







北京时间2024/06/14(周五)16:00-18:00,我以红象云腾创始人和开源社顾问委员的身份参加了开源社2024年第二季度顾问委员会讨论。会议在微软的 Center One 黑科技展示中心举办,同时沉浸式体验 Microsoft 所代表的未来科技。通过本次会议还有幸认识了 CCF 常务理事章文嵩老师,微软(中国)CTO 韦青老师,开源中国 Gitee 马越老师,国防科大余杰老师等开源业界大咖。


Microsoft China Center One 开源科技之旅

参观 Microsoft China Center One windows 风格展厅

体验Microsoft AI Agent 交互

体验Microsoft AI Agent 交互

体验Microsoft AI 语音合成

章文嵩老师体验Microsoft MR 虚拟现实

学习微软大厦智能楼宇设计

Emily 主持顾问委员会讨论
Linux LVS 作者,CCF 常务理事章文嵩老师和微软(中国) CTO 韦青出席讨论

章文嵩老师介绍 CCF 计算机博物馆开源展厅的设计

会议合影(我是右边第一个)
整理了一下个人思考和建议,希望通过开源社平台参与共建
- 关于CCF 章文嵩老师 主持的计算机博物馆开源展厅的设计和讨论的建议;
1.通过真人真事的故事介绍开源对个人发展和职业生涯的影响,激励在学生阶段就参与全球开源项目,可捐赠作品到博物馆并全球开源,专本硕博阶段毕业设计作品参考 LVS 开源发布,不能再压导师箱底了。
如果把每个学生学生阶段的作品当做艺术品,那被计算机博物馆以具备产权的方式收藏,也是对这件艺术品的产权价值证明了。
2.博物馆基金会要把软件产权作为收藏形态。通过博物馆收藏开源软件的版权和商标产权,并通过博物馆开源许可分发给全球,实现博物馆软件藏品的价值, 这里产权类似但有别于 Linux 或者 Apache 模式,毕竟他们都不是博物馆。
3. 增加大数据和超算视角,介绍大众很难在平常生活中看到的超级计算机硬件和开源软件内容(如果没有的话)。
4.将航天器和卫星定义为特种计算机,航天+卫星+开源主题,激发学生的探索未知世界的兴趣。
因为计算机博物馆建在金华横店,很巧的是金华也是我的家乡,也希望有机会能给故乡的计算机和开源事业添砖加瓦。
-关于开源社理事长江波主持的 OSI - Open Source AI Definition (开源人工智能的定义) ,目前正在意见征集中
我个人理解 OSI OpenSource AI 的定义的核心点在上下游产权,包含数据产权和衍生品的产权。
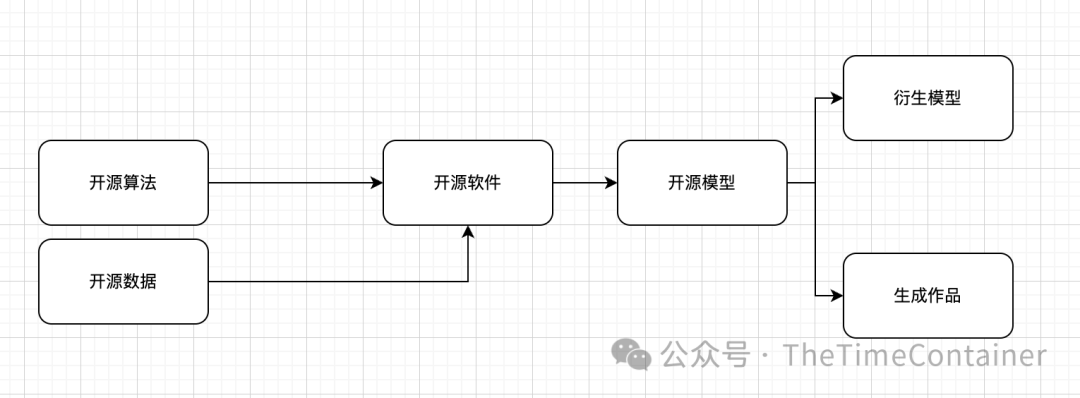
端到端的开源许可证的才能确保开源软件,训练数据,大模型,下游衍生作品等上游资源的版权确定性,比较难的是训练数据的产权。通过端到端的开源许可实现开源大模型的透明性、可参与性和广泛使用性,促进了AI开发和技术创新的合作共享。

开源社的活动勾起了这十年创业的回忆,也整理出来分享给大家。

红象云腾发源于中国 Apache Hadoop 开源社区,本着从开源中来,到开源中去的发展思想,这十几年我们一直致力于参与开源,推广开源,贡献开源。
2022年到2023年红象团队支持 Apache Ambari 复活,Ambari + Bigtop 一体化的版本最新发布,参与 Apache Bigtop 并贡献了 Apache Ranger 组件,早先还和 IBM 研究院一起支持 OpenPower Hadoop EC 加速代码研发和贡献等社区工作。
去年我去北美考察,有幸在微软大会认识 Emily,并结缘开源社,通过开源社活动我们能结识很多业界老师和朋友,我也希望能将我们对开源,创业的探索介绍给大家,在当前这个特殊的时间点,创业并不是一个特别正向的主题,但背后的故事和思考我相信永不过时,历史会记住那些敢于探索的个体以及背后奋斗故事。
LVS 作者章文嵩老师的成功故事一直激励着我们在开源软件领域不断前行探索。微软比尔盖茨关于未来之路的思考启发着我们对软件商业化的探索。可以说没有开源软件精神和未来之路的思想指导,就不会诞生红象云腾这家致力于在中国普及推广 Apache Hadoop 生态为己任的开源软件公司,转眼我们为这个目标努力的整整十二年,如果从2004年我开始接触开源软件和分布式思想,我的计算机启蒙老师王永指导我创作以我和比尔盖茨合影为背景的未来之路个人海报开始,已经过去了二十年。
我在大学是 Google 技术爱好者,2004年第一次接触到 Google 发布的 GFS,BigTable,MapReduce,PageRank 等开放论文,许下要学习并参与研发亿万用户级别的搜索引擎的努力目标,因为当时痴迷于 Google 技术和创业故事,2006年我来北京求学,学习搜索引擎和编程技术,当时学习地方在北大理教楼,靠近北大天网搜索引擎实验室。通过研读 Google 研究员吴军老师写的数学之美来学习搜索引擎数学原理,并通过学习到的编程技术研发基于 Apache Lucene 的搜索引擎和推荐系统。
2007年,我加入 FeedSky 类似美国 Feedburner 公司,在这家公司研发了人生第一个商业搜索 FeedSearch,系统索引上亿篇 Blog 文章,通过对数学之美里面关于文档分类,自然语言处理等数学理解,研发了 Blog 文章分类器,样本测试准确度达到80%左右,还可以识别文章作者的情感和作者男女性别。同时参考 PageRank 系统,思考博客背后人与人 PeopleRank,思考通过人与人的关系推荐博客文章的技术。当时我们另外一个 C++ 团队研发了 MCC 队列,技术类似 Apache Kafka 系统,非常优秀的作品,可惜当年没有开源。
从2008年开始,我加入暴风科技陆续带领研发搜索引擎,大数据,推荐系统等项目团队研发产品。通过开源软件技术研发搜索引擎,通过分布式大数据技术升级了用户行为分析系统,用户标签系统,推荐系统等。
2008年到2012年期间,我们研发团队在技术攻关过程中也使用大量开源项目,比如基于 Nginx + perl 构建高性能日志接收系统。基于 Lucene + Redis + lighttpd + LVS 构建站内搜索视频搜索,通过 Mysql + HttpClient 研发 Spider 视频内容爬虫技术,并收录全网千万个视频内容,实现全网视频搜索引擎易览。通过 Apache Hadoop + Hive + Python 构建暴风大数据系统,并孵化了 EasyHadoop,PhpHiveAdmin, Cronhub,ComETL 等开源大数据开源工具链项目,以上视频播放系统服务了中国当时四个亿的桌面电脑用户,几乎每台电脑都有暴风公司研发的视频播放软件,也将我们团队研发的搜索和大数据系统带进千家万户。
2010年,我认识到这些分布式计算技术在国内存在普遍需求,本着从开源分享精神,开始将团队了解的技术通过一系列技术分享活动介绍给国内更多个人和企业,于是便有了 EasyHadoop 技术社区,第一场活动在暴风音影会议室举办,记得来了20多人,第八次在软件所举办来了500多人,QQ 群到5000人,社区参与者很多已经是业界知名公司大数据领域的扛把子,也有目前头部开源软件领域的创始人。
后来从我们团队也走出了包括腾讯云/电信云的研发管理者,TikTok 关键项目研发管理者,编写多篇顶刊论文的清华大学计算机博士等计算机行业奋斗者。
2012年,社区知名度和影响力发展到一个高度,Hadoop 技术社区居然出现商业价值,在个人创业使命感驱动下我开始筹备创业的事情,当然也有外部诱惑,我的三天培训收入已经超过在暴风的月收入。
在没有商业运营经验的情况下,尝试社区商业化开发,期间因为没有一个好的社区治理模式,也导致社区出现分裂,社区是大家的(公共的),而公司是私有的(明确的股份)。团队因为商业化出现了合作和信任危机。
如果当年能有类似开源社这种治理架构,实现社区和商业的共存,我们驱动的 Hadoop 社区应该有更强大的生命力。Hadoop 核心团队在商业化上的分歧导致的社区生命力的衰弱至今都是我这辈子永远的伤痛,当然这个问题在当前开源软件领域还是广泛存在。
一个好的社区治理模式,配合一个好的公司治理架构,是开源软件公司成功的基础,这方面就需要学习 Microsoft,Google 等创始人启动创业故事,合作默契,并能互补的团队总是万里挑一,这方面我也是第一次创业缺乏对人性和商业的理解,跌跌撞撞走了近十年。
2013年,原来 Hadoop China 大会会务团队何建军团队找到我,希望我能支持 China Hadoop summit 大会,我和星环的创始人都是联合主席,活动最多来了2000多开发者。
2014年 CSDN 极客帮蒋总和传智教育黎老师,暴风财务 VP 曲总对红象提供了百万级的天使投资。
基于对开源软件生态的理解,我带领红象云腾致力于成为各个芯片,云计算生态的关键构成部分,通过支持龙芯,飞腾等芯片,麒麟操作系统研发支持多芯片大数据平台。通过和 Microsoft,IBM 等都有项目和产品合作,支持了 Lenovo,Shein 等 Azure 云上大数据项目。
2015年我们通过浪潮公司开始参与建设了中国资源卫星应用中心的首个PB遥感大数据平台,首颗卫星是高分四号 高时间分辨率定轨道卫星,通过分布式改造,数据系统处理速度从 单轨1个小时,缩短到10分钟,满足了气象局对于气象预报,森林防火等应急需求。后来陆续建设了高光谱分辨率高分五号,高空间分辨率高景ABCD,还有电磁星等数十颗大型遥感卫星,支持中国航天事业开启大数据分布式处理新时代。
2015年,IBM和微软同时邀请我们支持他们产品,我们研发了支持 IBM OpenPower 的大数据平台,并投入研发了支持 Azure 云原生的版本。IBM 公司官网还有我们产品地址。
2017年在中国航天和 IBM 领导的支持下,我们在中关村软件园举办了新品发布,并得到国家新兴产业引导基金的子资金话要资本1000万的风险投资。
软件产业是一个全球竞争的行业,只有做到行业头部并行业领先才能有好的发展,国际化成为一个必然要走的路。2018年 IBM 邀请我们参加拉斯维加斯举办的 IBM 技术大会,我们红象云腾作为中国大数据平台参展方参加会议。
2022年云和恩墨接手了之前的天使投资,Micrsoft Azure 商务团队通过恩墨找到我们,希望我们能研发支持 Azure 云原生并兼容 AWS 的大数据平台。我们团队加班加点完成用户性能测试。后续又持续投入研发了支持多云跨云的大数据版本 Redoop Cloud,当然这个领域也是烧钱投入,在资金有限的情况下我们研发了第一个版本,可以实现支持 AWS, Azure,Aliyun QingCloud 等多个云平台的云原生的部署和快速,集群部署时间缩短到10分钟以内。
这些年比较遗憾的事情是我们一直努力做自己认为难的事情,自己认为有高价值的事情,忽略了公司盈利模型的建设,从2014年引入风险投资开始,公司一直在投入,2015-2019这几年公司高光时刻投入更大。
风险投资给企业带来了资金,也留下了退出风险。基金都是有期限的,终归要要到期退出,拿了投资也意味着企业会从无限游戏成为了有限游戏,需要通过并购或者上市来实现资本的退出。
同时企业终归需要通过盈利才能长久生存,虽然天使投资通过引入战略投资实现了退出,但后续财务投资和战略投资都需要退出窗口,这也成为摆在公司和我面前的难题,对于资本,企业投入成本等财务的把控上面我也是需要不断试错探索。
我们也在探索红象云腾的发展和盈利之路。降低管理成本,通过背靠背管理上下游合同采购,通过利益共享和风险共担的方式减少不必要的信任成本和合作纠纷。每个项目按天分阶段验收确认,独立核算,实现可复制的盈利单元。这些在当前 2B 强商务关系的社会更需要不同团队能力的配合。
一家企业需要构建一个可以复制,可量化,稳定的盈利单元,否则放大的就可能是亏损。每一笔投入都需要财务盈利测试,得到盈利数据验证。对于亏损要寻根溯源,懂得及时止损,保留实力,而不是期待不断有新的融资,毕竟能上市的企业都在少数,公司最终需要通过产品盈利养活和发展,这方面我的上个东家暴风给了行业提供了一个值得反思的案例。
不仅是技术,不同企业角色都是核心本领的,思维模式也不同,领域高手总是稀缺的 资本,管理,商务,市场,技术缺一不可,从木桶效应来看非常明显。这方面开源中国 Gitee 团队的马越老师团队就是很好的团队组合,Gitee 不管在产品和盈利模式上都具备竞争力,融资和商务能力也很强大,Gitee 目前也是我们公司唯一采购的 SAAS 产品。
中国软件公司要走向国际需要一个国际化的大船,这些年 Microsoft,IBM 等国际企业都对红象云腾都给于了巨大的信任和支持。而 Apache 基金会,Linux 基金会是建立用户基础和软件品牌的土壤。
我认为通过将自主研发的软件自建开源社区,或者贡献给基金会是建立软件品牌和国际标准的有效路径,并让软件具备更强大的社区治理模式,从而具备长久的生命力,国内 Apache Kylin 团队,Apache Dolphinscheduler 团队,清华大学 Apache Iotdb,zliilz 团队,Taos tdengine 团队,蚂蚁开源 Oceanbase 团队,Apache StreamPark 等都是这方面优秀的探索者和实践者。
记得微软(中国)CTO 韦青老师提到的开源是人类知识和文明的传承,希望我们团队能在这方面多努力,希望更多中国软件企业能在国际平台上参与开源贡献开源,成为国际软件标准的建设者。让中国软件服务全球用户,让全球开发者了解中国,共同建设软件未来。我希望在中国开源软件大发展和 AI 带来的历史变革的历程中我和团队在以后的十年中也不会缺席。
因为热爱所以相信,因为梦想所以相见。也许所谓的成功永远无法达到,但我们可以不断靠近,因为我们在通往未来的路上不断前行。
转载自 | TimeContainer
编辑 | 左文瑒
相关阅读 | Related Reading
开源社简介
开源社(英文名称为“KAIYUANSHE”)成立于 2014 年,是由志愿贡献于开源事业的个人志愿者,依 “贡献、共识、共治” 原则所组成的开源社区。开源社始终维持 “厂商中立、公益、非营利” 的理念,以 “立足中国、贡献全球,推动开源成为新时代的生活方式” 为愿景,以 “开源治理、国际接轨、社区发展、项目孵化” 为使命,旨在共创健康可持续发展的开源生态体系。
开源社积极与支持开源的社区、高校、企业以及政府相关单位紧密合作,同时也是全球开源协议认证组织 - OSI 在中国的首个成员。
自2016年起连续举办中国开源年会(COSCon),持续发布《中国开源年度报告》,联合发起了“中国开源先锋榜”、“中国开源码力榜”等,在海内外产生了广泛的影响力。
















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









