







1.准备功课
爬虫又称为网页追逐者,从网页中获得有用的数据,爬虫的工作流程如下:
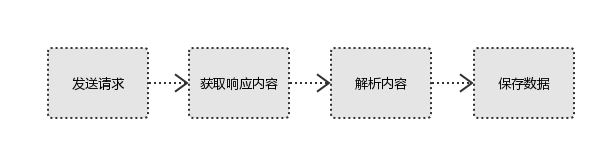
(1) 发送请求(request)与获取响应(response)
respose=requests.get('http://www.xiaohuar.com/')
print(respose.text) #返回文本内容
(2) 解析内容: 对响应的文本内容进行处理 常用解析库:正则,beautifulsoup,pyquery
(3)保存数据 存储库:文件,MySQL,Mongodb,Redis
- 实战:从http://www.xiaohuar.com/ 爬取美女图片,保存到本地
import re
import requests
respose=requests.get('http://www.xiaohuar.com/')
print(respose.text) #返回文本内容
urls = re.findall(r'img src="(.*?)"',respose.text,re.S)
for i in range(1,len(urls)):
img = requests.get(urls[i])
filename = 'xiaohua'+str(i)+'.jpg'
with open('./xiaohua/'+filename,'wb') as f: f.write(img.content)
结果爬到了21张图片,如下:

tips: 第一个爬虫实例,只是用了正则表达式进行了简单解析,获取的图片网址,第一个是有些问题的,直接跳过了















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









