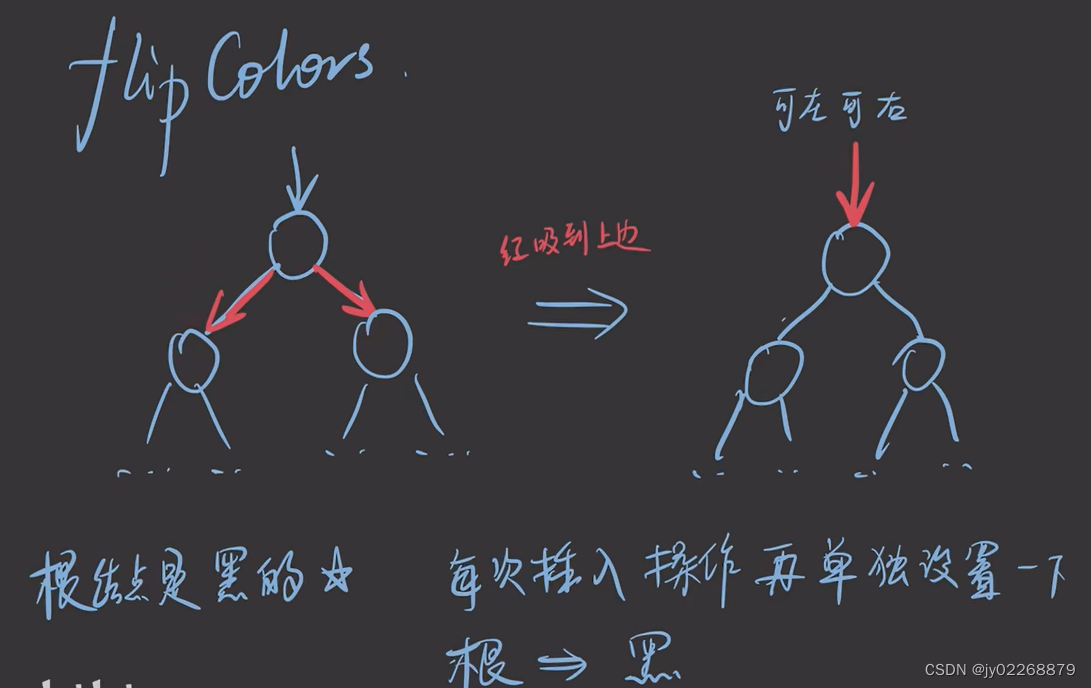
如果一个节点A的两个孩子节点B.C都是红色,则变色:两个孩子节点B.C变为黑色,A变为红色
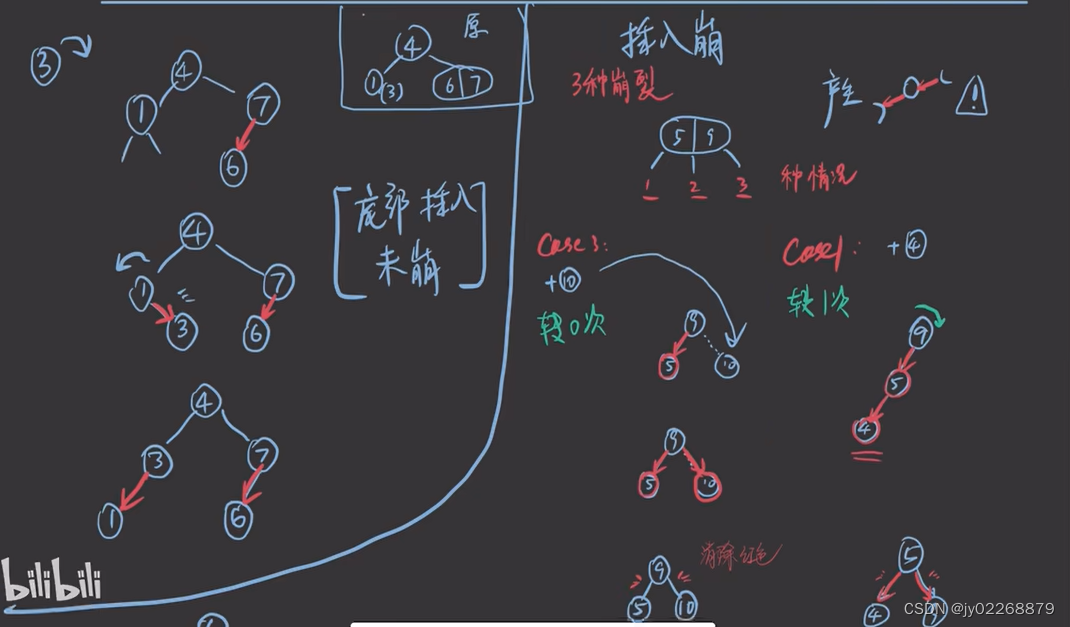
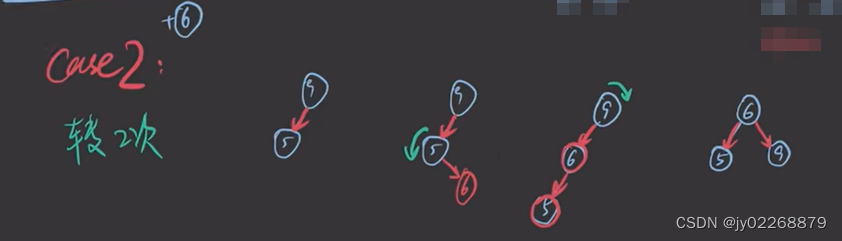
一个整体的例子
插入4
六、B树(B-Tree、Balance Tree)
B-树就是B树,不是读什么B减树。
平衡多叉查找树
B树的阶数表示一个节点最多可以有多少个孩子节点。比如3阶B树,那一个节点最多可以有3个孩子节点。2阶B树相当于平衡二叉查找树。
图示3阶B树

一个M阶的B树符合以下条件:
1.根节点至少有2个孩子节点
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
B树插入:
比如以上方图示例子为例,插入一个25
第三排第二个节点,已经有了2个元素,23和36了,不能再放元素进去了(3阶B树,每个节点内最多只能是3-1=2个元素)
向上找,它的父节点,第二排第一个节点,也有两个元素20和40了,不能再放元素进去了。
再向上找,它的父节点就是根节点,第一排第一个节点,里面只有一个元素,还能再放一个元素进去,把新增的25插入根节点,拆分节点23.36和节点20.40.使其符合(左边大于右边)最后变成:

七、B+树
MySQL的Innodb的BTree索引就是用B+树实现的
这里标红高亮:之前去一家公司面试,第一轮面试官死活给我说Java8的ConcurrentHashMap就用CAS就能实现线程安全
第二轮,CTO给我说MySQL的Innodb的索引是用红黑树实现的。我有点怀疑人生。
不用红黑树的原因:
1.红黑树之类的这种平衡、近似平衡的二叉查找树,查找的效率跟树的高度相关。
2.数据库的索引是存在磁盘上的,需要考虑磁盘开销。用索引查找的时候不是把整个索引加到内存中,而是逐个加载磁盘页。一个磁盘页对应着索引树上的一个节点。
故:最坏的情况下,如果树高度为N,那么我们可以就要做N次磁盘IO开销。
3.当B+树节点中元素的数量多的时候,虽然查询是比较次数比二叉查找树、红黑树多,但是和磁盘IO速度相比,内存多耗时这点点是可以忽略的。

在B树的基础上:
1.B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
2.B+树与B树最大的不同是内部结点不保存数据,只用于索引,MySQL的数据(或者说记录)都保存在叶子结点中。
3.每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字(MySQL表中建索引的那一列的值)的大小形成一个顺序链接。















 1625
1625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









