







目录
1.MySQL调优金字塔
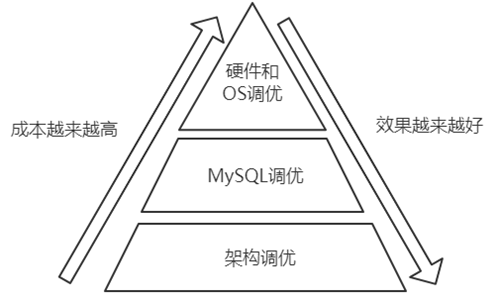
很明显从图上可以看出,越往上走,难度越来越高,收益却是越来越小的。
对于架构调优,在系统设计时首先需要充分考虑业务的实际情况,是否可以把不适合数据库做的事情放到数据仓库、搜索引擎或者缓存中去做;然后考虑写的并发量有多大,是否需要采用分布式;最后考虑读的压力是否很大,是否需要读写分离。对于核心应用或者金融类的应用,需要额外考虑数据安全因素,数据是否不允许丢失。所以在进行优化时,首先需要关注和优化的应该是架构,如果架构不合理,即使是DBA能做的事情其实是也是比较有限的。
对于MySQL调优,需要确认业务表结构设计是否合理,SQL语句优化是否足够,该添加的索引是否都添加了,是否可以剔除多余的索引等等
比如硬件和OS调优,需要对硬件和OS有着非常深刻的了解,仅仅就磁盘一项来说,一般非DBA能想到的调整就是SSD盘比用机械硬盘更好。DBA级别考虑的至少包括了,使用什么样的磁盘阵列(RAID)级别、是否可以分散磁盘IO、是否使用裸设备存放数据,使用哪种文件系统(目前比较推荐的是XFS),操作系统的磁盘调度算法选择,是否需要调整操作系统文件管理方面比如atime属性等等。
所以本章我们重点关注MySQL方面的调优,特别是索引。SQL/索引调优要求对业务和数据流非常清楚。在阿里巴巴内部,有三分之二的DBA是业务DBA,从业务需求讨论到表结构审核、SQL语句审核、上线、索引更新、版本迭代升级,甚至哪些数据应该放到非关系型数据库中,哪些数据放到数据仓库、搜索引擎或者缓存中,都需要这些DBA跟踪和复审。他们甚至可以称为数据架构师(Data Architecher)。
2.查询性能优化
前面的章节我们知道如何设计最优的库表结构、如何建立最好的索引,这些对于高性能来说是必不可少的。但这些还不够—还需要合理的设计查询。如果查询写得很糟糕,即使库表结构再合理、索引再合适,也无法实现高性能。
2.1.什么是慢查询
慢查询日志,顾名思义,就是查询花费大量时间的日志,是指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志。该日志能为SQL语句的优化带来很好的帮助。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。如何开启,我们稍后再说。
2.1.1慢查询基础-优化数据访问
查询性能低下最基本的原因是访问的数据太多。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,一般通过下面两个步骤来分析总是很有效:
1.确认应用程序是否在检索大量超过需要的数据。这通常意味着访问了太多的行,但有时候也可能是访问了太多的列。
2.确认MySQL服务器层是否在分析大量超过需要的数据行。
2.1.2请求了不需要的数据?
有些查询会请求超过实际需要的数据,然后这些多余的数据会被应用程序丢弃。这会给MySQL服务器带来额外的负担,并增加网络开销,另外也会消耗应用服务器的CPU和内存资源。比如:
查询不需要的记录
一个常见的错误是常常会误以为MySQL会只返回需要的数据,实际上MySQL却是先返回全部结果集再进行计算。我们经常会看到一些了解其他数据库系统的人会设计出这类应用程序。
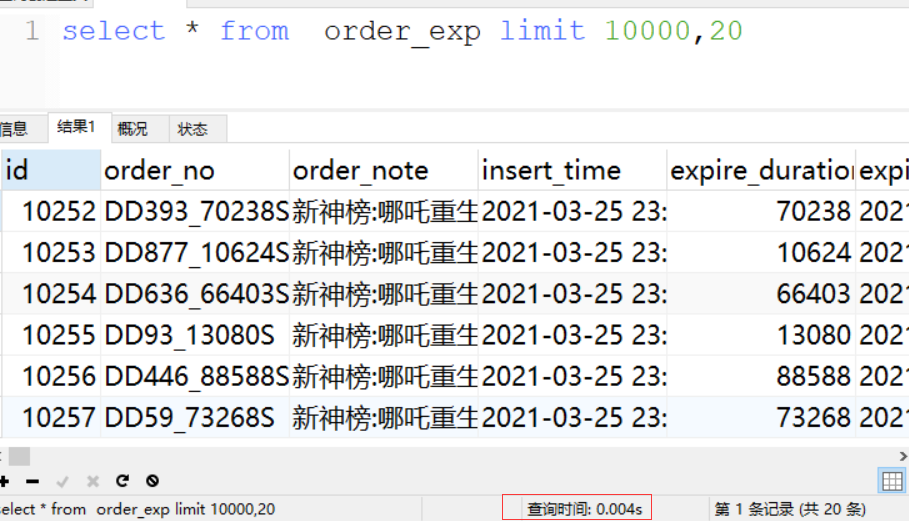
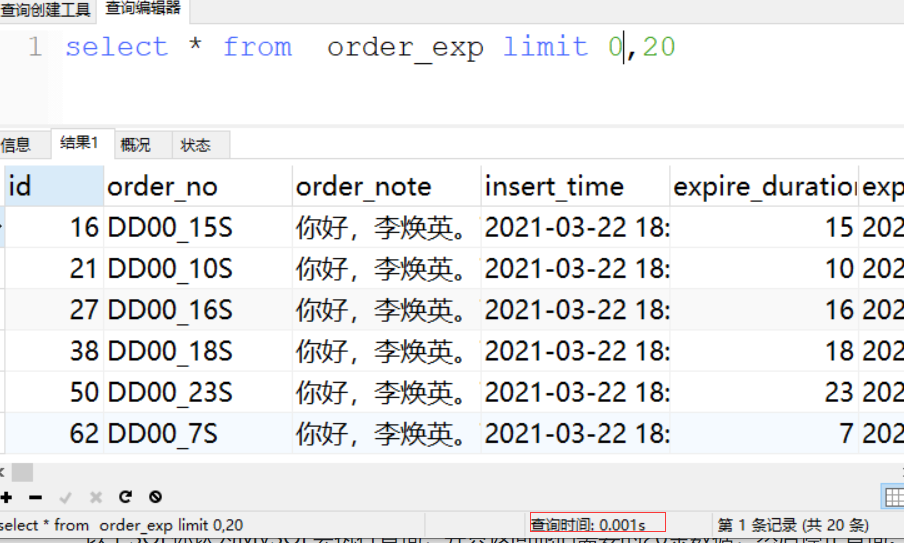
以上SQL你认为MySQL会执行查询,并只返回他们需要的20条数据,然后停止查询。实际情况是MySQL会查询出全部的结果集,客户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。
总是取出全部列
每次看到SELECT*的时候都需要用怀疑的眼光审视,是不是真的需要返回全部的列?很可能不是必需的。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU的消耗。因此,一些DBA是严格禁止SELECT *的写法的,这样做有时候还能避免某些列被修改带来的问题。
尤其是使用二级索引,使用*的方式会导致回表,导致性能低下。
什么时候可以使用SELECT*如果应用程序使用了某种缓存机制,或者有其他考虑,获取超过需要的数据也可能有其好处,但不要忘记这样做的代价是什么。获取并缓存所有的列的查询,相比多个独立的只获取部分列的查询可能就更有好处。
重复查询相同的数据
不断地重复执行相同的查询,然后每次都返回完全相同的数据。比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出,这样性能显然会更好。
2.1.3.是否在扫描额外的记录
在确定查询只返回需要的数据以后,接下来应该看看查询为了返回结果是否扫描了过多的数据。对于MySQL,最简单的衡量查询开销的三个指标如下:
响应时间、扫描的行数、返回的行数
没有哪个指标能够完美地衡量查询的开销,但它们大致反映了MySQL在内部执行查询时需要访问多少数据,并可以大概推算出查询运行的时间。这三个指标都会记录到MySQL的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法。
响应时间
响应时间是两个部分之和:服务时间和排队时间。
服务时间是指数据库处理这个查询真正花了多长时间。
排队时间是指服务器因为等待某些资源而没有真正执行查询的时间—-可能是等I/O操作完成,也可能是等待行锁,等等。
扫描的行数和返回的行数
分析查询时,查看该查询扫描的行数是非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。
理想情况下扫描的行数和返回的行数应该是相同的。但实际情况中这种“美事”并不多。例如在做一个关联查询时,服务器必须要扫描多行才能生成结果集中的一行。扫描的行数对返回的行数的比率通常很小,一般在1:1和10:1之间,不过有时候这个值也可能非常非常大。
扫描的行数和访问类型
在评估查询开销的时候,需要考虑一下从表中找到某一行数据的成本。MySQL有好几种访问方式可以查找并返回一行结果。有些访问方式可能需要扫描很多行才能返回一行结果,也有些访问方式可能无须扫描就能返回结果。
在EXPLAIN语句中的type列反应了访问类型。访问类型有很多种,从全表扫描到索引扫描、范围扫描、唯一索引查询、常数引用等。这里列的这些,速度是从慢到快,扫描的行数也是从小到大。你不需要记住这些访问类型,但需要明白扫描表、扫描索引、范围访问和单值访问的概念。
如果查询没有办法找到合适的访问类型,那么解决的最好办法通常就是增加一个合适的索引,为什么索引对于查询优化如此重要了。索引让 MySQL以最高效、扫描行数最少的方式找到需要的记录。
一般 MySQL能够使用如下三种方式应用WHERE条件,从好到坏依次为:
1、在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。
select .... from where a>100 and a <200
2、使用覆盖索引扫描来返回记录,直接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











