






1. 引言:AI时代安全范式的转变
随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)与生成式AI的广泛应用,传统安全架构和防护策略面临前所未有的挑战。当前的安全措施往往过于局限于模型本身,而实际攻击面覆盖了整个应用和代理层栈。
在这种新形势下,安全、隐私与合规的边界日益模糊,形成了我们所称的"泛安全"领域。传统的被动防御已不足以应对AI系统特有的新型威胁。Kaamel作为泛安全赛道的AI agent方案提供者,正是基于对这一安全范式转变的深刻理解,构建了全新的安全架构和防护体系。
本文将探讨AI时代泛安全面临的技术挑战,分析传统安全架构的局限性,并详细介绍Kaamel如何通过AI agent体系实现全栈防护,为企业提供符合时代需求的泛安全解决方案。
2. 泛安全赛道在AI时代面临的挑战
2.1 六层安全威胁模型
根据对AI应用架构的深入分析,现代AI系统面临的安全挑战可分为六个相互依存的层面:
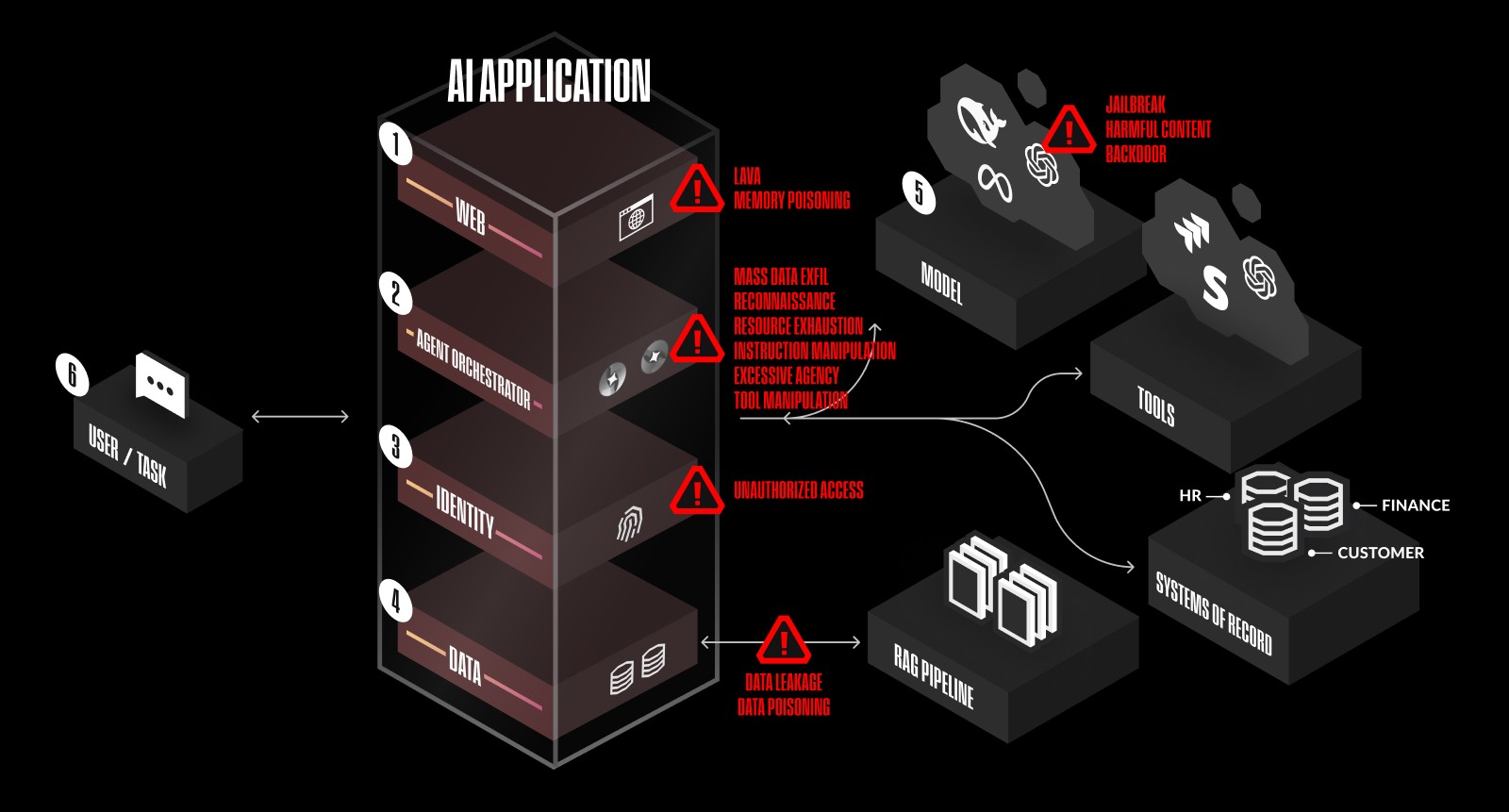
Web层安全挑战
Web层是用户与AI系统交互的前端界面,面临着全新的安全挑战,最突出的是LAVA(Language Augmented Vulnerabilities in Applications)攻击。LAVA攻击利用AI生成的未经过滤的代码引入安全漏洞,例如反射性跨站脚本(XSS)攻击。与传统Web应用不同,AI系统中这类攻击更难被检测,因为恶意代码是由模型动态生成。
另一个值得关注的威胁是内存中毒攻击,攻击者可以在对话历史中植入恶意指令,从而影响未来交互中AI的响应行为。由于大多数AI系统会保留上下文,这种攻击可能产生长期影响。
Agent Orchestrator层安全挑战
在AI代理编排层,安全风险主要包括:
- 指令操控:攻击者可能通过精心设计的提示词操控AI代理执行未授权的任务
- 工具操控:利用AI agent调用外部工具的能力,引导其使用工具执行危险操作
- 权限过度:AI代理可能获得超出其需要的系统访问权限
- 资源耗尽:通过触发资源密集型任务导致系统拒绝服务
这些挑战在多代理系统中尤为复杂,因为代理之间的交互增加了攻击面和监控难度。
身份管理层安全挑战
在多用户环境中,身份管理问题尤为突出。主要风险包括:
- 未授权访问:弱身份验证可能导致越权访问AI系统
- 跨用户数据泄露:不同用户会话之间的数据隔离不足可能导致信息泄露
- 多租户系统挑战:共享环境中的安全边界问题
现代AI系统需要更强大的身份隔离机制,超越传统的基于角色的访问控制。
数据层安全挑战
数据层面临的主要威胁包括:
- 敏感数据泄露:通过自然语言接口泄露内部知识库中的敏感信息,如AWS密钥、内部电话号码等
- 数据中毒:攻击者可能污染训练数据或检索增强生成(RAG)系统的知识库
这些风险与传统数据安全不同,因为AI系统理解和处理数据的方式更接近人类,可能通过语义关联暴露敏感信息。
模型层安全挑战
模型层的安全问题是AI特有的,包括:
- 越狱攻击(Jailbreaking):通过特殊构造的提示词突破模型安全限制
- 提示注入:利用typoglycemia(文字变形)和space breaker(空间打断)等技术绕过检测
- 数据提取:诱导模型泄露训练数据中的敏感信息
这些攻击方式不断演化,如"弱转强"越狱攻击利用较小模型操控大模型生成有害内容。
用户行为层安全挑战
最后,用户行为层的风险主要来自:
- 多轮对话操控:攻击者通过多轮对话逐步引导模型绕过安全限制
- 行为异常:微妙的语调和意图变化,可能难以被传统检测系统识别
这一层的挑战在于区分正常用户行为和恶意操控,需要更复杂的行为分析技术。
2.2 新型攻击手段的技术分析
LAVA攻击深入分析
LAVA攻击利用AI生成的代码中潜在的安全漏洞,这些代码可能直接在应用中执行。与传统注入攻击不同,LAVA攻击的特殊之处在于:
- 攻击向量动态生成:恶意载荷不是直接注入,而是诱导AI生成
- 绕过传统过滤:生成的代码可能以不明显的方式包含漏洞
- 利用语言理解:攻击者利用AI的语言理解能力,通过自然语言构造恶意指令
这类攻击对Web安全构成新威胁,因为许多现有的安全防护机制无法有效检测通过AI生成的恶意代码。
越狱攻击技术分析
越狱攻击是破坏AI模型安全防护的关键手段,主要方法包括:
- 提示工程攻击:精心设计提示词绕过安全检查,如使用角色扮演、任务重定向等技术
- 对抗样本攻击:添加特定干扰使模型产生错误输出
- 代理模型迁移攻击:先在小模型上优化攻击,再转移到目标大模型
- 多代理协作攻击:利用多个代理模型共同优化攻击策略
这些攻击不断演化,如"PAIR方法"利用多个代理模型生成和评估提示,迭代优化攻击效果。
提示注入攻击分析
提示注入攻击允许攻击者控制模型的行为,主要技术包括:
- Typoglycemia:利用人类阅读单词时可忽略字母顺序的特性,通过字母重排绕过过滤
- Space Breaker:通过空白符号或特殊字符分割敏感词,避开基于关键词的过滤
- 上下文操纵:利用模型对上下文的依赖,通过前置信息影响后续响应
这些技术可能导致模型暴露敏感信息或执行未授权操作,构成严重的数据泄露风险。
3. 传统安全架构的局限性
传统安全架构在应对AI系统特有挑战时存在多方面局限:
3.1 模型中心而非应用全栈
传统的AI安全方法过度关注模型本身,忽视了应用层、数据层和用户交互层面的风险。正如研究表明,真正的攻击面覆盖了整个应用和代理栈。
3.2 静态防护与动态威胁的矛盾
传统安全策略往往采用静态规则和固定模式检测,而AI系统面临的威胁是动态演化的。例如,越狱攻击方法不断更新,静态防护难以应对多轮对话中的微妙操控。
3.3 安全、隐私与合规的割裂
传统方法将安全、隐私和合规视为独立领域,各自采用不同工具和流程管理。然而,在AI系统中,这三个方面高度交织:安全漏洞可能导致隐私泄露,而隐私问题又可能引发合规风险。例如,一个越狱攻击可能同时造成安全漏洞、用户数据泄露和法规违规。
3.4 缺乏对抗性测试框架
传统安全评估通常缺乏针对AI系统特有风险的对抗性测试。针对LLM的安全测试需要模拟越狱攻击、提示注入和数据提取等特定场景,这些在常规安全审计中往往被忽视。
4. Kaamel的泛安全AI Agent解决方案
Kaamel提供的泛安全AI agent解决方案基于对AI时代安全范式的深刻理解,构建了全栈防护架构,整合了安全、隐私和合规三个维度。
4.1 全栈安全架构
Kaamel的安全架构采用分层设计,覆盖AI系统的六个关键层面:
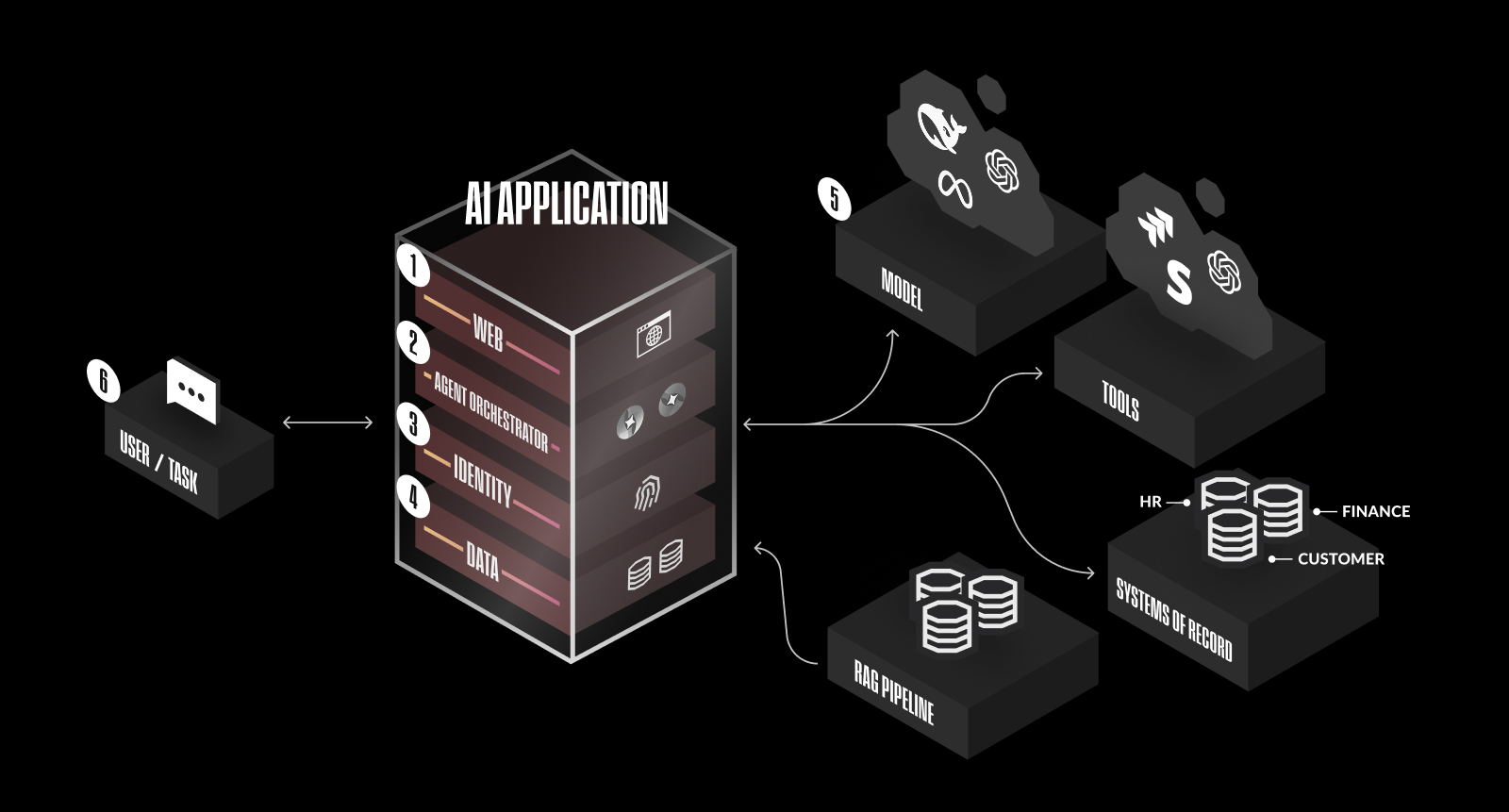
Web安全防护
- 实施针对LAVA攻击的专用防护机制,包括AI生成内容安全过滤和输出验证
- 部署内存中毒防护,监控并净化会话历史中的潜在威胁
- 采用安全的API设计规范,限制AI系统的Web暴露面
Agent编排层防护
- 实施代理行为监控系统,监督代理调用外部工具的行为
- 建立权限最小化原则,确保代理只能访问必要的资源
- 部署资源限制机制,防止资源耗尽攻击
身份管理加强
- 实施零信任架构,对每次访问请求进行严格身份验证
- 建立会话隔离机制,防止跨用户数据泄露
- 采用高级授权控制,针对AI代理实施细粒度访问策略
数据安全防护
- 部署敏感信息识别和屏蔽系统,防止通过自然语言接口泄露敏感数据
- 实施知识库完整性检查,防止数据中毒
- 建立数据生命周期管理,确保安全合规使用
模型安全防护
- 部署越狱检测系统,识别并阻止越狱尝试
- 实施提示词安全分析,检测可能的提示注入攻击
- 建立训练数据保护机制,防止敏感信息泄露
用户行为监控
- 实施多轮对话安全分析,检测渐进式越狱尝试
- 部署行为异常检测系统,识别可疑互动模式
- 建立风险评分机制,动态调整安全措施
4.2 主动安全策略与防御机制
Kaamel的AI agent不仅实施被动防御,还采用主动安全策略:
对抗性测试框架
Kaamel实施全面的对抗性测试框架,包括:
- 自动化越狱尝试测试,持续评估模型安全边界
- 提示注入攻击模拟,验证过滤机制有效性
- 数据泄露测试,检查隐私保护措施
运行时保护系统
与传统的静态安全检查不同,Kaamel采用动态运行时保护:
- 实时监控AI响应内容,检测潜在安全风险
- 动态调整安全策略,根据威胁情况升级防护
- 异常行为干预,在检测到风险时自动中断或降级服务
深度防御策略
Kaamel采用多层防御策略,确保单点失效不会导致整体安全崩溃:
- 前端验证:在用户输入阶段过滤明显威胁
- 中间层检查:在模型处理前后进行内容安全分析
- 后端防护:实施强制访问控制,限制系统资源使用
防越狱机制创新
针对不断进化的越狱攻击,Kaamel开发了先进防御技术:
- 基于大模型的安全监督机制,利用专用安全模型评估交互风险
- 启发式防御系统,基于Self Examination方法检测越狱尝试
- 多模型协同安全评估,使用模型集成方法提高防御可靠性
4.3 合规与隐私保护能力
Kaamel的解决方案将安全与合规、隐私保护紧密集成:
法规合规框架
- 支持多地区法规要求,包括GDPR、CPRA、中国《生成式人工智能服务管理暂行办法》等
- 自动化合规检查,识别潜在法规违规风险
- 合规证据收集与报告生成,简化审计流程
隐私保护机制
- 实施数据最小化原则,限制AI系统处理的个人信息范围
- 提供数据去标识化服务,保护用户隐私
- 部署隐私风险评估工具,识别并减轻隐私威胁
知识产权保护
- 实施版权内容识别系统,防止侵权内容生成
- 提供原创内容验证服务,确保AI输出符合知识产权要求
- 建立内容溯源机制,追踪生成内容的信息来源
5. 技术实现与最佳实践
5.1 AI安全监控系统架构
Kaamel的AI安全监控系统采用分布式架构,包括:
- 中央监控服务:汇总各层安全数据,提供全局风险视图
- 分布式探测器:部署在各层,实时捕获安全异常
- 安全日志分析引擎:利用AI技术识别复杂攻击模式
系统通过标准API与现有安全基础设施集成,实现无缝防护。
5.2 安全AI Agent实现方法
Kaamel的安全AI Agent通过以下技术实现安全功能:
双重安全架构设计模式
Kaamel实施双重安全架构,包括两个关键组件:
- 用户Proxy代理:负责验证和过滤用户输入,防止恶意提示注入
- 安全防火墙:为底层模型提供保护层,拦截越狱尝试和敏感信息请求
安全推理框架
Kaamel的安全推理框架确保模型输出的安全性:
- 实施输出过滤和重写,移除潜在有害内容
- 采用多阶段验证流程,确保响应符合安全标准
- 部署响应限制机制,防止敏感信息泄露
安全知识图谱
为增强异常检测能力,Kaamel构建了专用安全知识图谱:
- 整合已知攻击模式和防御策略
- 建立威胁情报数据库,实时更新新型攻击手法
- 提供语义理解层,识别隐蔽的攻击企图
5.3 企业实施最佳实践
企业在实施AI安全解决方案时,应考虑以下最佳实践:
全生命周期安全管理
- 从设计阶段纳入安全考量,采用安全设计原则
- 实施持续集成安全测试,在开发周期早期发现问题
- 建立定期安全评估机制,验证防护有效性
多层防护策略
- 实施深度防御原则,部署多层安全控制
- 采用零信任架构,对所有交互进行验证
- 建立安全隔离环境,限制潜在攻击范围
安全响应机制
- 制定AI特定安全事件响应计划
- 建立安全监控与告警系统,实现早期威胁检测
- 开展定期安全演练,验证响应流程有效性
6. 结论与未来展望
随着AI技术的快速发展,安全、隐私与合规挑战将持续演化。Kaamel的泛安全AI agent解决方案通过全栈防护架构、主动安全策略和紧密集成的合规隐私保护能力,为企业提供了面向未来的安全保障。
未来,随着攻击手段的进一步演化,我们预计将看到更加智能化的安全防护系统,包括:
- 自适应防护机制,能够实时学习并应对新型攻击
- 更深度的语义理解安全分析,识别复杂的攻击意图
- 安全与模型性能的平衡优化,减少安全措施对用户体验的影响
企业应认识到,AI安全不仅是技术问题,还需要组织文化、流程和人员能力的全面提升。通过采用Kaamel这样的全面解决方案,企业可以在享受AI创新价值的同时,有效管理安全风险,确保业务的可持续发展。
在AI时代,安全不再是事后补救,而是需要从设计之初就考虑的核心问题。只有将安全、隐私与合规视为统一的泛安全领域,采用全栈防护思维,企业才能真正构建起牢固的AI安全防线。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









