






时间线梳理:
- prd上线后CPU占用100%,与stg和pre表现不同(两者CPU占用40%多,其实也有异常,只是没有引起注意,基本无流量的情况下不应该占用如此多的CPU);
- 短时间内运维无法定位,尝试分析代码,去掉bgWorker中不断读取计算队列的1024个协程,CPU恢复正常0.3%,定位到问题点;
- 调整读取Redis队列goroutine个数到4个,把没有读取到任务后的sleep时间从300ms调整成1s,CPU占用0.4%;
- 尝试增加goroutine到256,CPU占用6%;
- 去掉部分sleep 10ms代码,CPU占用10%,Redis请求少量增加;
- 调整goroutine数量到1024,去掉剩余sleep 10ms代码,增加pprof采样,CPU占用50%-60%。进行pprof;
- 根据调用链路CPU占比图,发现获取IP地址函数占用CPU最多,与docker有关;
- 优化使用IP地址的逻辑(服务启动时获取一次,之后所有逻辑中直接使用,不再执行获取IP的逻辑),在stg、pre环境测试优化后的代码,CPU40%多—>5%。问题得到验证;
- 上线prd,CPU占用10%
- 空跑时占用5%CPU,也属于负载过高的情况,原因:goroutine过多,每个协程中都有一个sleep代码,sleep是靠timer定时器实现,golang1.14之后timer是由存在于P中的四叉最小堆实现。所有goroutine都会加锁访问最小堆,会有很多的锁冲突,锁操作造成CPU占用,此时空跑服务真正的合理CPU占用应该在1%左右。
工作中有没有遇到什么困难问题,最后是如何解决的?
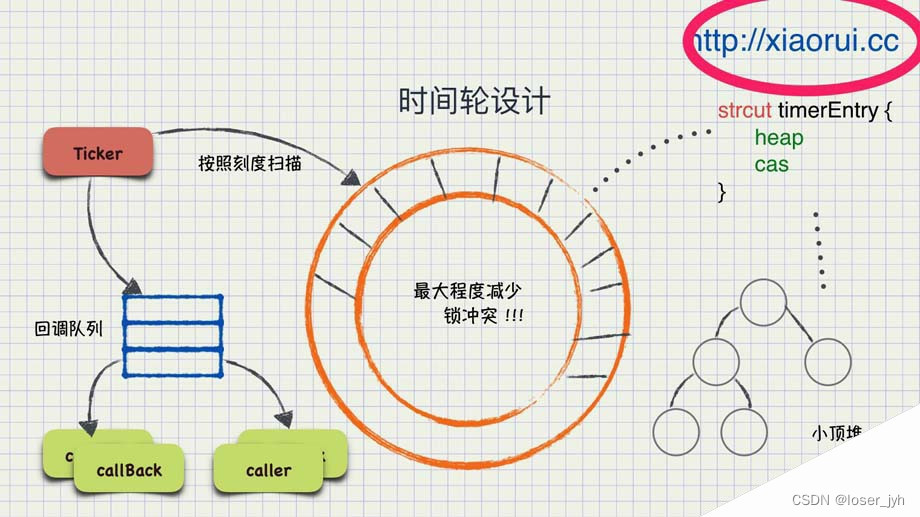
服务上线后,没有订单任务空跑CPU占用过高。首先对自己的代码有了解,配合技术监控指标中的Redis访问6k+,猜测是bgworker模块中的1024goroutine获取计算队列任务逻辑引起。注释代码,CPU掉底,问题定位。review代码逻辑,调整goroutine数和增加sleep时间(获取不到order,为了防止服务持续访问Redis空跑,sleep一段时间),CPU稳定运行,但是问题没有得到解决。怀疑是协程里sleep加锁定时器的最小堆。联合运维、DBA(涉及到redis P95 80ms的问题,怀疑是Redis RT过长拖垮了CPU,但是DBA反馈Redis机器整体负载很低,大部分的请求都是在2ms内返回,部分请求返回时间过长只是很小一部分,不足以拖垮服务CPU)pprof,下载pprof文件。安装graphvis查看火焰图和调用链路CPU占比图,发现是获取IP地址的golang内置函数占用CPU过高(80%+),根据调用链路和golang相关包源代码查看,定位到syscall包的NetlinkRIB获取路由相关基础信息,底层调用了Recvfrom,再底层是对Linux系统的系统调用,追查至此,和运维确定是运维系统容器化docker(新上线)对golang的支持不好导致,后续运维跟进优化。研发侧出现问题是由于,每个goroutine中每次访问Redis使用了本机IP作为分布式锁的标识,每次都是动态实时获取IP,导致每个goroutine都非常消耗CPU,而且每个goroutine除了加锁、解锁用到IP,还有根据IP作为tag上报业务指标、技术错误指标的逻辑,所以CPU占用很高。其实,IP地址这种自愈,服务随docker启动后,是不会发生变化的,因此合理的做法是服务启动后获取一次,之后直接使用。流程更加合理,也避免了运维侧docker对golang支持不好的问题。由于获取IP地址时统一使用一个util包里的函数,因此优化代码很方便,统一修改函数逻辑,取消之前的逻辑,直接读取全局变量,该全局变量由服务启动时执行获取IP的逻辑赋值。问题fixed,上线后CPU占用5%,调整sleep时间,CPU占用2.6%,其实还有优化的空间,服务空跑,只是多个协程请求Redis,无任务其他计算任务和逻辑,CPU也不应该占用这么高,原因是每个goroutine中有sleep代码,sleep是靠timer定时器实现,golang1.14之后timer是由存在于P中的四叉最小堆实现。所有goroutine靠线程M运行时都会加锁访问最小堆,会有很多的锁冲突,锁操作造成CPU占用,此时空跑服务真正的合理CPU占用应该在1%左右。各个大厂的方案是:调大timer精度,或者使用时间轮,把所有goroutine中的定时sleep任务收敛到统一的时间轮调度(相当于一个定时/延时调用系统),每个goroutine需要sleep的时候向时间轮注册一个任务,同时带上需要接收任务计时结束后收通知的channel指针,时间轮系统收到请求后根据毫秒数挂在到某个队列。时间轮以1ms或者10ms为精度,没隔1ms/10ms扫描时间轮上某个格子的列表,由于列表都是按需排队,只需检查头部几个链表元素,如果时间到则向该元素中的channel发送通知,同时移除该元素。原来的goroutine从sleep变成了等待channel通知,虽然都是gopark调用,但是不再访问定时器的最小堆,没有加锁逻辑,符合golang的使用通信来共享内存的哲学。也就没有占用CPU的情况。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









