






该类用于网络图片抓取,只需要一个记录了所需图片URL的文本文件,就可自动解析抓取图片,并且可以按照url的路径自动存储,方便快捷,盗图利器
package com.mms.utils;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ImageTerminator {
//记录文件数
private static int COUNT = 1;
private static String savePath;
public static void setSavePath(String savePath) {
ImageTerminator.savePath = savePath;
}
// 一次读一行
public static void readByLine(String filePath) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
File file = new File(filePath);
if (!file.exists()) {
return;
}
fis = new FileInputStream(file);
isr = new InputStreamReader(fis, "GBK");
br = new BufferedReader(isr);
String line = "";
while ((line = br.readLine()) != null) {
// 空行跳过
if ("".equals(line.trim())) {
continue;
}
// System.out.println(imageUrlFilter(line));
// System.out.println(getDirPath(null,imageUrlFilter(line)));
// System.out.println(getFileName(imageUrlFilter(line)));
// 获取图片
getImage(imageUrlFilter(line));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (br != null)
br.close();
if (isr != null)
isr.close();
if (fis != null)
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
// 截取图片格式的url
public static String imageUrlFilter(String str) {
if (str.indexOf("http") == -1) {
return str;
}
// 保留从http开始以后的字符串
if (str.indexOf("src=\"http") > -1) {
str = str.substring(str.indexOf("src=\"http"));
}
str = str.substring(str.indexOf("http"));
// 过滤带有图片格式后缀的url
if (str.indexOf(".jpg") > -1) {
str = str.substring(0, str.indexOf(".jpg"));
str += ".jpg";
} else if (str.indexOf(".jpeg") > -1) {
str = str.substring(0, str.indexOf(".jpeg"));
str += ".jpeg";
} else if (str.indexOf(".png") > -1) {
str = str.substring(0, str.indexOf(".png"));
str += ".png";
} else if (str.indexOf(".gif") > -1) {
str = str.substring(0, str.indexOf(".gif"));
str += ".gif";
} else {
str = null;
}
return str;
}
// 通过url截取存储路径
// e.g:http://img.j1.com/images/images1308/logo/yplogo_59.jpg---->/img.j1.com/images/images1308/logo/
// 该url参数为已调用imageUrlFilter方法后得到的url
// root用于指定存入路径e.g: root=d://abc/123,默认在D盘
public static String getDirPath(String root, String url) {
if (url == null || url.indexOf("http:") == -1) {
return null;
}
// 指定url字符串中“/”第三次出现的位置索引,到最后一个“/”出现的位置索引
url = url.substring(getCharacterPosition(url, "/", 3) + 1, url
.lastIndexOf("/"));
if (root == null) {
url = "D://" + url;
} else {
url = root.trim() + url;
}
return url;
}
// 计算指定字符在字符串中第N次出现的位置
// string : 要进行匹配的字符串
// specify : 指定需要匹配的字符
// n : 指定计算此匹配字符在字符串中第几次出现
// return : 第n次出现在该字符串中的索引
public static int getCharacterPosition(String string, String specify, int n) {
// 这里是获取"#"符号的位置
Matcher slashMatcher = Pattern.compile(specify).matcher(string);
int mIdx = 0;
while (slashMatcher.find()) {
mIdx++;
// 当"#"符号第二次出现的位置
if (mIdx == n) {
break;
}
}
return slashMatcher.start();
}
public static String getFileName(String url) {
if (url != null && !"".equals(url.trim())) {
if (url.lastIndexOf("/") != -1) {
url = url.substring(url.lastIndexOf("/") + 1);
}
}
return url;
}
// 通过url获取图片(储存路径对应url中的相对路径)
public static void getImage(String urls) {
DataInputStream dis = null;
FileOutputStream fos = null;
try {
if (urls == null || "".equals(urls.trim())) {
return;
}
URL url = new URL(urls);
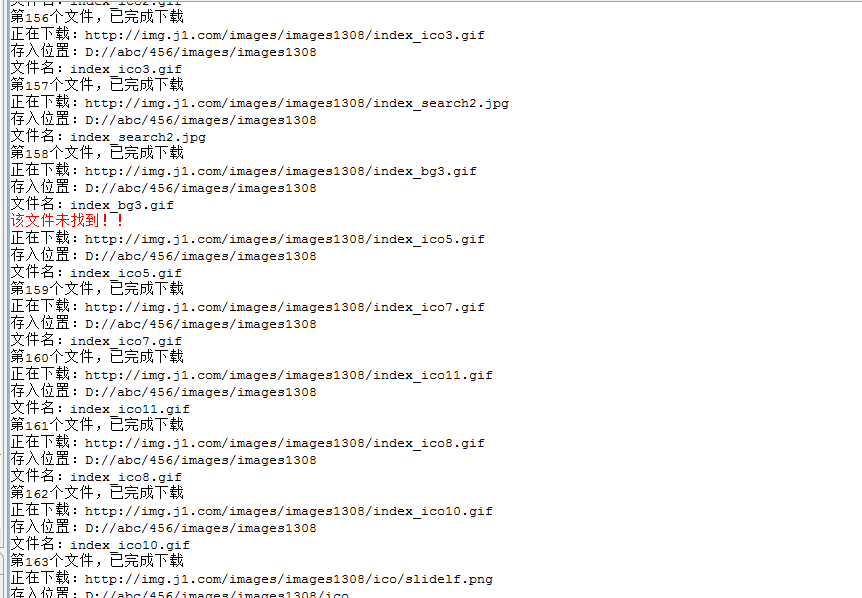
System.out.println("正在下载:" + urls);
// 根据截取到的图片url截取图片相对路径
String dirPath = getDirPath(savePath, urls);
System.out.println("存入位置:" + dirPath);
File outFile = new File(dirPath);
if (!outFile.isDirectory()) {
outFile.mkdirs();
outFile = new File(dirPath + "/" + getFileName(urls));
} else {
outFile = new File(dirPath + "/" + getFileName(urls));
}
System.out.println("文件名:" + getFileName(urls));
// 此处异常捕获是为了捕获在服务器端未找到文件的异常
try {
dis = new DataInputStream(url.openStream());
} catch (Exception e) {
System.err.println("该文件未找到!!");
return;
}
fos = new FileOutputStream(outFile);
byte[] buff = new byte[1024];
int length;
while ((length = dis.read(buff)) > 0) {
fos.write(buff, 0, length);
}
fos.flush();
System.out.println("第" + (COUNT++) + "个文件,已完成下载");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (fos != null)
fos.close();
if (dis != null)
dis.close();
} catch (Exception e2) {
e2.printStackTrace();
}
}
return;
}
public static void main(String[] args) {
// 调用:只需输入需要扫描的记录了url集的文件(存储路径可选参数,不填默认下载到D盘根目录)
setSavePath("D://abc/456/");
readByLine("D:\\\\slk\\开发归纳\\批量抓图\\url.txt");
}
}
演示需解析的文本如下,只要是标准的http请求都能解析到。。。。















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









