






在学习Python数据分析的过程中,我深刻体会到了Python在数据分析领域的强大功能和广泛应用。以下是我在学习过程中的心得体会:
在开始深入学习Python数据分析之前,掌握Python的基础语法、数据类型、函数和控制结构等是非常重要的。只有熟练掌握了这些基础知识,才能更好地理解和使用Python进行数据分析。
Python有许多强大的库和工具,可以用于数据分析。例如,NumPy和Pandas是处理和计算数据的常用库,它们提供了丰富的数据结构和操作方法。
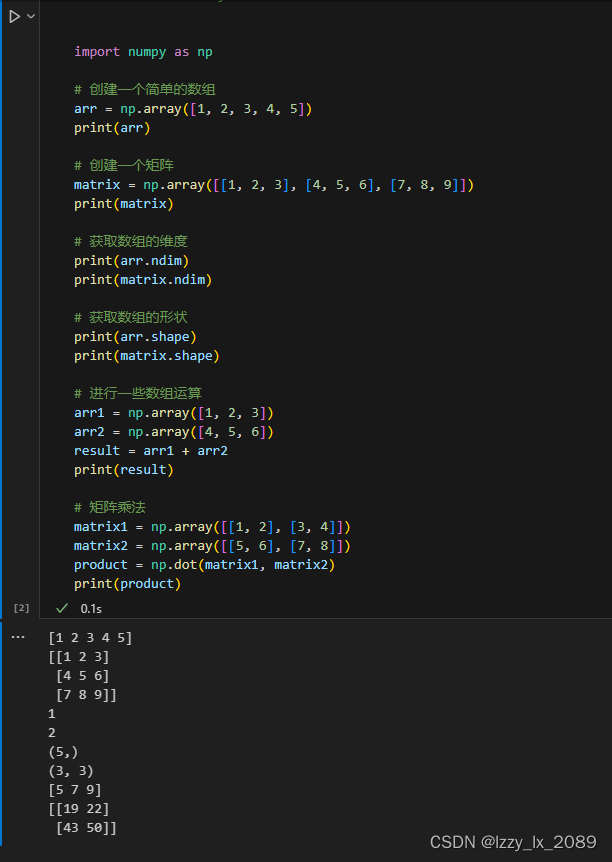
学习 NumPy 让我学会了高效处理数组和矩阵,它为数据的运算提供了强大的支持。
以下是一些使用 NumPy 处理数组和矩阵的代码实例:
而 Pandas 则像是数据的魔法盒,让数据的管理和操作变得轻而易举。
Matplotlib则用于数据可视化,帮助我们直观地展示数据分析结果。
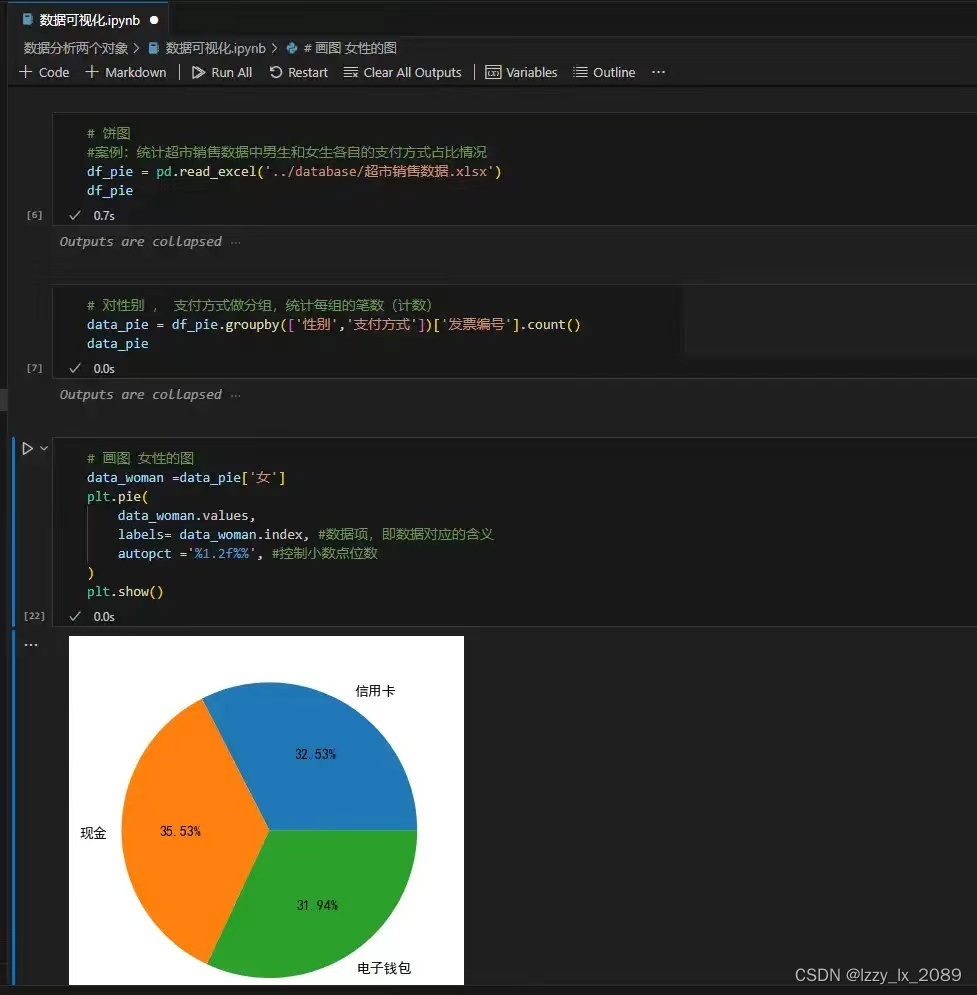
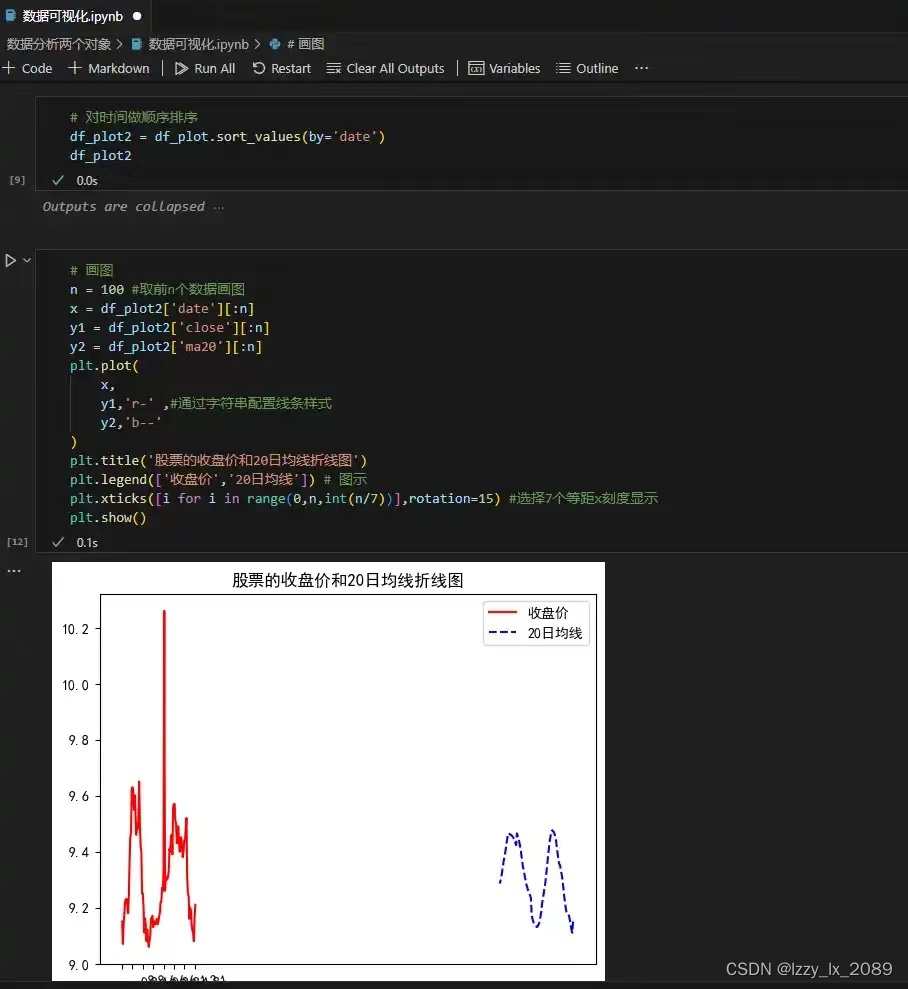
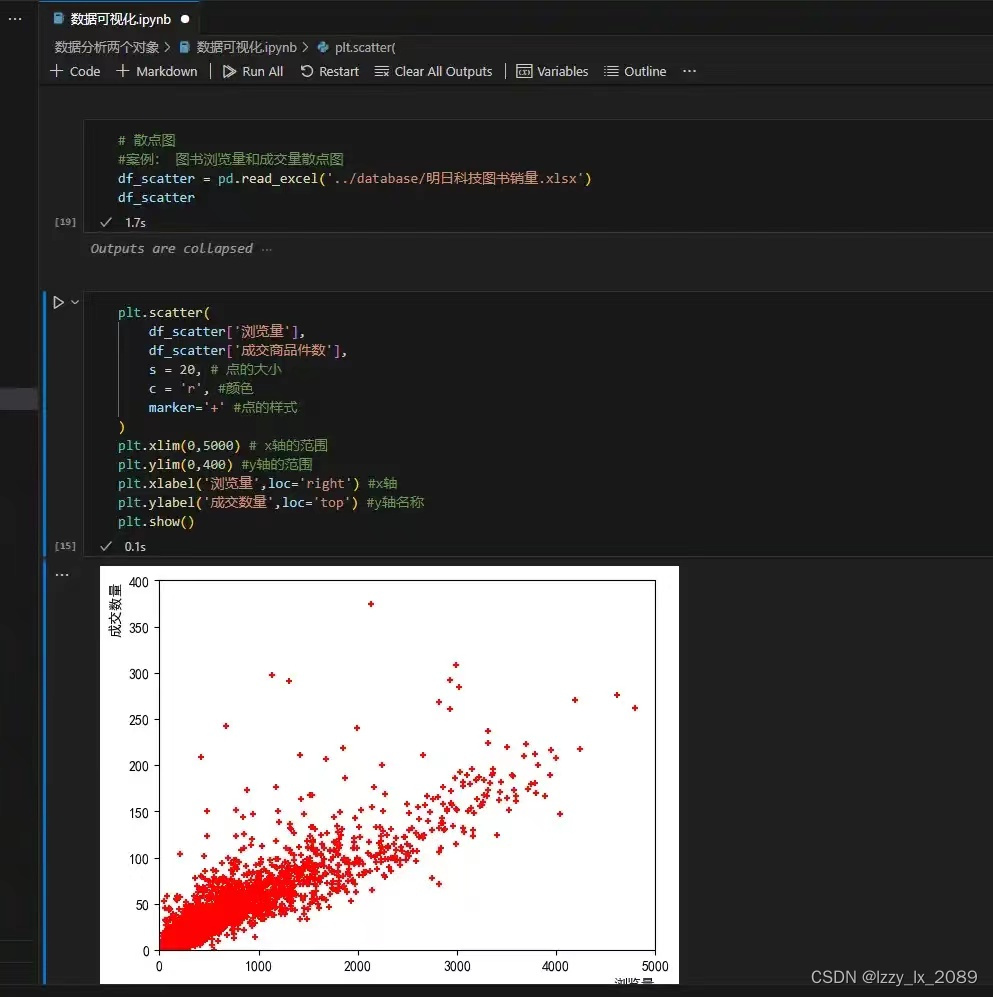
Matplotlib是一个强大的Python库,广泛用于绘制各种类型的图表,如折线图、散点图、直方图等。通过使用Matplotlib,可以将复杂的数据以清晰、直观的方式展示出来,从而降低数据的读取门槛,方便人们理解和分析数据。此外,Matplotlib还提供了丰富的功能和灵活性,允许用户自定义图表的各种属性,如颜色、线条、坐标轴等。这些特性使得Matplotlib成为数据科学家和分析师在进行数据分析和可视化时的重要工具。
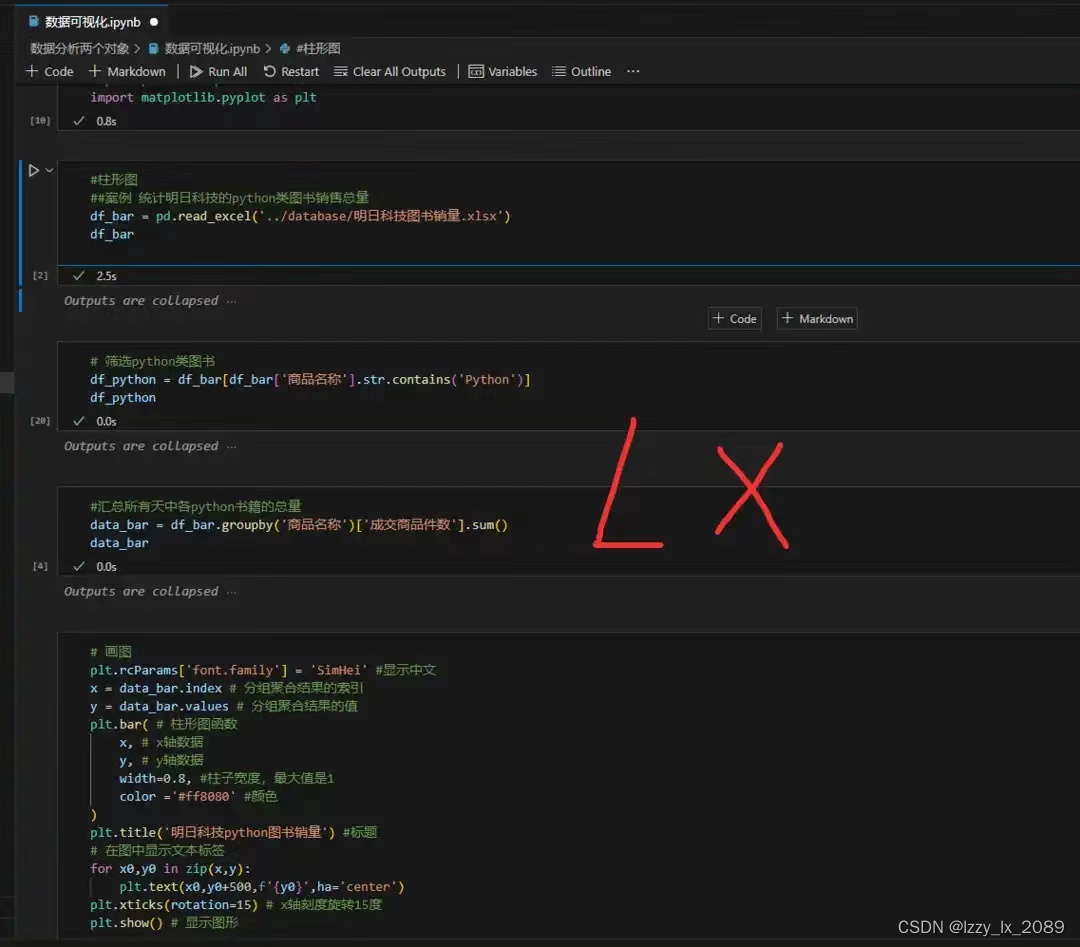
直方图:

饼图:
折线图:
散点图:
直方图:
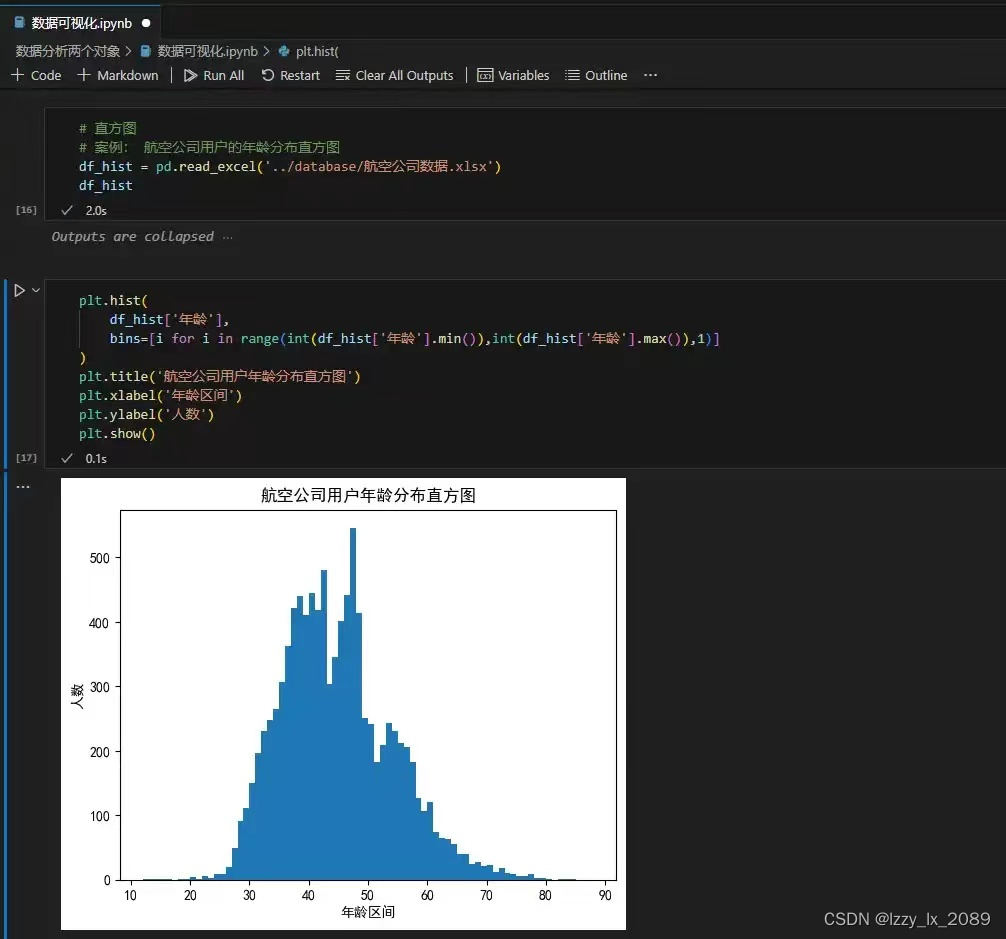
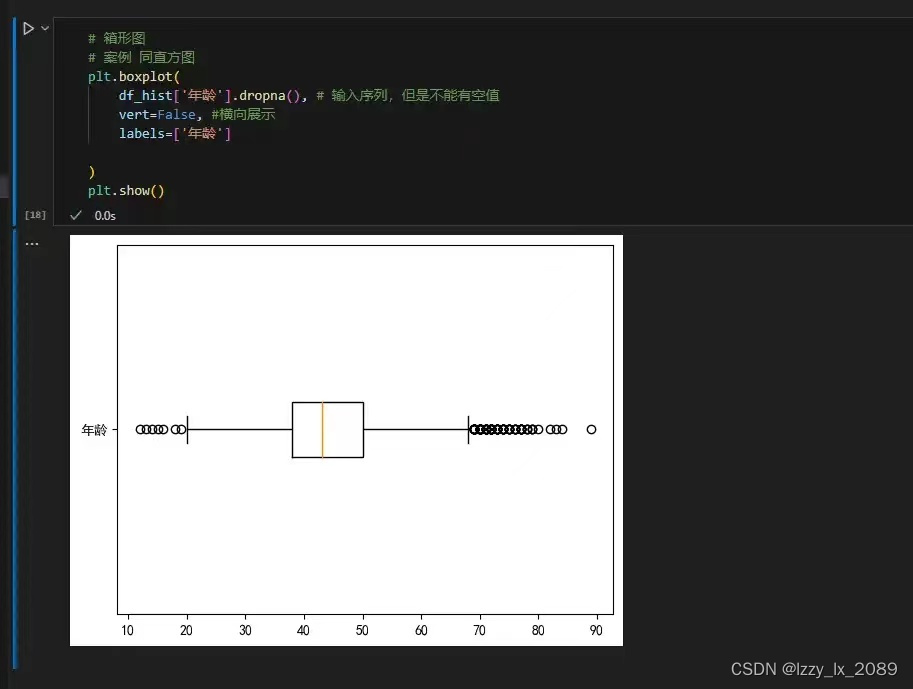
箱型图:
SciPy和Statsmodels等库在统计分析方面表现出色,支持描述性统计、回归分析、聚类分析等多种统计分析。
-
描述性统计:
- SciPy提供了强大的描述性统计工具,可以用于总结和描述数据的基本特征。例如,
scipy.stats.describe函数可以计算数组的多个描述性统计信息,如均值、方差、最小值、最大值等。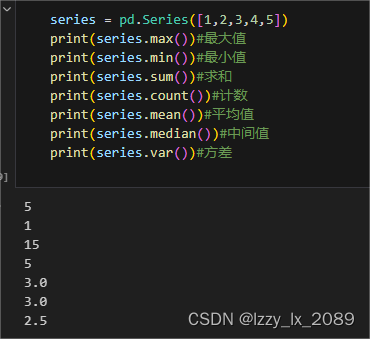
- 另外,SciPy还支持多种概率分布的拟合和可视化。
- SciPy提供了强大的描述性统计工具,可以用于总结和描述数据的基本特征。例如,
-
回归分析:
- SciPy和Statsmodels都支持回归分析。SciPy主要依赖于NumPy进行基本的数值计算,而Statsmodels则提供了更丰富的回归分析功能。
- Statsmodels特别擅长线性回归分析,并且可以通过最小二乘法拟合数据,得到回归系数和模型评估指标。此外,Statsmodels还可以进行多元线性回归分析。
-
聚类分析:
- 虽然SciPy和Statsmodels本身没有直接提供聚类分析的功能,但它们可以与其他库如scikit-learn一起使用来实现聚类分析。
综上所述,SciPy和Statsmodels在统计分析方面确实表现出色,涵盖了从描述性统计到复杂的回归分析等多种统计方法。
数据分析不仅仅是数据处理,还包括数据预处理、数据分析、建模和预测等步骤。通过实际项目案例,我逐渐掌握了这一流程,并学会了如何将理论知识应用到实际问题中。
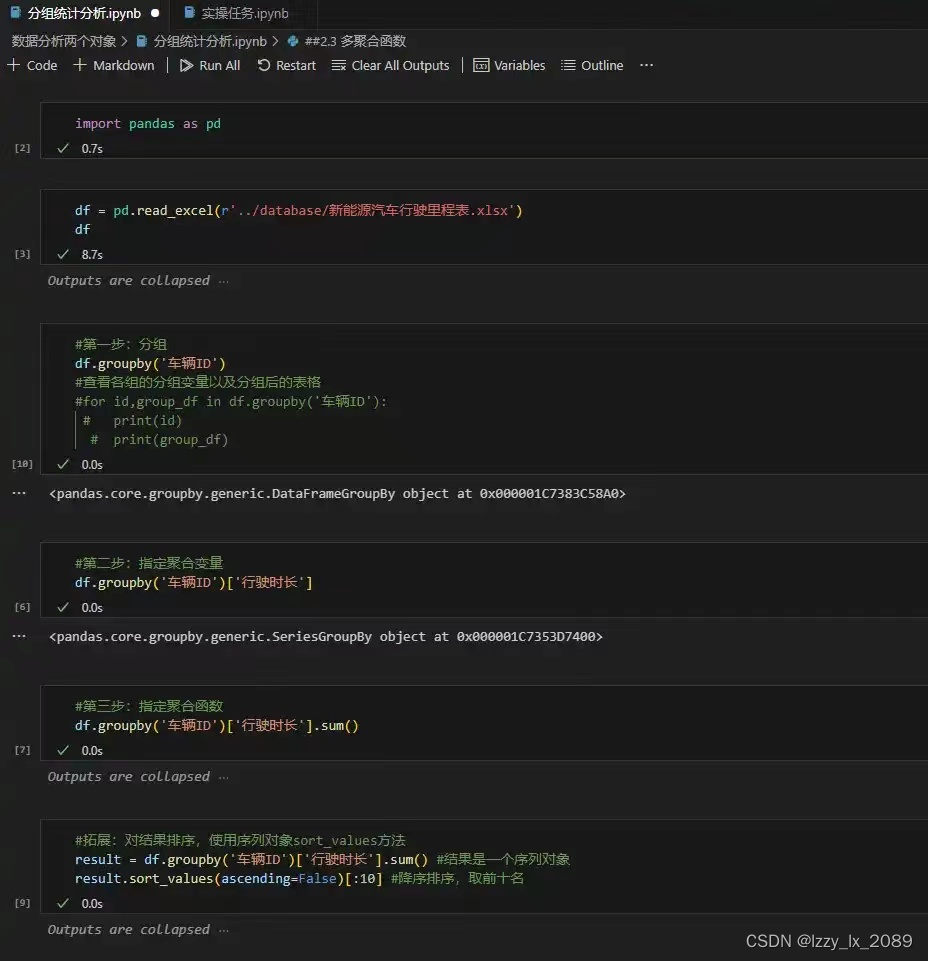
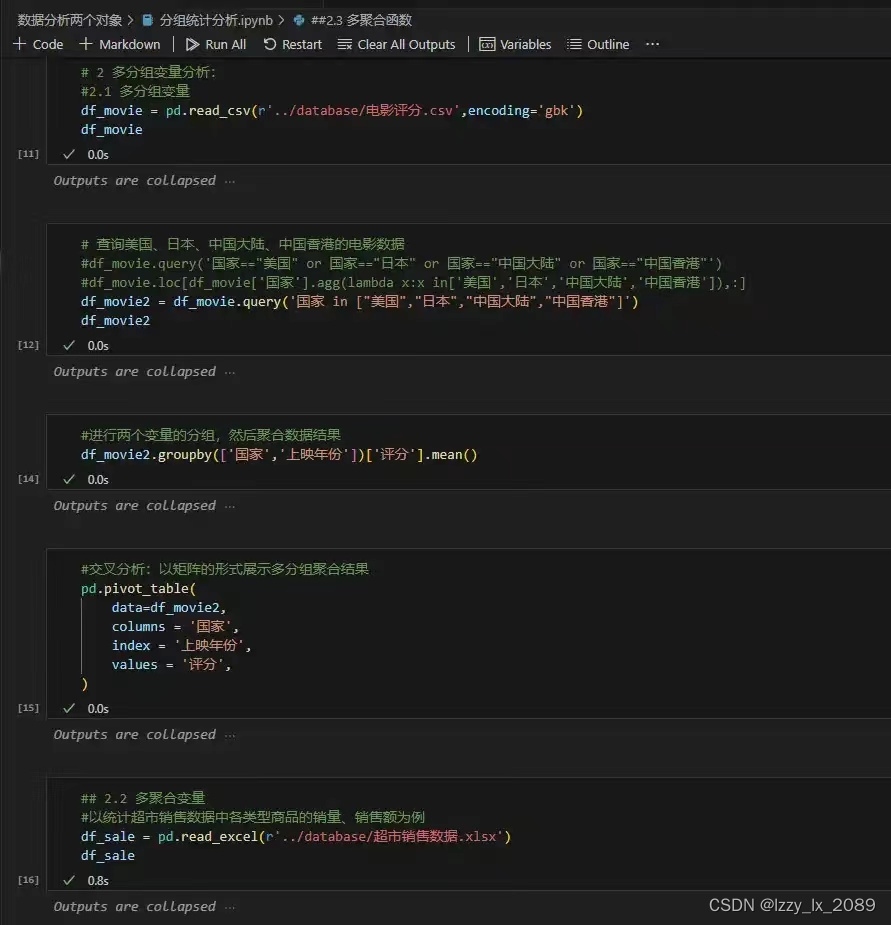
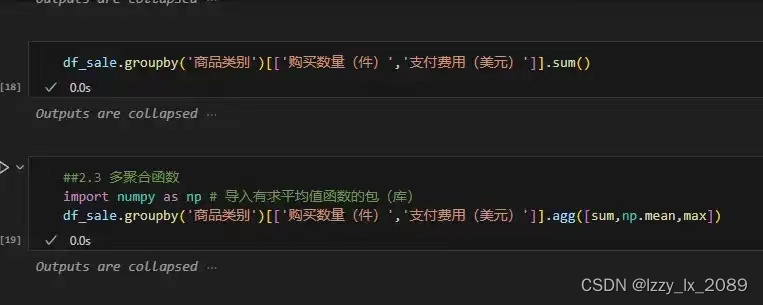
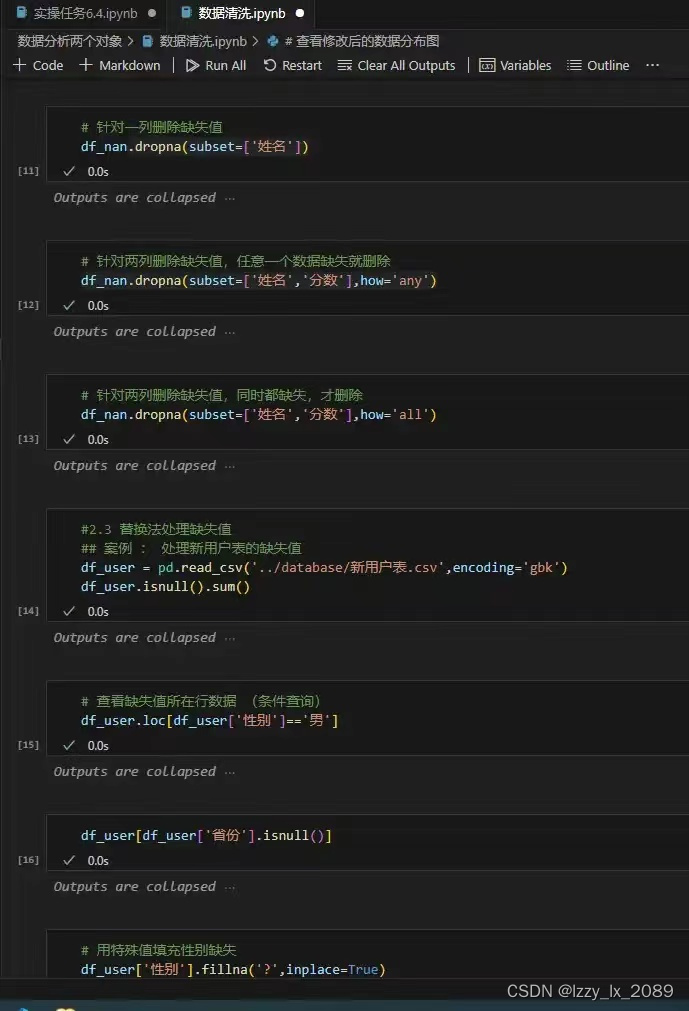
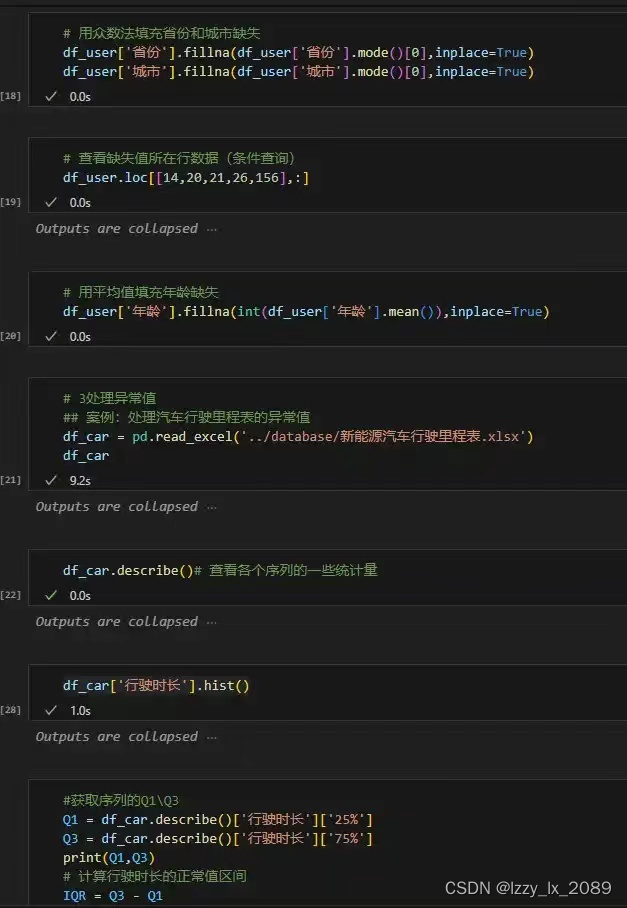
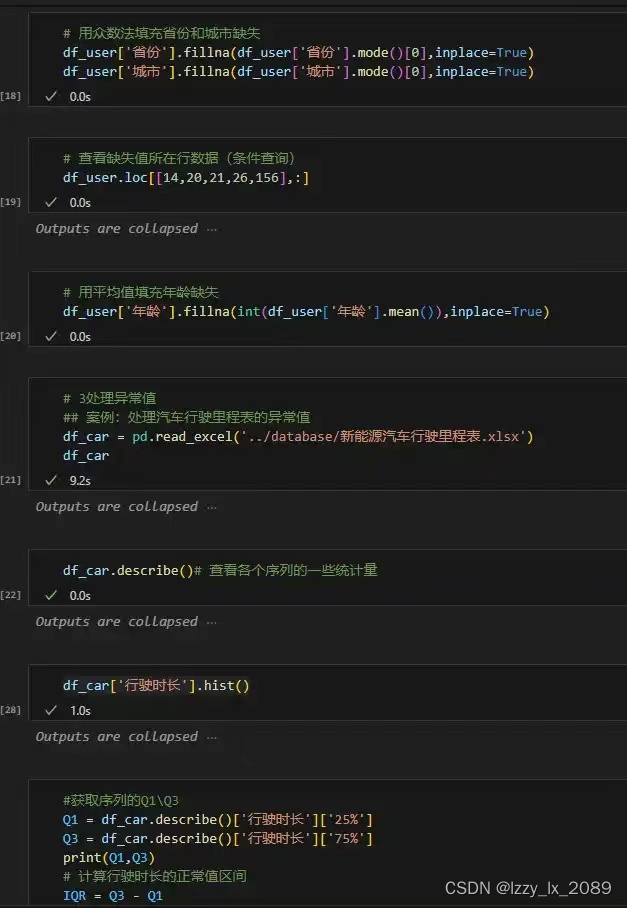
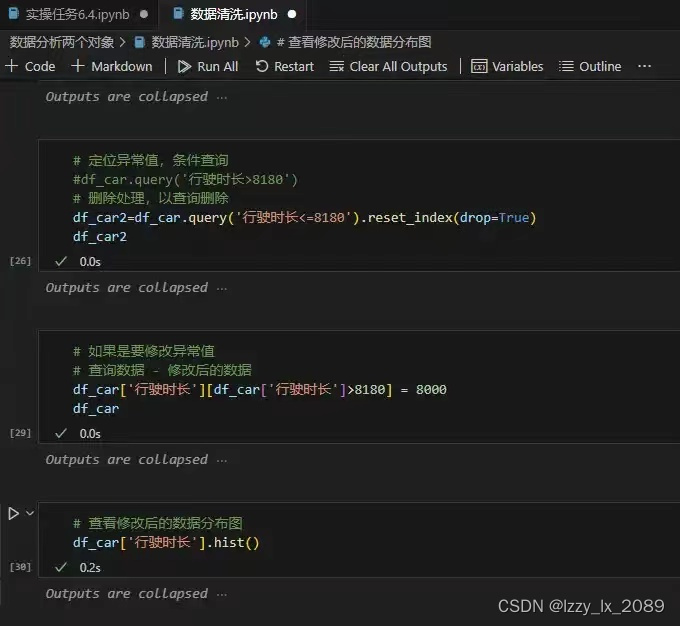
实践是检验真理的唯一标准。通过参与各种数据分析项目,我不仅巩固了所学知识,还积累了宝贵的实战经验。例如,在处理用户行为数据时,我学会了如何处理缺失值和异常值,以及如何使用Pandas进行高效的数据操作。
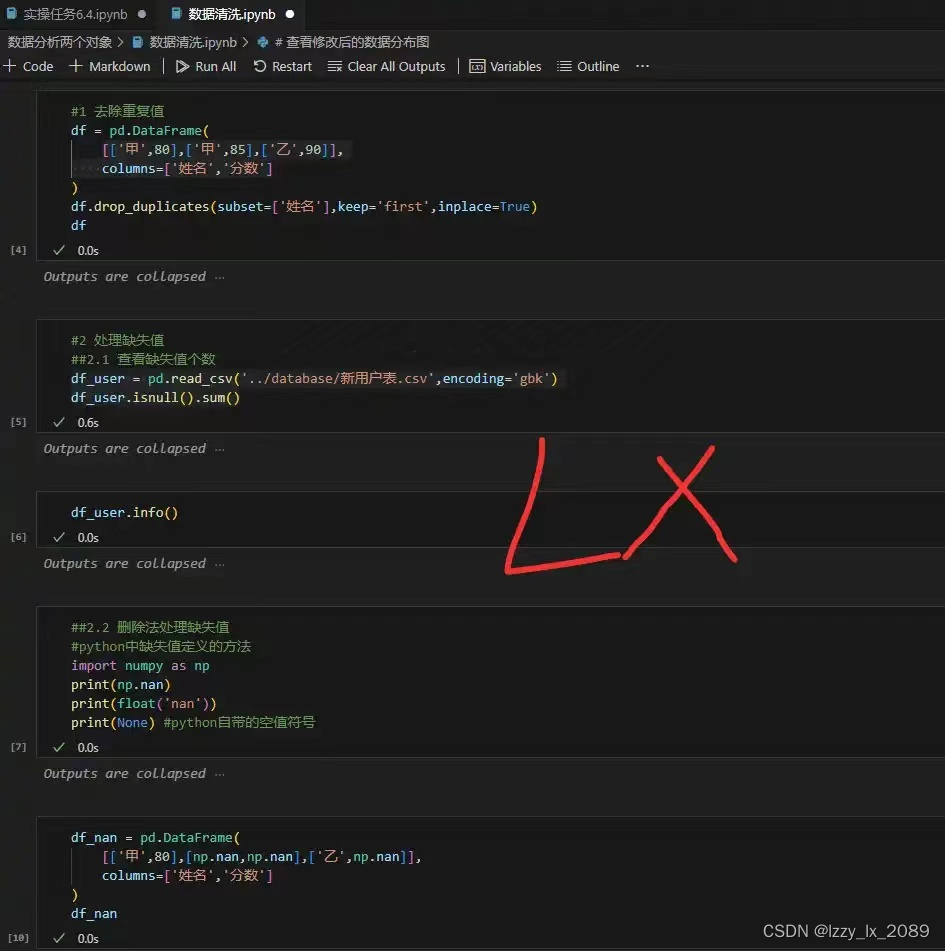
Python在机器学习和数据建模方面也有广泛应用。Scikit-learn是一个非常流行的库,适用于实现各种机器学习算法,如分类、回归、降维和模型选择等。通过学习这些内容,我不仅掌握了数据分析的技术手段,还了解了如何利用机器学习方法解决复杂的实际问题。
数据分析是一个不断发展的领域,新的技术和工具层出不穷。因此,持续学习和跟进最新的技术动态是非常必要的。通过阅读最新的文章和参加相关课程,我不断提升自己的技能水平,并保持对新技术的敏感度。
总之,Python数据分析不仅让我掌握了强大的数据处理和分析工具,还让我认识到理论与实践相结合的重要性。通过不断学习和实践,我相信自己能够在数据分析领域取得更大的进步和成就。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









