






测试结论:
| 序号 | 模型名称 | 模型大小 | 显存占用 | 8卡910B4-32G(256G) | 备注 |
| 是否支持? | |||||
| 1 | Qwen2.5-VL-32B-Instruct | 64G | 188G | 支持 | You are using a model of type qwen2_5_vl to instantiate a model of type . This is not supported for all configurations of models and can yield errors. |
| quay.io/ascend/vllm-ascend:v0.7.3 | Daemon start success! | ||||
| (https://vllm-ascend.readthedocs.io/en/stable/tutorials/single_npu_multimodal.html) | 32B的图像识别效果不满足要求,没必要继续测试,肯定支持 | ||||
| swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts (https://modelers.cn/models/Models_Ecosystem/Qwen2.5-VL-32B-Instruct) | |||||
| 2 | Qwen2.5-VL-72B-Instruct | 137G | vllm框架下占用:208G | MindIE不支持(单卡分配提示显存不足) | MindIE: |
| swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts | 4或8卡910B4-64G理论上可支持。 | ||||
| RuntimeError: NPU out of memory. Tried to allocate 602.00 MiB (NPU 5; 29.50 GiB total capacity; 28.10 GiB already allocated; 28.10 GiB current active; 441.27 MiB free; 28.44 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. | |||||
| VLLM支持 | vllm: | ||||
| quay.io/ascend/vllm-ascend:v0.7.3 | 输出不了json格式: | ||||
| (乱回答:quay.io/ascend/vllm-ascend:v0.8.5rc1) | WARNING 05-28 01:37:36 __init__.py:48] xgrammar is only supported on x86 CPUs. Falling back to use outlines instead. | ||||
| WARNING 05-28 01:37:36 __init__.py:84] xgrammar module cannot be imported successfully. Falling back to use outlines instead. | |||||
| WARNING 05-28 01:37:36 __init__.py:91] outlines does not support json_object. Falling back to use xgrammar instead. | |||||
| INFO: 219.141.177.34:2272 - "POST /v1/chat/completions HTTP/1.1" 500 Internal Server Error | |||||
| ERROR: Exception in ASGI application | |||||
| 3 | Qwen2.5-VL-72B-Instruct-AWQ | 41G | / | 都不支持 | MindIE:raise AssertionError(f"weight {tensor_name} does not exist") |
| >>> Exception:weight model.layers.0.self_attn.q_proj.weight does not exist | |||||
| vllm:ERROR 05-28 05:49:02 engine.py:400] KeyError: 'visual.blocks.0.attn.qkv.weight' |
测试命令:
| 推理框架镜像 | 启动命令 | 测试命令 |
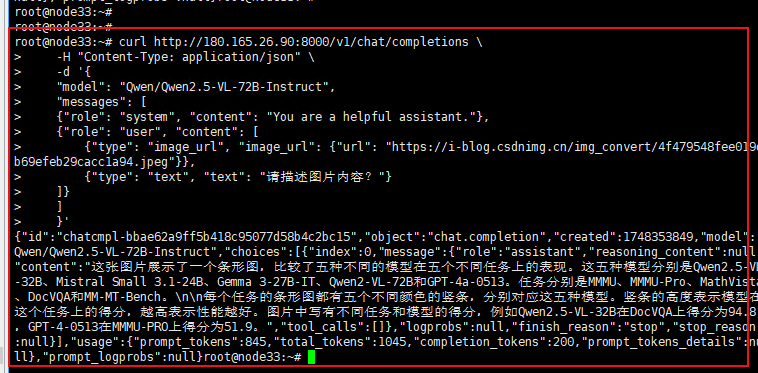
| quay.io/ascend/vllm-ascend:v0.7.3 | 启动容器: docker run \ --name vllm-ascend \ --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 \ --device /dev/davinci_manager \ --device /dev/devmm_svm \ --device /dev/hisi_hdc \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \ -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \ -v /etc/ascend_install.info:/etc/ascend_install.info \ -v /root/.cache:/root/.cache \ -p 8000:8000 \ -itd quay.io/ascend/vllm-ascend:v0.7.3 进入容器: docker exec -it vllm-ascend bash 启动vllm服务: vllm serve Qwen/Qwen2.5-VL-32B-Instruct --tokenizer_mode="auto" --tokenizer_mode="auto" --dtype=bfloat16 --max_num_seqs=256 --tensor_parallel_size=8 --gpu-memory-utilization=0.98 --max-model-len=32768 & 停vllm服务: ps -ef|grep python3|grep -v grep|awk '{print $2}'|xargs kill -9 停容器: docker stop vllm-ascend docker rm vllm-ascend | curl http://110.165.26.90:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen2.5-VL-72B-Instruct", "messages": [ {"role": "system", "content": "你是专业图片识别助手"}, {"role": "user", "content": [ {"type": "image_url", "image_url": {"url": "https://i-blog.csdnimg.cn/img_convert/4f479548fee019db69efeb29cacc1a94.jpeg"}}, {"type": "text", "text": "请描述图片内容?"} ]} ] }' |
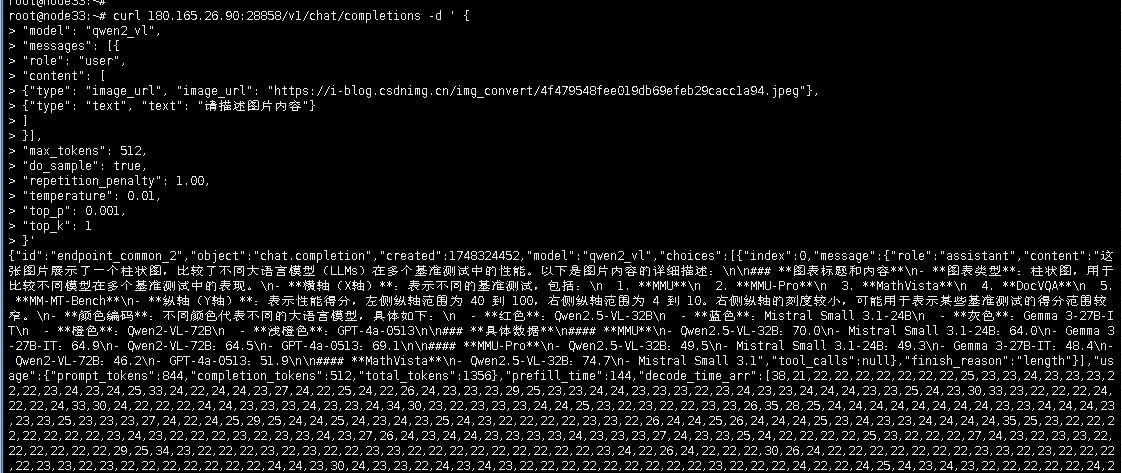
| swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts | 启动容器: docker run --name m1 --privileged=true -it -d --net=host --shm-size=200g --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/hisi_hdc --device=/dev/devmm_svm --entrypoint=bash -w /models -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /usr/local/dcmi:/usr/local/dcmi -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /usr/local/sbin:/usr/local/sbin -v /root/.cache/modelscope/hub/models:/models -v /tmp:/tmp -v /etc/hccn.conf:/etc/hccn.conf -v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts 进入容器: docker exec -it m1 bash 启动服务: cd /usr/local/Ascend/mindie/latest/mindie-service nohup ./bin/mindieservice_daemon > ./q.log 2>&1 & tail -f ./q.log 停服务: ps -ef|grep mindieservice_daemon|grep -v grep|awk '{print $2}'|xargs kill -9 停容器: docker stop m1 docker rm m1 | curl 110.165.26.90:28858/v1/chat/completions -d ' { "model": "qwen2_vl", "messages": [{ "role": "user", "content": [ {"type": "image_url", "image_url": "https://i-blog.csdnimg.cn/img_convert/4f479548fee019db69efeb29cacc1a94.jpeg"}, {"type": "text", "text": "请描述图片内容"} ] }], "max_tokens": 512, "do_sample": true, "repetition_penalty": 1.00, "temperature": 0.01, "top_p": 0.001, "top_k": 1 }' |
系统环境:
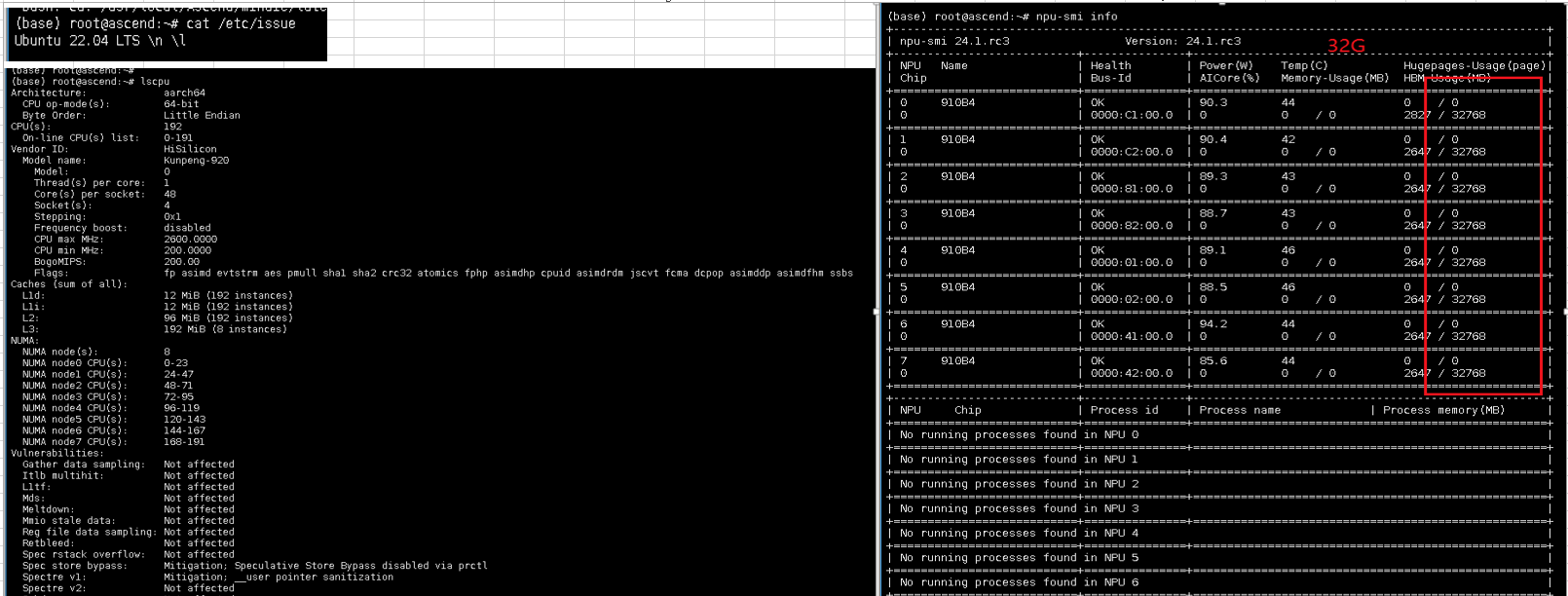
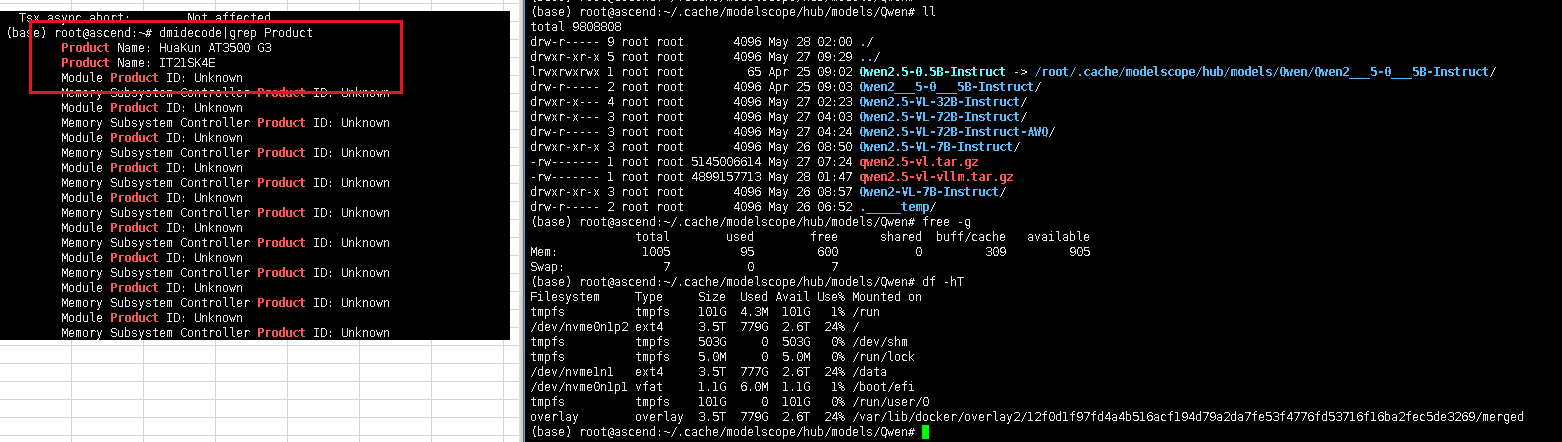
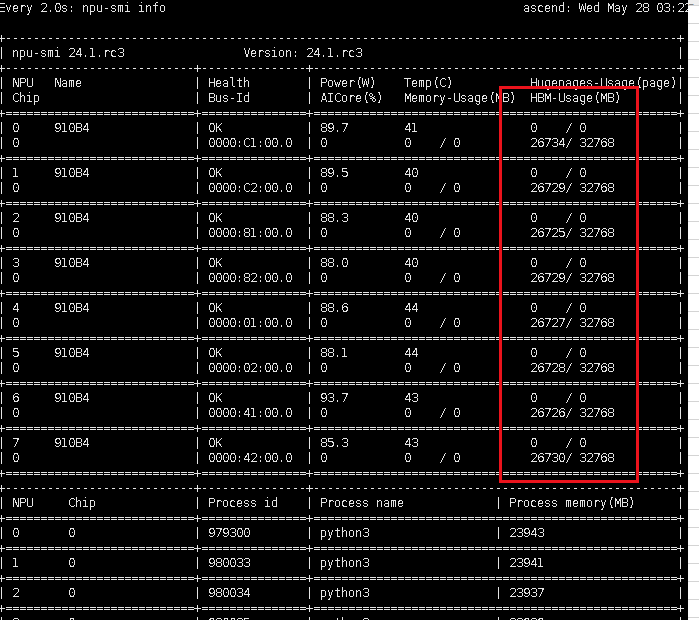
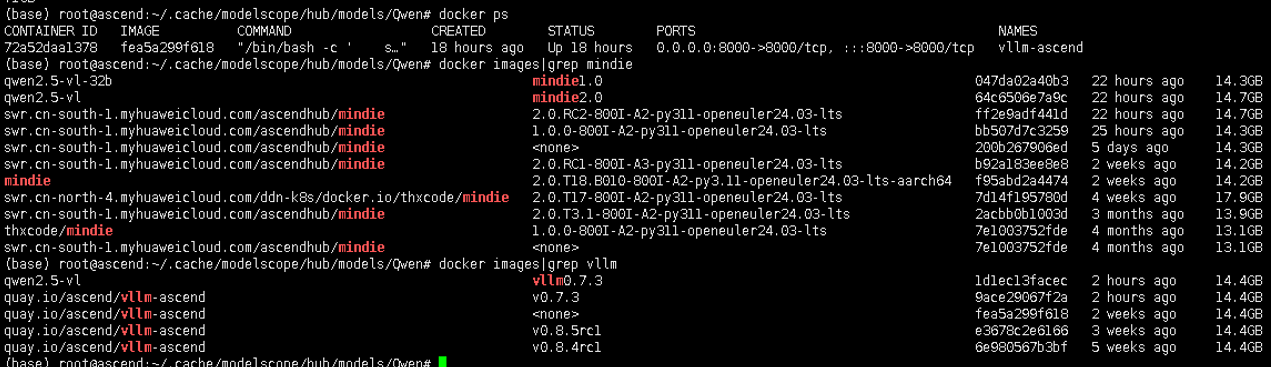
参考链接:
https://vllm-ascend.readthedocs.io/en/latest/quick_start.html
https://modelers.cn/models/Models_Ecosystem/Qwen2.5-VL-32B-Instruct


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









