






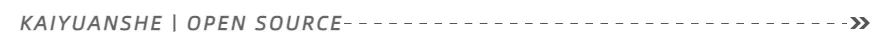

前一阵子的开源和闭源之争炒的比较火热,之前一直想写点什么,由于太懒就没写,但是最近开源模型真的太火爆了,前有 Grok-1、Mistral-8x22、Llama3,后有Yi-1.5、Deepseek-V2、Qwen1.5-110B,开源模型现在真的卷到飞起。
今天简单聊聊下面的几点内容,欢迎大家拍砖,给出不同看法:
开源模型有哪些优势
开源模型与闭源模型的差距会越大还是越小
开源模型哪家强

个人认为,开源大模型是让大模型行业卷起来的根源。
在 ChatGPT 刚刚出来的时候,业内满是焦虑;在 Llama 开源之后,业界满是兴奋,因为更多人看到了光。
开源的优势主要是人多,可能有人会反驳说AI需要高精尖的人才,但老话不是常说三个臭皮匠顶个诸葛亮嘛。(很多大佬其实也是没有什么资源,从头预训练的资源消耗真的太大了)
人一多,点子就多,就会衍生出很多大模型相关 Trick,就像如何进行上下文扩展(NTK、YaRN、LongLora 等)、如何小代价进行模型 Merge 得到更大更好的模型(SOLAR、Llama-Pro 等)、如何更好更高效地进行人类偏好对齐(DPO、ORPO 等)等等等。如果没有好的开源模型,很多研究也许就没法涌现出来。
更多人涌入到大模型相关研究中,总会给大模型的发展带来积极的作用。闭源大模型团队的人也可以从外界汲取一些方法,来进一步提升模型本身效果。
随着微调项目的开源、部署框架的不断开源、进步,现在很多中小企业和开发者可以很快地用上大模型,摸清大模型落地的边界,让大模型产品有更多的玩法、可操作性更强,进而会推动AI的落地发展。
就像网上基于通义千问的开源大模型 Qwen1.5-110B 模型微调后的效果远超原始模型一样,开源亦有能量。
当然上面只是从技术思维来讲开源的好处,但不可否认的是开源的商业模式确实不明朗,很难避免白嫖的现象。
我觉得从现在 GPU 的成本来看,很多选择开源模型的企业还是在 10B 参数规模,太大了成本也兜不住,还不如选择 API,那么这时候占据开源市场的头部企业的机会不就来了嘛。
开源大模型跟闭源大模型最后应该是相辅相成的,只是不同人群用的不同。穷玩家、愿意钻研的玩家、需要有更多私有化定制的玩家,可能选择去玩开源大模型。富有玩家、想伸手就用的玩家、追求更高逼格的玩家,可能选择去玩闭源大模型。

个人认为,开源大模型跟闭源大模型最后应该是相辅相成的。
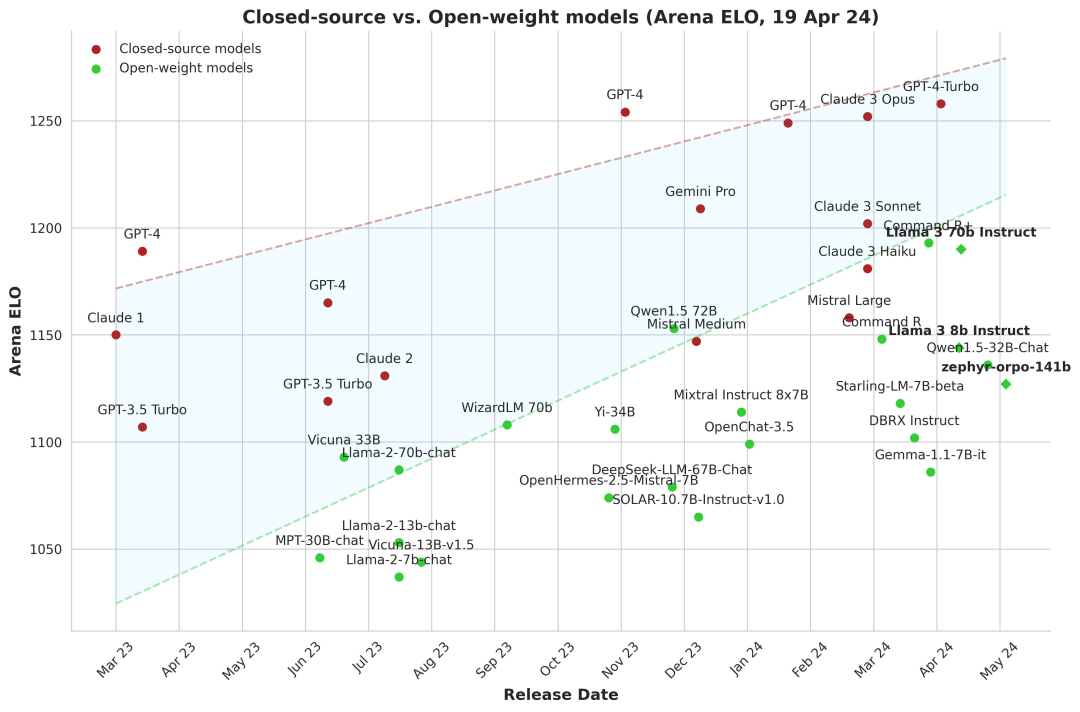
lmsys.org对战分数图

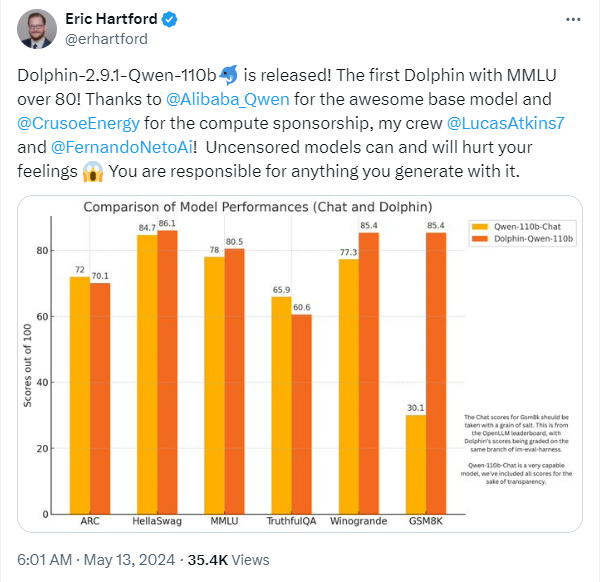
真的不敢想想大模型发展会这么迅猛,不敢想想之前惊为天人的 GPT3.5 都已经不配跟头部开源模型对标,都在对标 GPT4。
从对战榜单上来看,头部模型中,开源模型占比不在少数,可以感觉出来差距在减小。从体验上来说,头部开源模型得效果也是不错的。
闭源有数据壁垒,确实很难追,只能靠头部开源组织发力,个体或者小组织只能缝缝补补啦,反正 Pre-train 真是做不了。
但也请别小瞧缝缝补补的工作,反正一些任务微调微调 72B 模型真能干过 GPT4 的。

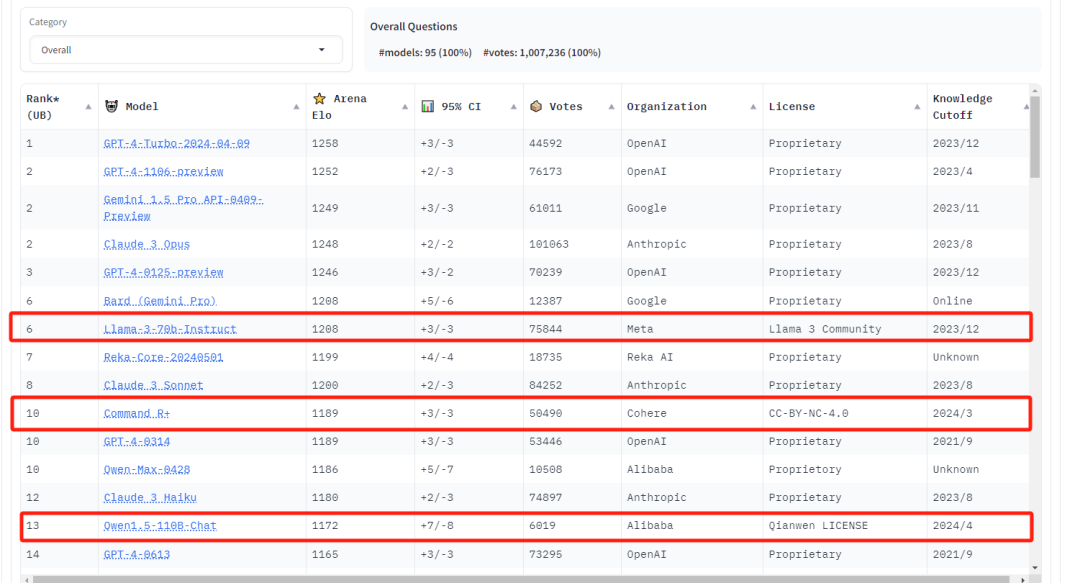
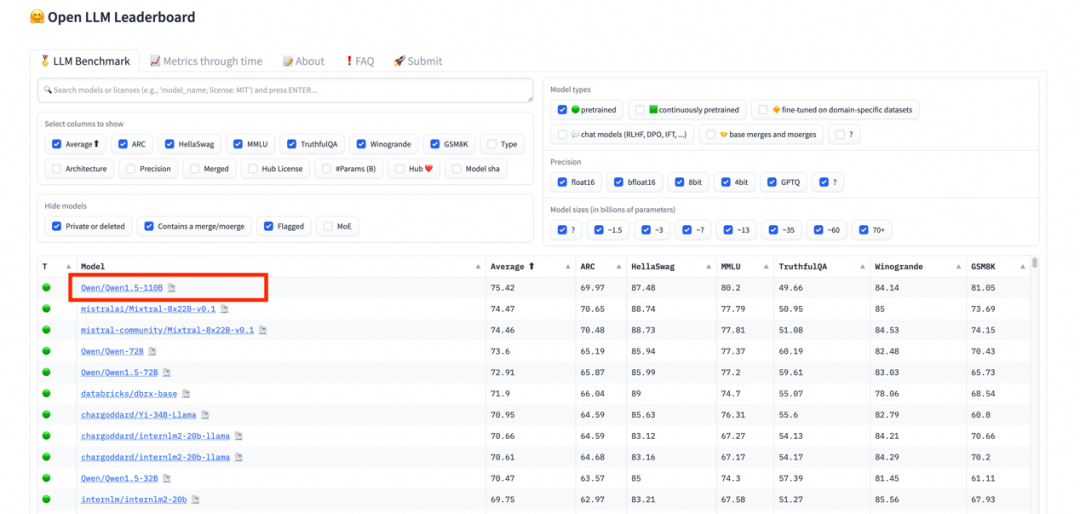
现在开源模型还是比较多,但国内的话,目前我认为是阿里云的通义千问,强不仅在效果上,还体现在全面性上。我之前就写过《中国人自己的Llama:Qwen1.5开源110B 参数模型》。
Qwen 是真开,1.5系列从0.5B、1.8B、7B、14B、32B、72B 开到现在的 110B、还有 Code 系列模型、 MOE 系列模型,1系列还有 VL 模型,全全全。
不管你需要多大尺寸的模型,Qwen 都能满足,并且效果都很棒。在 HuggingFace 推出的开源大模型排行榜 Open LLM Leaderboard 上,Qwen1.5-110B 超越了 Meta 的 Llama-3-70B 模型,冲上榜首,证明其实力真的很强。
据不完全统计,现在 Qwen 开源模型下载了超过了700万。
魔搭社区现在也是很能打,国内 HuggingFace 无法访问的情况下,下载模型真得靠魔搭。同时还有免费 GPU 使用时长(偶尔测测小模型完全够用),其他配套的模型训练项目、Agent 项目就不说了。
反正是应有仅有,很难不爱。
当然国内也有很多其他的开源模型,但是论全面,真还得是 Qwen。

真心要感谢头部的大模型开源组织,感觉要不是各家的施舍,可能早就告别算法岗位了。
因为有你(开源),世界变得更加美丽。
转载自丨 NLP工作站
编辑丨王军
相关阅读 | Related Reading
科技,开源,让她们看到更广的未来 - 你有没有想过,长大以后想要做什么?

开源社简介
开源社(英文名称为“KAIYUANSHE”)成立于 2014 年,是由志愿贡献于开源事业的个人志愿者,依 “贡献、共识、共治” 原则所组成的开源社区。开源社始终维持 “厂商中立、公益、非营利” 的理念,以 “立足中国、贡献全球,推动开源成为新时代的生活方式” 为愿景,以 “开源治理、国际接轨、社区发展、项目孵化” 为使命,旨在共创健康可持续发展的开源生态体系。
开源社积极与支持开源的社区、高校、企业以及政府相关单位紧密合作,同时也是全球开源协议认证组织 - OSI 在中国的首个成员。
自2016年起连续举办中国开源年会(COSCon),持续发布《中国开源年度报告》,联合发起了“中国开源先锋榜”、“中国开源码力榜”等,在海内外产生了广泛的影响力。
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









