






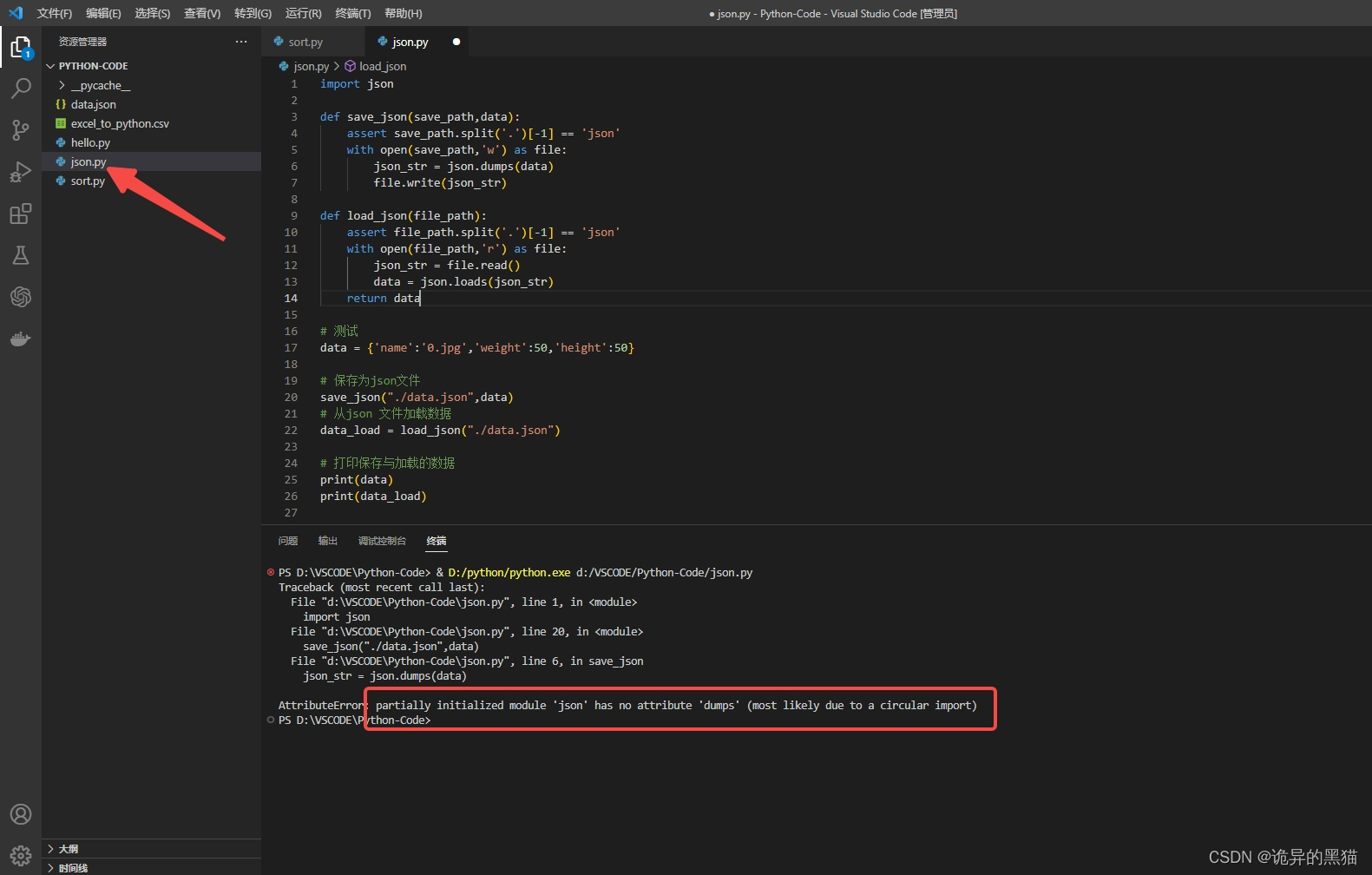
第一步:文件命名
由于我的py文件命名为json.py,导致引用时报错:
partially initialized module 'json' has no attribute 'dumps' (most likely due to a circular import)部分初始化的模块“json”没有属性“dumps”(很可能是由于循环导入)
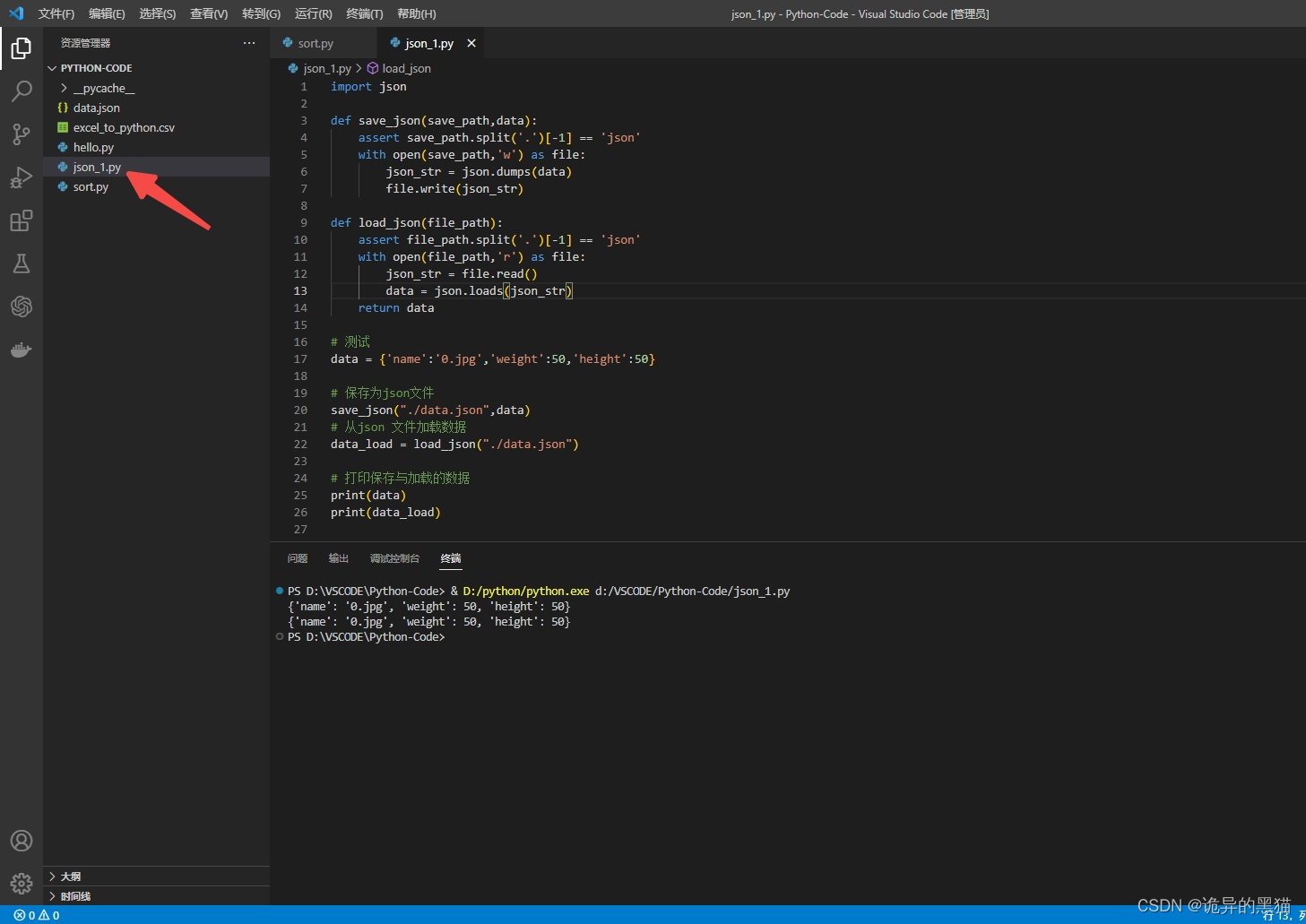
后面修改成json_1.py,再次执行就没问题了。
第二步:数据导入
可以使用两种方法生成数据表
1、文档导入:通过Excel文档导入,把Excel文档放到python安装目录下后执行以下语句:
df=pd.DataFrame(pd.read_excel('name.xlsx'))2、语句生成:按照0-99进行补位,生成一个数据表
a = np.arange(100,dtype=float).reshape((10,10))
for i in range(len(a)):
a[i,:i] = np.nan
df = pd.DataFrame(data=a,columns =['a','b','c','d','e','f','g','h','i','j']
#以上语句会生成10行的数据表,因此需要有10个列名columns,列名可自行定义
第三步:数据修改
前面将部分数据填充成nan,以下语句将所有nan替换成0
df.fillna(value=0)
#fillna()方法默认不会修改原DataFrame,需要将填充后的结果重新赋值给原DataFrame才能生效。因此,正确代码应该是:
df.loc[:,['a','b','c','d','e','f','g','h','i','j'] = d.loc[:,['a','b','c','d','e','f','g','h','i','j']].fillna(0)第四步:数据导出
将df表的数据导出到CSV文档,路径在python安装目录
#输出到 CSV 格式
df_inner.to_csv('excel_to_python.csv')完整代码
json_1.py
import json
print(json.__file__)
def save_json(save_path,data):
assert save_path.split('.')[-1] == 'json'
with open(save_path,'w') as file:
json_str = json.dumps(data)
file.write(json_str)
def load_json(file_path):
assert file_path.split('.')[-1] == 'json'
with open(file_path,'r') as file:
json_str = file.read()
data = json.loads(json_str)
return data
# 测试
data = {'name':'0.jpg','weight':50,'height':50}
# 保存为json文件
save_json("./data.json",data)
# 从json 文件加载数据
data_load = load_json("./data.json")
if __name__=='__main__':
# 打印保存与加载的数据
print(data)
print(data_load)
sort.py
import numpy as np
import pandas as pd
from json_1 import save_json,load_json
# 测试
# data = {'name':'0.jpg','weight':50,'height':50}
# 保存为json文件
# save_json("./data.json",data)
# 从json 文件加载数据
# data_load = load_json("./data.json")
# 打印保存与加载的数据
# print(data)
# print(data_load)
a = np.arange(100,dtype=float).reshape((10,10))
for i in range(len(a)):
a[i,:i] = np.nan
df = pd.DataFrame(data=a,columns =['a','b','c','d','e','f','g','h','i','j'])
print(df)
# d.loc[:,['a','b','c']] = d.loc[:,['a','b','c']].fillna(0)
# print(d)
df.fillna(method='ffill',limit=2,inplace=True)
print(df)
# 用0填补空值
# print(df.fillna(value=0))
# df.fillna(value=0)(不适用,改成下面的语句)
# fillna()方法默认不会修改原DataFrame,需要将填充后的结果重新赋值给原DataFrame才能生效。
# df.loc[:,['a','b','c']] = d.loc[:,['a','b','c']].fillna(0)
# 用前一行的值填补空值
# print(df.fillna(method='pad',axis=0))
# 用后一列的值填补空值
# print(df.fillna(method='backfill', axis=1))
# df.fillna(method='bfill', axis=1, inplace=True)
# 连续空值,最多填补3个
# print(df.fillna(method='ffill',axis=0, limit=3))
# 每条轴上,最多填补3个
# print(df.fillna(value=-1,axis=0, limit=3))
#输出到 CSV 格式
# df.to_csv('excel_to_python.csv')















 3052
3052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









