









前言
当大家提到存算分离时,尤其是考虑后端使用 AWS S3 为代表的对象存储作为数据存储时,直觉就是性能拉胯,只能用作批量数据处理场景,至少这是我在跟很多用户交流时获得的第一感受。而 StarRocks 作为一个具备强实时性数据分析引擎,在引入了存算分离架构后,又能否能胜任实时场景呢,无数用户心理可能会打个问号。我们内部也考虑到了用户的心声,在新版本中引入了一键性能飞升能力,当然,多说无益,我们拿实际测试来说话。
我们今天测试的核心就是使用 StarRocks 存算分离最新版本,在开启内部的 事务提交 Batch 优化后,性能能否飞升。需要说明的是,相比于绝对数值,我们更关心优化后性能提升的比例。
测试环境
测试使用了1个 FE + 3 CN 配置,使用 StarRocks 最新版本 3.2.3,FE 使用的是 4 Core 16G 配置,CN 使用 8 Core 32GB 配置,机器均直接采购自 AWS,测试使用的对象存储也来自 S3。
另外,为了充分发挥写入性能,测试中调整计算节点与 IO 相关配置以获得更好的写入性能,剩下的都采用了系统默认值:
update information_schema.be_configs set value = 32 where name like 'flush_thread_num_per_store';
update information_schema.be_configs set value = 32 where name like 'number_tablet_writer_threads';
测试方法
测试使用了 TPC-DS 的 store_sales 表(明细模型),测试过程中将会使用不同的客户端并发数同时向该表中导入数据,使用 stream_load 方式导入数据,并发数会一直从 1 递增至256,每个导入线程会不间断地连续进行数据导入。单次导入文件大小为 1MB,以此来模拟高并发下数据实时入湖场景。
测试的最后,将导入吞吐作为衡量最终性能表现的标准,我会一直压测直到达到测试环境下的吞吐上限。
测试结果
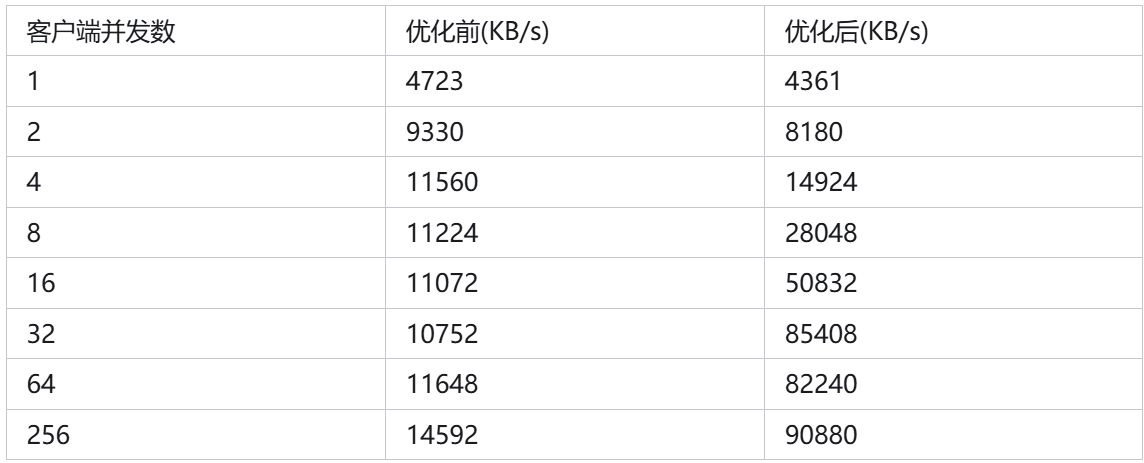
惊不惊喜,意不意外。上面的测试证明了,即使存算分离架构,我们也可以极速提升实时数据入湖的性能,上面的简单测试显示高并发下,数据入湖吞吐提升5倍以上。而且,并发越高,性能提升效果越显著,在某些用户那我们观察到性能最多可提升10倍以上。
目前已经有不少用户开始去测试高频高并发的实时数据摄入能力,在这里,我也邀请大家来尝试尝试,只需要你升级到 3.2.3 版本后,动动手指,一个命令,性能飙升带回家:
admin set frontend config("lake_enable_batch_publish_version"="true");
后面我也会专门再写一篇原理性文章来阐述内部实现原理,敬请期待。
写在后面
实际上,大家对对象存储一直存在的误解是性能差。这里需要说明的是,对象存储在 IO 延迟上相比于本地盘确实要高出 1 ~ 2 个数量级,但对象存储胜在高吞吐能力,AWS S3 单 Bucket 的最高吞吐甚至能达到数百 GB。因此,我们无论是在系统设计还是使用上都要充分掌握和利用这个特性,扬长避短,后面会找个机会给大家介绍下 StarRocks 存算分离内到底做了什么,让实时性能脱胎换骨。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









