



数据可视化学习心得:从认知到实践的跨越
在这个信息如潮水般涌来的时代,数据无处不在,它们如同散落在沙滩上的珍珠,等待着我们去发现、去串联。作为一名大学生,我选择了数据可视化这一课程,期望通过系统的学习,掌握将复杂数据转化为直观图形的技能,从而在这片数据海洋中捕捉到那些有价值的“珍珠”。经过一个学期的学习和实践,我对数据可视化有了更加深刻的认识和体会。
初识数据可视化:从图表到故事的转变
在课程开始之初,我对数据可视化的理解还停留在简单的图表制作层面,如柱状图、折线图和饼图等。这些图表虽然能够直观地展示数据,但总觉得缺乏一些生动性和深度。然而,随着课程的深入,我逐渐意识到,数据可视化不仅仅是制作图表,它更是一种通过图形、图像和动画等视觉元素,将数据信息传达给受众的方法和技术。数据可视化能够帮助我们更好地理解数据,发现数据中的规律和趋势,甚至通过数据讲述一个引人入胜的故事。
柱形图:
折线图:
饼图:
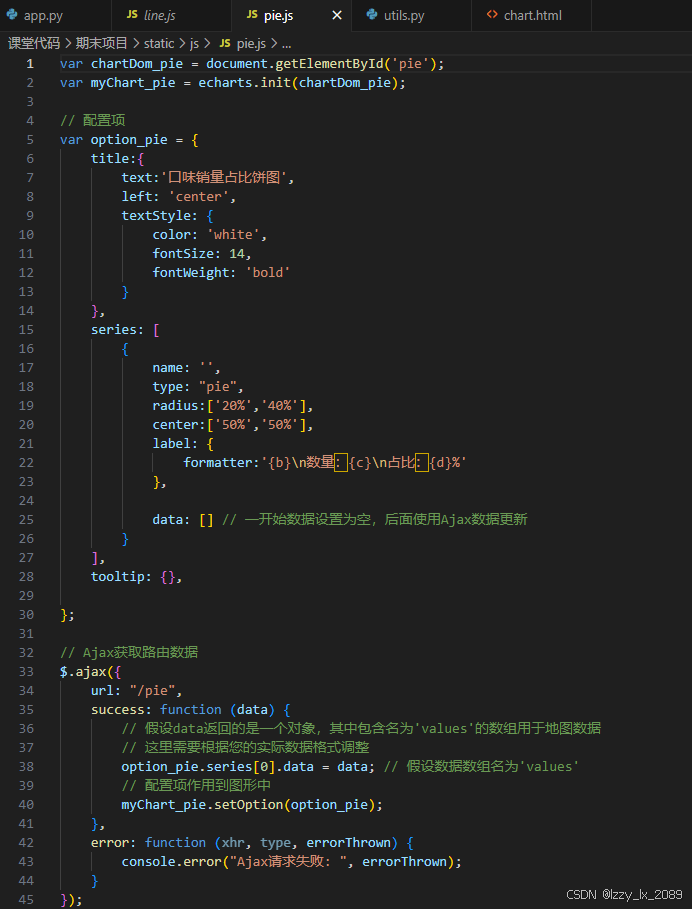
理论与实践的结合:从工具到编程的跨越
在学习过程中,我接触到了多种数据可视化工具和编程语言,如Tableau、Power BI和Python的Matplotlib、Seaborn库等。这些工具各有特色,有的易于上手,适合快速制作简单的图表;有的功能强大,可以定制复杂的可视化效果。通过实际操作这些工具,我不仅掌握了它们的基本用法,还学会了如何根据数据的特性和需求选择合适的可视化方式。
在使用Python进行可视化时,我深刻体会到了编程的灵活性和强大。通过编写代码,我可以自定义图表的样式、颜色和布局,甚至可以实现一些高级的可视化效果,如三维图形和动画。这种自定义的能力让我能够更好地展示数据的细节和特征,使可视化作品更具说服力和吸引力。
将理论与实践相结合,从使用现成的数据可视化工具过渡到编程实现自定义可视化,是一个既充满挑战又极具成就感的过程。以下,我将通过添加一些具体的Python代码示例,来展示如何使用Matplotlib和Seaborn库进行自定义可视化,并体现编程的灵活性和强大功能。
使用Matplotlib进行基本可视化
首先,让我们从一个简单的折线图开始,展示如何使用Matplotlib快速创建并自定义一个图表。
python
import matplotlib.pyplot as plt | |
import numpy as np | |
# 生成数据 | |
x = np.linspace(0, 10, 100) | |
y = np.sin(x) | |
# 创建图表 | |
plt.figure(figsize=(10, 6)) # 设置图表大小 | |
plt.plot(x, y, label='Sine Wave', color='blue', linewidth=2) # 绘制折线图 | |
# 自定义样式 | |
plt.title('Sine Wave Visualization', fontsize=16) # 设置标题 | |
plt.xlabel('X-axis', fontsize=14) # 设置X轴标签 | |
plt.ylabel('Y-axis', fontsize=14) # 设置Y轴标签 | |
plt.grid(True) # 显示网格 | |
plt.legend() # 显示图例 | |
# 显示图表 | |
plt.show() |
使用Seaborn进行高级可视化
接下来,我们将使用Seaborn库来创建一个更复杂的可视化图表,如热力图,并展示如何通过编程来自定义其样式。
python
import seaborn as sns | |
import pandas as pd | |
import numpy as np | |
# 生成数据 | |
data = pd.DataFrame(np.random.rand(10, 12), columns=[f'Feature {i}' for i in range(1, 13)]) | |
# 创建热力图 | |
plt.figure(figsize=(12, 8)) # 设置图表大小 | |
sns.heatmap(data, annot=True, cmap='coolwarm', fmt='.2f') # 绘制热力图,并显示数值 | |
# 自定义样式 | |
plt.title('Heatmap of Random Data', fontsize=16) # 设置标题 | |
plt.xlabel('Features', fontsize=14) # 设置X轴标签 | |
plt.ylabel('Samples', fontsize=14) # 设置Y轴标签 | |
# 显示图表 | |
plt.show() |
实现高级可视化效果:三维图形和动画
最后,让我们通过编程实现一些更高级的可视化效果,如三维图形和动画。
三维图形
python复制代码
from mpl_toolkits.mplot3d import Axes3D | |
import matplotlib.pyplot as plt | |
import numpy as np | |
# 生成数据 | |
fig = plt.figure() | |
ax = fig.add_subplot(111, projection='3d') | |
x = np.linspace(-5, 5, 100) | |
y = np.linspace(-5, 5, 100) | |
X, Y = np.meshgrid(x, y) | |
Z = np.sin(np.sqrt(X**2 + Y**2)) | |
# 绘制三维图形 | |
ax.plot_surface(X, Y, Z, cmap='viridis') # 使用'viridis'颜色映射 | |
# 自定义样式 | |
ax.set_title('3D Surface Plot', fontsize=16) # 设置标题 | |
ax.set_xlabel('X-axis', fontsize=14) # 设置X轴标签 | |
ax.set_ylabel('Y-axis', fontsize=14) # 设置Y轴标签 | |
ax.set_zlabel('Z-axis', fontsize=14) # 设置Z轴标签 | |
# 显示图形 | |
plt.show() |
动画
创建一个简单的动画,展示数据随时间的变化。
python复制代码
import matplotlib.pyplot as plt | |
import numpy as np | |
from matplotlib.animation import FuncAnimation | |
# 生成数据 | |
fig, ax = plt.subplots() | |
x = np.linspace(0, 2 * np.pi, 100) | |
line, = ax.plot(x, np.sin(x)) # 初始绘制 | |
# 更新函数 | |
def update(frame): | |
line.set_ydata(np.sin(x + frame / 10.0)) # 更新数据 | |
return line, | |
# 创建动画 | |
ani = FuncAnimation(fig, update, frames=np.arange(0, 200), interval=50, blit=True) | |
# 自定义样式 | |
ax.set_title('Sine Wave Animation', fontsize=16) # 设置标题 | |
ax.set_xlabel('X-axis', fontsize=14) # 设置X轴标签 | |
ax.set_ylabel('Y-axis', fontsize=14) # 设置Y轴标签 | |
# 显示动画 | |
plt.show() |
通过这些代码示例,我们可以看到Python及其可视化库(如Matplotlib和Seaborn)提供了极大的灵活性和自定义能力。无论是创建基本的折线图、复杂的热力图,还是实现高级的三维图形和动画,编程都让我们能够精确控制可视化的每一个细节,从而更好地展示数据的特性和故事。
数据可视化的挑战与收获:从困难到成长的蜕变
当然,在学习数据可视化的过程中,我也遇到了不少挑战。数据的预处理和清洗是一个复杂而繁琐的过程,原始数据往往存在缺失、错误或不一致等问题,需要花费大量的时间和精力进行处理。此外,选择合适的可视化方式和参数也是一个技术活,不同的数据和受众可能对可视化的需求不同,需要我们在实践中不断尝试和调整。
然而,正是这些挑战让我更加深入地理解了数据可视化的本质和重要性。通过不断实践和改进,我不仅提高了自己的数据处理和可视化能力,还培养了解决问题的思维和创新能力。更重要的是,我学会了如何将数据可视化应用于实际问题和项目中,为决策提供有力的支持。
数据预处理与清洗
数据预处理是数据可视化的关键一步,它涉及到处理缺失值、异常值、数据转换等。以下是一个简单的数据预处理示例,使用Python的Pandas库来处理缺失值和异常值。
python复制代码
import pandas as pd | |
import numpy as np | |
# 创建一个示例数据框 | |
data = { | |
'A': [1, 2, np.nan, 4, 5, 100], # 包含缺失值和异常值 | |
'B': [5, np.nan, 3, 4, 6, 7], | |
'C': [np.nan, 2, 3, 4, 5, 6] | |
} | |
df = pd.DataFrame(data) | |
# 处理缺失值:使用平均值填充 | |
df_filled = df.fillna(df.mean()) | |
# 处理异常值:假设A列中的100是异常值,将其替换为该列的中位数 | |
median_A = df_filled['A'].median() | |
df_filled.loc[df_filled['A'] == 100, 'A'] = median_A | |
# 显示处理后的数据 | |
print(df_filled) |
选择合适的可视化方式和参数
选择合适的可视化方式和参数对于有效传达数据信息至关重要。以下是一个使用Matplotlib和Seaborn库进行可视化选择的示例,展示了如何根据数据的特性选择合适的图表类型。
python复制代码
import matplotlib.pyplot as plt | |
import seaborn as sns | |
# 假设我们有一个处理后的数据框df_cleaned | |
# 这里我们使用一个随机生成的数据框作为示例 | |
np.random.seed(0) | |
df_cleaned = pd.DataFrame({ | |
'Category': np.random.choice(['A', 'B', 'C'], 100), | |
'Value': np.random.randn(100) * 10 + 50 # 正态分布的数据 | |
}) | |
# 如果数据是分类的,并且我们想比较不同类别的均值,可以使用条形图 | |
sns.barplot(x='Category', y='Value', data=df_cleaned) | |
plt.title('Mean Values by Category') | |
plt.show() | |
# 如果数据是连续的,并且我们想观察数据的分布,可以使用箱线图 | |
sns.boxplot(x='Category', y='Value', data=df_cleaned) | |
plt.title('Value Distribution by Category') | |
plt.show() | |
# 如果数据有时间序列的特性,我们可以使用折线图 | |
df_cleaned['Time'] = pd.date_range(start='2023-01-01', periods=100, freq='D') | |
sns.lineplot(x='Time', y='Value', hue='Category', data=df_cleaned) | |
plt.title('Value Over Time by Category') | |
plt.show() |
实际应用
将数据可视化应用于实际问题和项目中,可以为决策提供有力的支持。以下是一个简单的实际应用示例,展示了如何使用可视化来识别销售数据中的趋势和模式。
python复制代码
# 假设我们有一个销售数据框sales_data | |
# 这里我们使用一个随机生成的数据框作为示例 | |
np.random.seed(42) | |
sales_data = pd.DataFrame({ | |
'Date': pd.date_range(start='2023-01-01', periods=100, freq='D'), | |
'Product': np.random.choice(['Product1', 'Product2', 'Product3'], 100), | |
'Sales': np.random.randint(10, 100, 100) | |
}) | |
# 设置日期为索引 | |
sales_data.set_index('Date', inplace=True) | |
# 计算每日总销售额 | |
daily_sales = sales_data.groupby(sales_data.index).sum() | |
# 绘制销售趋势图 | |
plt.figure(figsize=(12, 6)) | |
plt.plot(daily_sales.index, daily_sales['Sales'], label='Daily Sales') | |
plt.title('Daily Sales Trend') | |
plt.xlabel('Date') | |
plt.ylabel('Sales') | |
plt.legend() | |
plt.grid(True) | |
plt.show() | |
# 计算每月总销售额 | |
monthly_sales = sales_data.resample('M').sum() | |
# 绘制每月销售柱状图 | |
plt.figure(figsize=(12, 6)) | |
sns.barplot(x=monthly_sales.index, y=monthly_sales['Sales'], palette='viridis') | |
plt.title('Monthly Sales') | |
plt.xlabel('Month') | |
plt.ylabel('Sales') | |
plt.xticks(rotation=45) | |
plt.show() |
通过这些代码示例,我们可以看到,在面对数据可视化的挑战时,通过不断实践和改进,我们可以提高自己的数据处理和可视化能力,并学会如何将可视化应用于实际问题和项目中。这些经验和技能不仅有助于我们的个人成长,还能为组织提供有价值的数据洞察和决策支持。
实际案例的启示:从理论到实践的桥梁
在学习过程中,我接触到了许多实际的数据可视化案例,本学期的期末项目是螺狮粉销售大屏
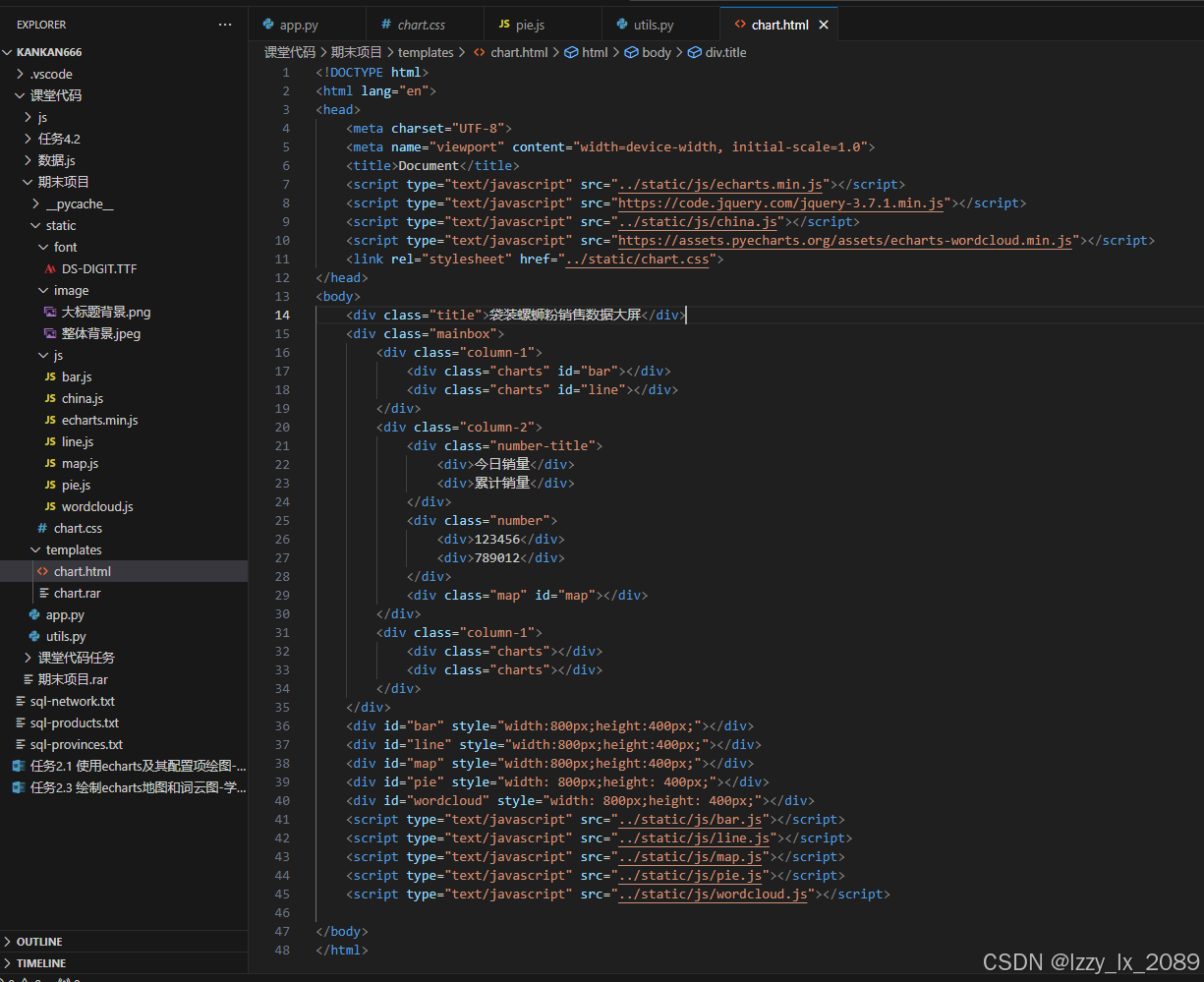
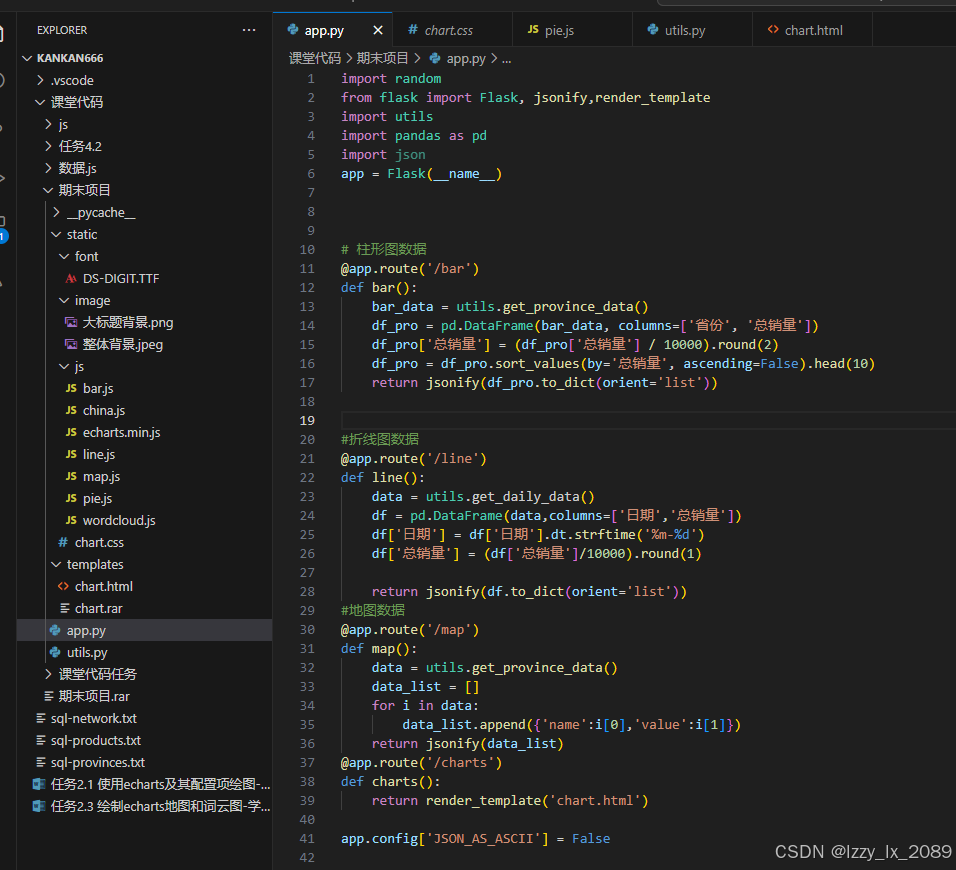
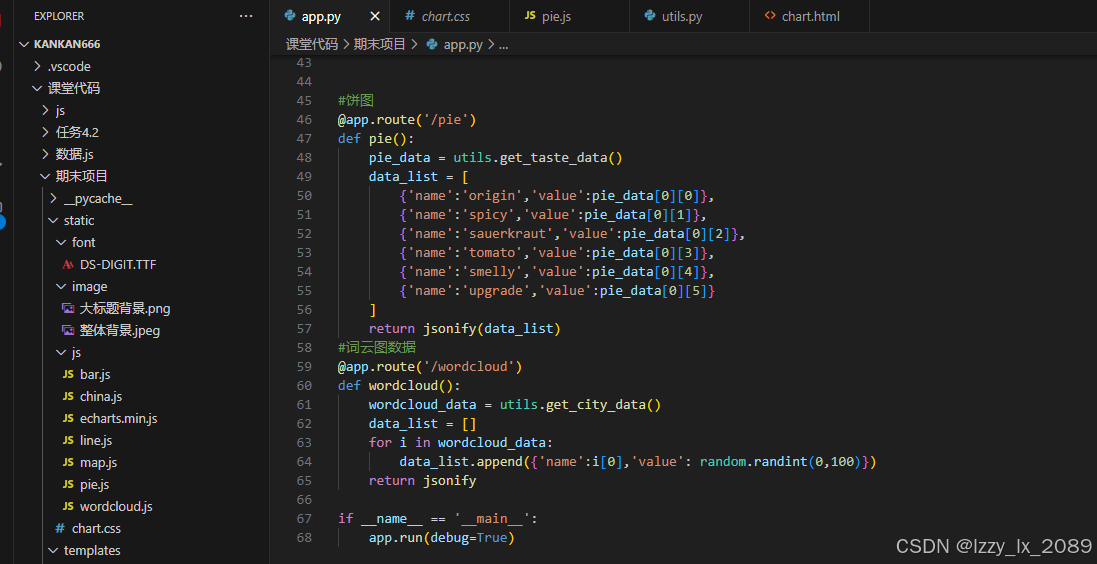
这些案例不仅丰富了我的学习体验,还让我更加清晰地认识到了数据可视化在实际应用中的重要性。它们如同一座座桥梁,连接着理论与实践,让我能够将所学知识应用于实际问题中,从而不断提升自己的能力和水平。
未来展望的深化
- 持续学习与探索:
- 紧跟数据可视化领域的最新动态和技术发展,如新的可视化工具、算法和编程语言。
- 深入研究数据可视化的理论基础,如认知心理学、信息论和美学,以指导您的设计和实践。
- 技术与实践结合:
- 将所学的理论知识应用于实际项目中,通过实践不断验证和完善您的可视化技能。
- 尝试解决复杂的数据可视化问题,如大数据可视化、实时数据可视化等,以提升您的技术挑战能力。
- 跨学科合作:
- 与其他领域的专家合作,如数据分析师、数据科学家、统计学家等,共同探索数据可视化的新应用。
- 参与跨学科的研究项目,将数据可视化应用于更广泛的领域,如医学、生物学、环境科学等。
- 创新与个性化:
- 尝试创建独特的可视化风格和设计,以展现您的个性和创意。
- 利用最新的技术,如人工智能和机器学习,来增强数据可视化的智能化和个性化。
对社会的贡献
- 教育与培训:
- 分享您的学习经验和知识,通过在线课程、讲座或工作坊等方式,帮助更多人掌握数据可视化的技能。
- 参与数据可视化社区和论坛,与其他从业者交流心得,共同推动数据可视化的发展。
- 公共项目与社区服务:
- 参与或发起公共数据可视化项目,如可视化社会现象、环境问题或公共政策等,以提高公众对数据驱动决策的认识。
- 利用您的技能为非营利组织或社区服务,帮助他们更好地理解和展示数据。
- 研究与发表:
- 参与数据可视化的研究工作,探索新的可视化方法和技术。
- 将您的研究成果发表在学术期刊、会议或博客上,与同行分享您的发现和见解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









