







G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一。早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术,JDK9 默认就是使用的G1垃圾收集器。
不同于其他的分代回收算法,G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。每块区域既有可能属于O区、也有可能是Y区,且每类区域空间可以是不连续的(对比CMS的O区和Y区都必须是连续的)。
G1有三个明显特点:1、 压 缩 空 间 强 , 避 免 碎 片 \color{red}{压缩空间强,避免碎片} 压缩空间强,避免碎片 2、空间使用更灵活 3、 G C 停 顿 周 期 更 可 控 , 避 免 雪 崩 \color{red}{GC停顿周期更可控, 避免雪崩} GC停顿周期更可控,避免雪崩
G1其实是Garbage First的意思,垃圾优先? 不是,是优先处理那些垃圾多的内存块的意思。
一般的垃圾回收器把内存分成三类: Eden(E), Suvivor(S)和Old(O)。

G1虽然也把内存分成了这三大类,但是在G1里面这三大类不是泾渭分明的三大块内存,G1把内存划分成很多小块, 每个小块会被标记为E/S/O中的一个,可以前面一个是Eden后面一个就变成Survivor了。

这么做给G1带来了很大的好处,由于把三块内存变成了几百块内存,内存块的粒度变小了,从而可以垃圾回收工作更彻底的并行化。
G1的并行收集做得特别好,我们第一次听到并行收集应该是CMS(Concurrent Mark & Sweep)垃圾回收算法, 但是CMS的并行收集也只是在收集老年代能够起效,而在回收年轻代的时候CMS是要暂停整个应用的(Stop-the-world)。而G1整个收集全程几乎都是并行的。
它回收的大致过程是这样的:
- 在垃圾回收的最开始有个短暂的时间段(Inital Mark)会停止应用(stop-the-world)
- 然后应用继续运用,同时G1开始Concurrent Mark
- 再次停止应用,来Final Mark(stop-the-world)
- 最后感觉Garbage First的原则,选择一些内存块进行回收
G1的另一个显著特点他能够让用户设置应用的暂停时间,为什么G1能做到这一点呢?
也许你已经注意到了,G1回收的第4步,它是“选择一些内存块”,而不是整代内存来回收,这是G1跟其它GC非常不同的一点,其它GC每次回收都会回收整个Generation的内存(Eden, Old), 而回收内存所需的时间就取决于内存的大小,以及实际垃圾的多少,所以垃圾回收时间是不可控的;而G1每次并不会回收整代内存, 到 底 回 收 多 少 内 存 就 看 用 户 配 置 的 暂 停 时 间 \color{red}{到底回收多少内存就看用户配置的暂停时间} 到底回收多少内存就看用户配置的暂停时间,配置的时间短就少回收点,配置的时间长就多回收点 ,伸缩自如。
由于内存被分成了很多小块,又带来了另外好处,由于内存块比较小,进行内存压缩整理的代价都比较小,相比其它GC算法,可以有效的规避内存碎片的问题。
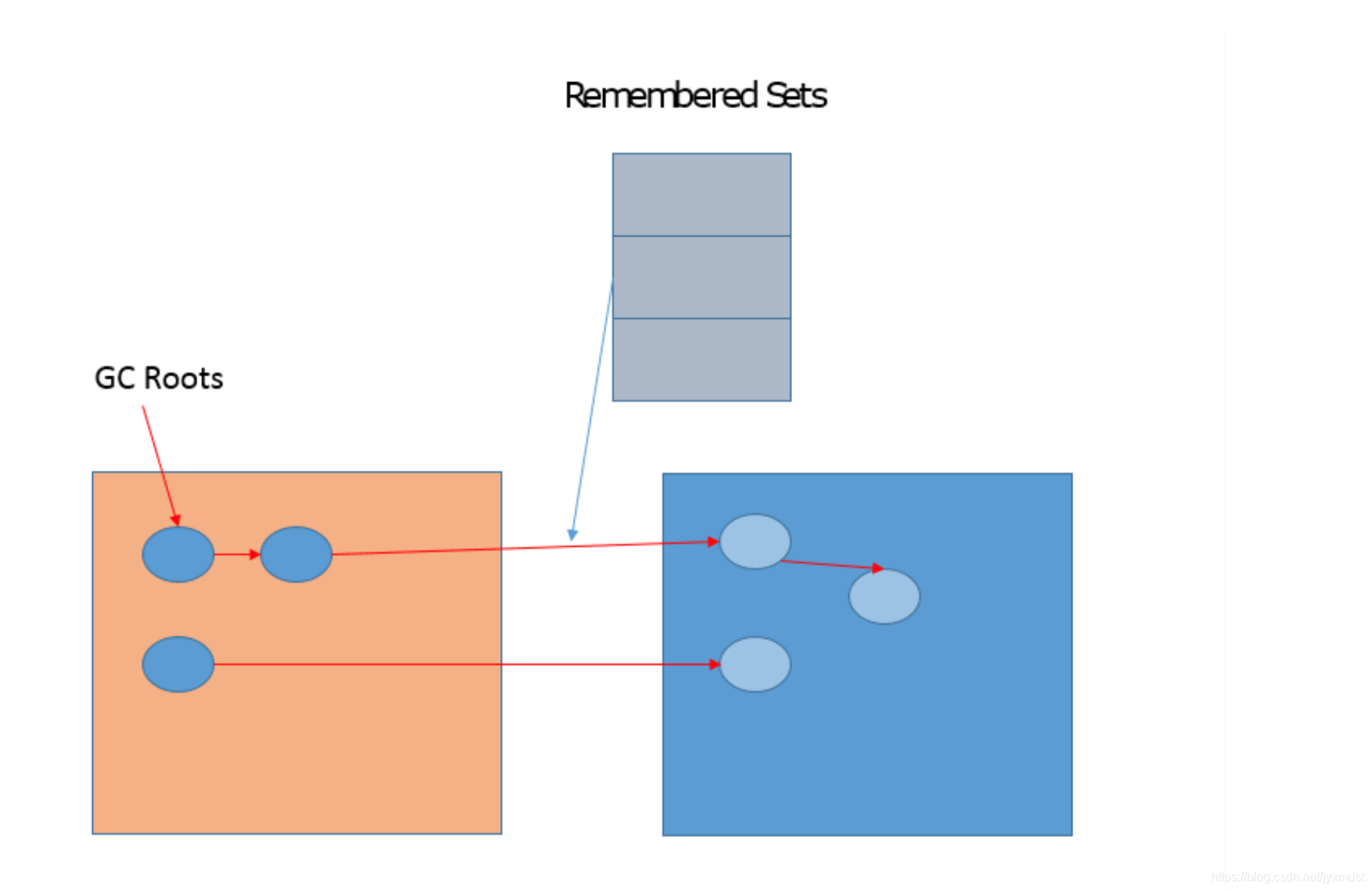
记忆集Remembered Set:
G1相关概念非常多,有一个重点就是Remembered Set,用于记录和维护region之间对象的引用关系。为什么需要这么做呢?试想,新生代GC是复制算法,也就是说,类似对象 从Eden或者Survivor到to区域的“移动”,其实是“复制”,本质上是一个新的对象。在这个过程中,需要必须保证老年代到新生代的跨区引用仍然有效。比如card table是remembered set的一种实现。下面的示意图说明了相关设 计。
G1 的缺点:
G1 需要记忆集 (具体来说是卡表,Remembered Set)来记录新生代和老年代之间的引用关系,这种数据结构在 G1 中需要占用大量的内存,可能达到整个堆内存容量的 20% 甚至更多。而且 G1 中维护记忆集的成本较高,带来了更高的执行负载,影响效率。
G1对比CMS的区别在:
- G1在压缩空间方面有优势
- G1通过将内存空间分成区域(Region)的方式避免内存碎片问题
- Eden,Survivor,Old区不再固定、在内存使用效率上来说更灵活
- G1可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间避免应用雪崩现象,可驾驭度,G1 是可以设定GC 暂停的 target 时间的,根据预测模型选取性价比收益更高,且一定数目的 Region 作为 CSet,能回收多少便是多少。
- G1在回收内存后会马上同时做,合并空闲内存的工作、而CMS默认是在STW(stop the world)的时候做
- G1会在Young GC中使用、而CMS只能在O区使用
- SATB 算法在 remark 阶段延迟极低以及借助 RSet 的实现可以不做全堆扫描(G1 对大堆更友好)以外,最重要的是可驾驭度
目前CMS还是默认首选的GC策略、可能在以下场景下G1更适合:
- 服务端多核CPU、JVM内存占用较大的应用(至少大于4G)
- 应用在运行过程中产生大量内存碎片、需要经常压缩空间
- 想要更可控、可预期的GC停顿周期:防止高并发应用雪崩现象
G1 的 JVM调优
1、region太小不合适,会令你在分配大对象时更难找到连续空间
-XX:G1HeapRegionSize=<N, 例如16>M
2、老年代回收,则是依靠Mixed GC,指定触发阈值,并且设定最多被包含在一次Mixed GC中的region比例
–XX:G1MixedGCLiveThresholdPercent –XX:G1OldCSetRegionThresholdPercent
3、在垃圾收集过程中,G1会把新创建的字符串对象放入队列中,然后在Young GC之后,并发地(不会STW)将内部数据 (char数组,JDK 9以后是byte数组)一致的字符串进行排重,也就是将其引用同一个数组。你可以使用下面参数激活
-XX:+UseStringDeduplication
4、G1只有在发生Full GC时才进行类型卸载,但这显然不是我们想要的。你可以加上下面的参数,在并发标记阶段结束后,JVM即进行类型卸载
-XX:+ClassUnloadingWithConcurrentMark
5、建议开启选项下面的选项进行并行引用处理
-XX:+ParallelRefProcEnabled
总结
G1是一款压缩型的收集器.G1通过有效的压缩完全避免了对细微空闲内存空间的分配,不用依赖于regions,这不仅大大简化了收集器,而且还消除了潜在的内存碎片问题。除压缩以外,G1的垃圾收集停顿也比CMS容易估计,也允许用户自定义所希望的停顿参数(pause targets)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









