









为什么需要Cache?
从程序运行这个示例来进行解释,程序在运行时,先将执行程序从flash 加载到main memory, 然后CPU 从main memory 加载指令/数据到进行执行和计算。在不考虑cache 的情况下,整体架构可以描述为
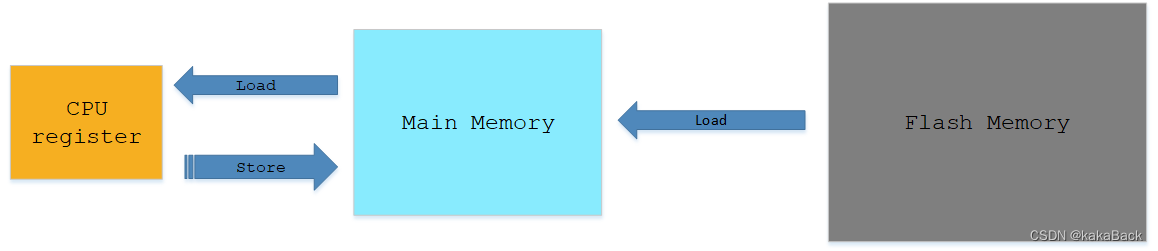
程序需要从低速设备加载到高速CPU中运行,其中速度之差如下图:
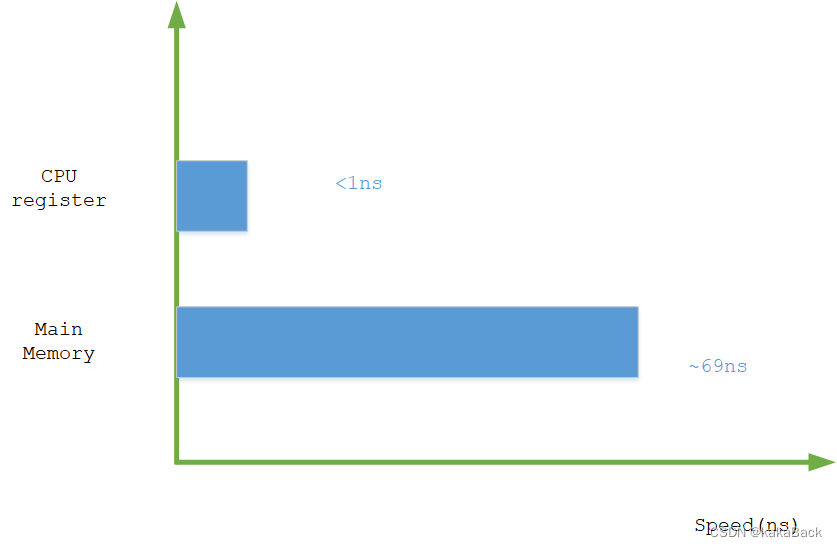
CPU register的速度一般小于1ns,主存的速度一般是69ns左右。速度差异近百倍。当CPU试图从主存中load/store 操作时,由于主存的速度限制,CPU不得不等待这漫长的65ns时间。
如何解决上述问题:
- 提升 main memory 的速度
- 降低 CPU 速度
- 增加小而高速缓存
对于方法1当前 main memory 一般是 G 为单位,在提升速度的时候,又保持大容量,这将使得成本非常巨大;
对于方法2,这是个谬论;
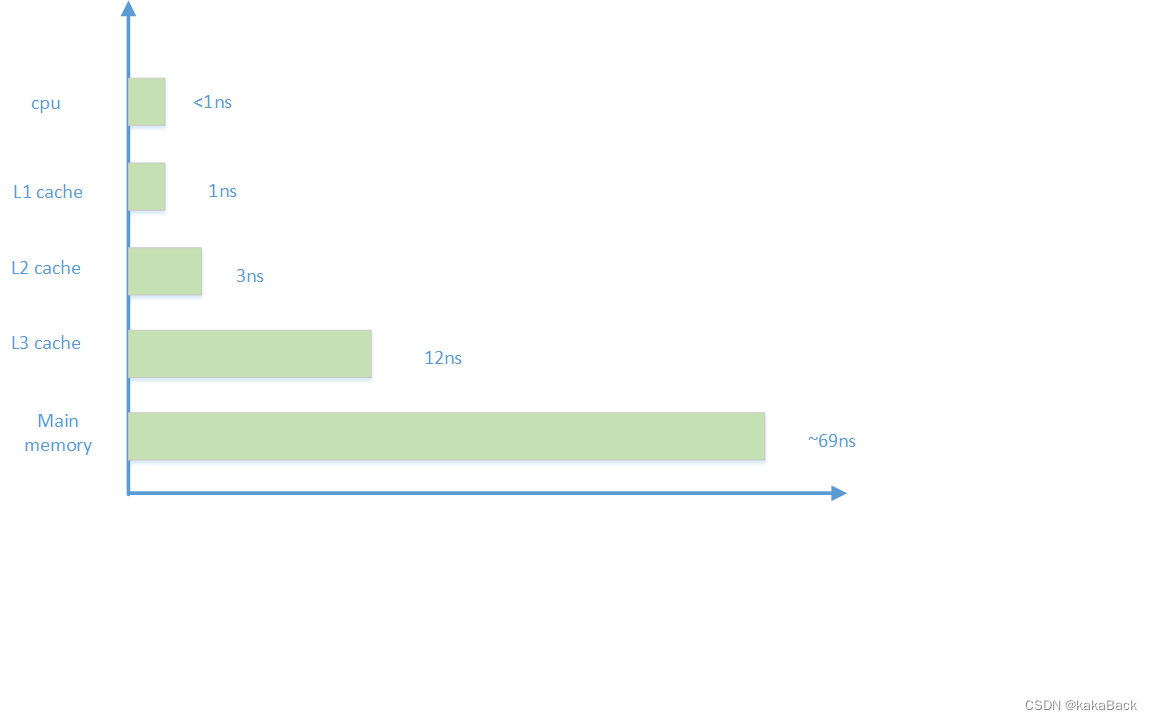
增加小而高速的缓存,当前 sram 的速度基本可以和 CPU 一致,容量小的情况下成本是可以接受的。采用 cache 方案之后的程序加载流程如下:

各级速度对比
Cache 架构
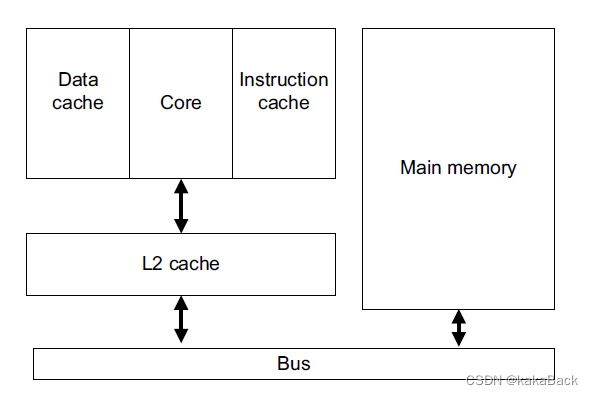
上图是典型的哈佛 cache 架构,描述了CPU,cache 和 memory 的位置关系。参考
《ARM cortex-A series programmer's guide》
Cache 映射方式
系统加入 cache 之后,如何将 main memory 和 cache 映射起来?
cache 的映射方式
直接映射
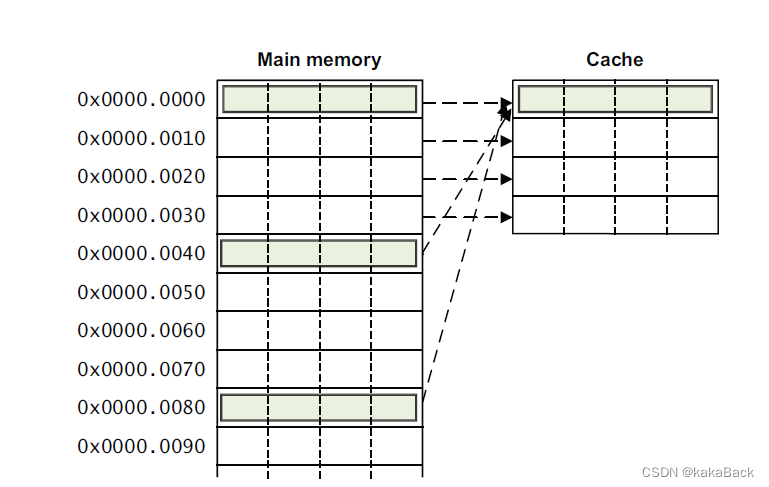
参考《ARM cortex-A series programmer's guide》
加入 cache line 大小是 8bytes, cache 大小是 64 bytes,那么总共会有8个 cacheline. 对每个 cache 做标示,则 index 是从0 到 7.
索引 cacheline 需要 3 bit,使用地址低 bit[2:0] 表示
每个cacheline 的 index 使用 bit[5:3] 表示
那么, 0x0000 0000 和 0x0000 0040 都指向了 cacheline 0 类似这种,地址和 cache line 是一一对应的。这种情况下,比如 先访问 0x00,cache 中内容不存在,需要重新加载,此时又访问了内存地址 0x40, 因为也是索引 cache line 0, 虽然cache hit, 此时内容是不同的,因此需要flush 之后重新加载。如果反复在 0x00 和 0x40 之间切换,实际上造成了cache 颠簸,cache 并没有提升性能。
全相联
每个内存对应的cache line的位置不固定,可以映射到不同cache line。这种情况下需要花费大量时间来查找可用的 cache,代价也十分大
组相联
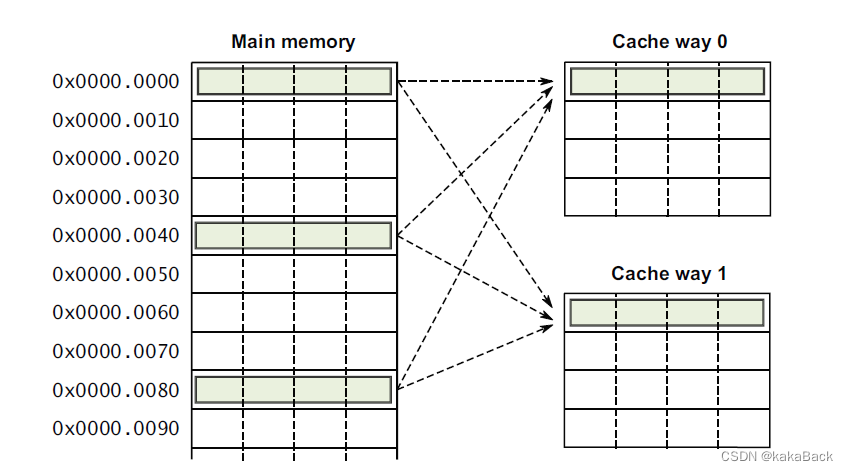
《ARM cortex-A series programmer's guide》
组相连是对直接映射和全相连的一个折衷,将cache划成几路(way)和组(Set)进行管理。
先看几个cache 术语
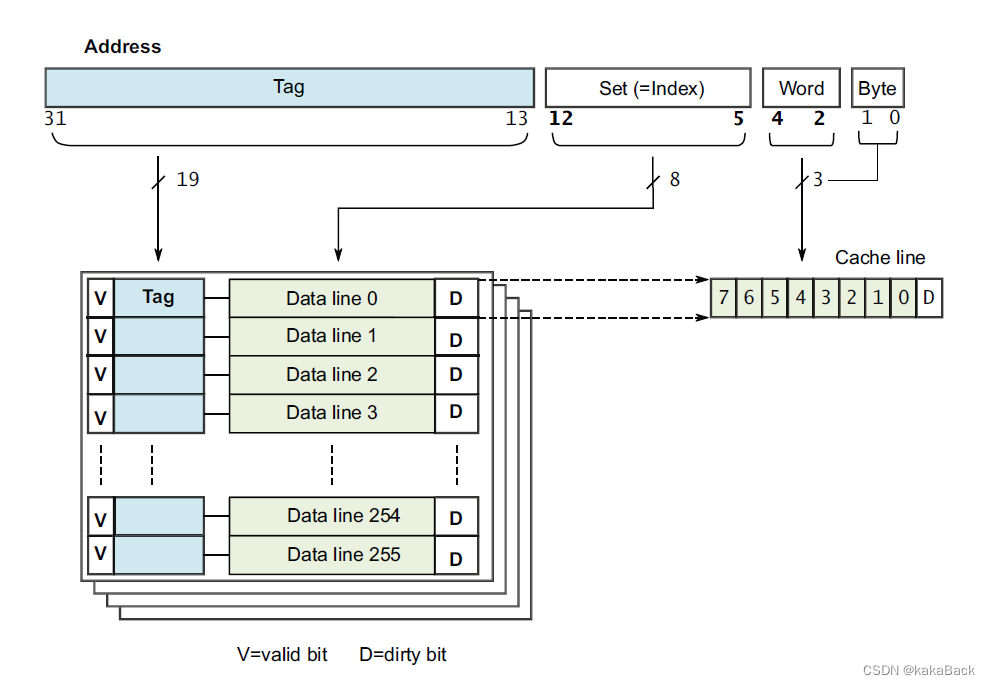
如上图,一个cache就是一个sram,
Way(路):为了方便管理,我们将sram cache分成了若干个way(通常是4个),
Set(组): 然后又将每个way分成若干个line;每个way中,都对line进行编号,有index=1,2,3..n(index=1表示cache line的编号即line1,index=2表示line2), 我们将在不同way中,index相同的叫成set。
Tag: 所有的cacheline 都是唯一的,每一个都有一个tag
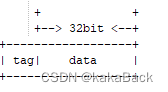
在cache管理中,最小的处理单元是cacheline即:
对于一个 大小为 16K, cacheline 是64bytes 的cache,假如
way: 4个,每个 way 大小是 4K
Set: 64个,需要 6bit 索引,使用对应地址的 bit[11:6] 来进行索引;
Offset: 用于索引 cacheline,总共需要 6bit,使用对应地址的 bit[5:0]索引;
假如某次操作检查cache 命中状态,会先根据bit[11:6]索引对应的Set,假设都是 cacheline N, 那么因为Way有4个,所以需要使用tag来比较落在哪个way中,如果tag 相同则认为命中,否则是miss。
这个时候引出了使用什么地址来索引 cache。
Cache 索引方式
歧义:同一个虚拟地址指向不同的物理地址
别名:不同虚拟地址指向同一个物理地址
VIVT
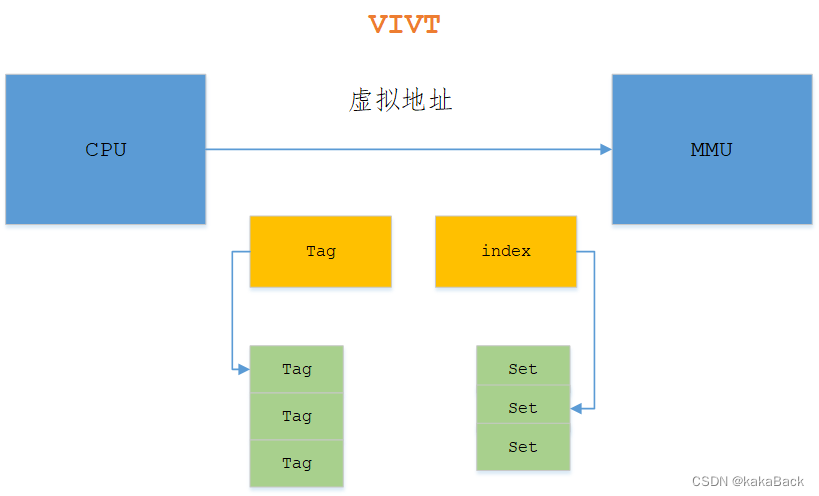
index 和 tag 都是使用虚拟地址查找,不需要经过MMU硬件,因此硬件成本是最低的。但是软件维护成本是个灾难,首先同一个地址指向的是不同物理地址,但是在cache 使用时,又使用相同cache,这会带来异常巨大维护。
PIPT
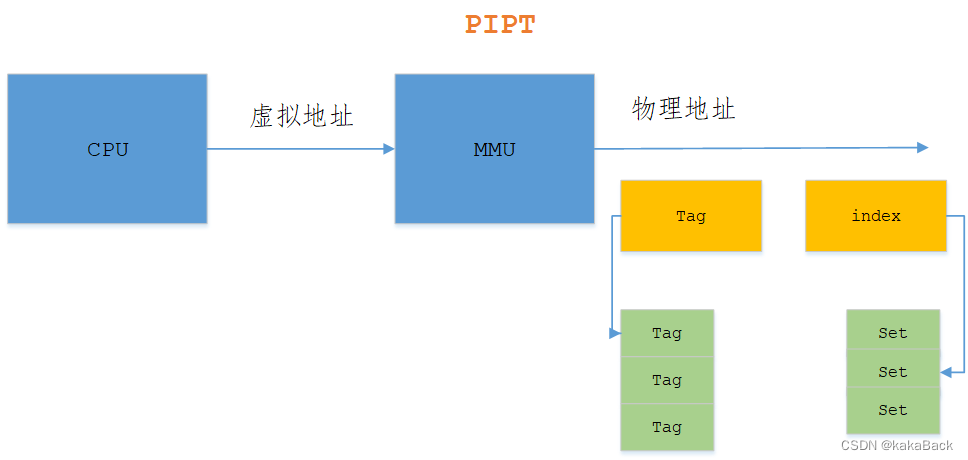
使用PIPT不会有别名问题,因为不同虚拟地址最终对应的都是同一个物理地址,这样cache的使用都是通过物理地址来比对的,不会有别名问题。
VIPT
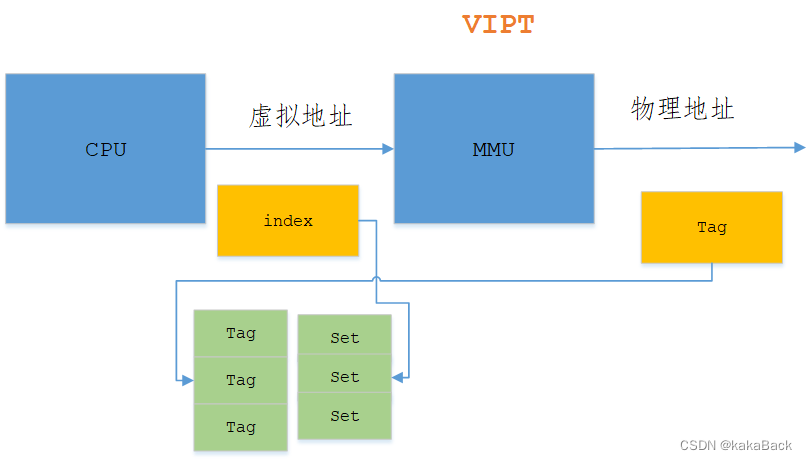
这里使用虚拟地址作为 index 索引 set, 物理地址作为tag, 那么这种情况有没有别名问题?
如果 VI=PI, 那么是没有别名问题的。
如果VI != PI ,是会有别名问题的。
假如一个 page 是 4K, 那么在MMU映射时,低 12bit物理地址是和虚拟地址相同的,那么如果一个 cachesize/way 小于等于page, 那么 VI=PI,否则 VI != PI的。
Cache Policy
写操作时,
- 若 cache hit, 有两种方式:
- write-back : 写入时写入 cache
- write-through: 写入时同时写入 cache 和 main memory.
- 若 cache misses, 则:
- write-allocate: 将data 写入 cache, 然后通过 flush 写入memory
- 非 write-allocate: 直接写入 memory
读操作:
- cache hit: 直接读取
- cache miss:
- read-through: 直接从 memory 中读取数据
- read-allocate: 先从memory 读取数据到cache, 然后从cache 读取数据。
cache coherency:
解决cache 一致性可以通过:
- 使用 non-cacheable 或者某些情况下使用 write-through 方式
- 将系统 cache 禁掉
- 多核上,硬件上 MESI 机制保证cache一致性
Cache 问题处理思路
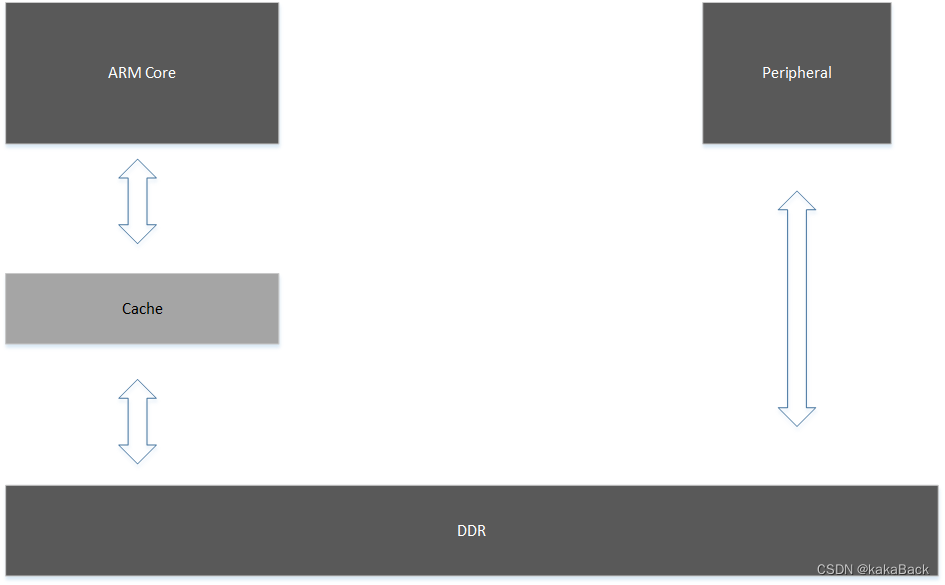
Cache 问题主要是基于上图的一个示意图来分析,常见的问题主要是 Cache 和 DDR 内容不一致导致的。
- ARM Core 向DDR 写入内容,在Cache 中命中,先写入 Cache, 然后导致Peripheral 读取的对应内容不一致,出现异常,ARM Core 写入之后需要 clean 相关cache
- Peripheral 向 DDR写入内容,ARM Core 读取对应DDR 地址在Cache中命中,出现 Cache中内容和 DDR内容不一致,此时需要peripheral 写入之后 invalidate.
注意: Cache 在 invalidate 时,如果对应 cacheline dirty, 是会先执行 clean之后再 invalidate.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









