







 超级会员免费看
超级会员免费看
TTS:音色个性化
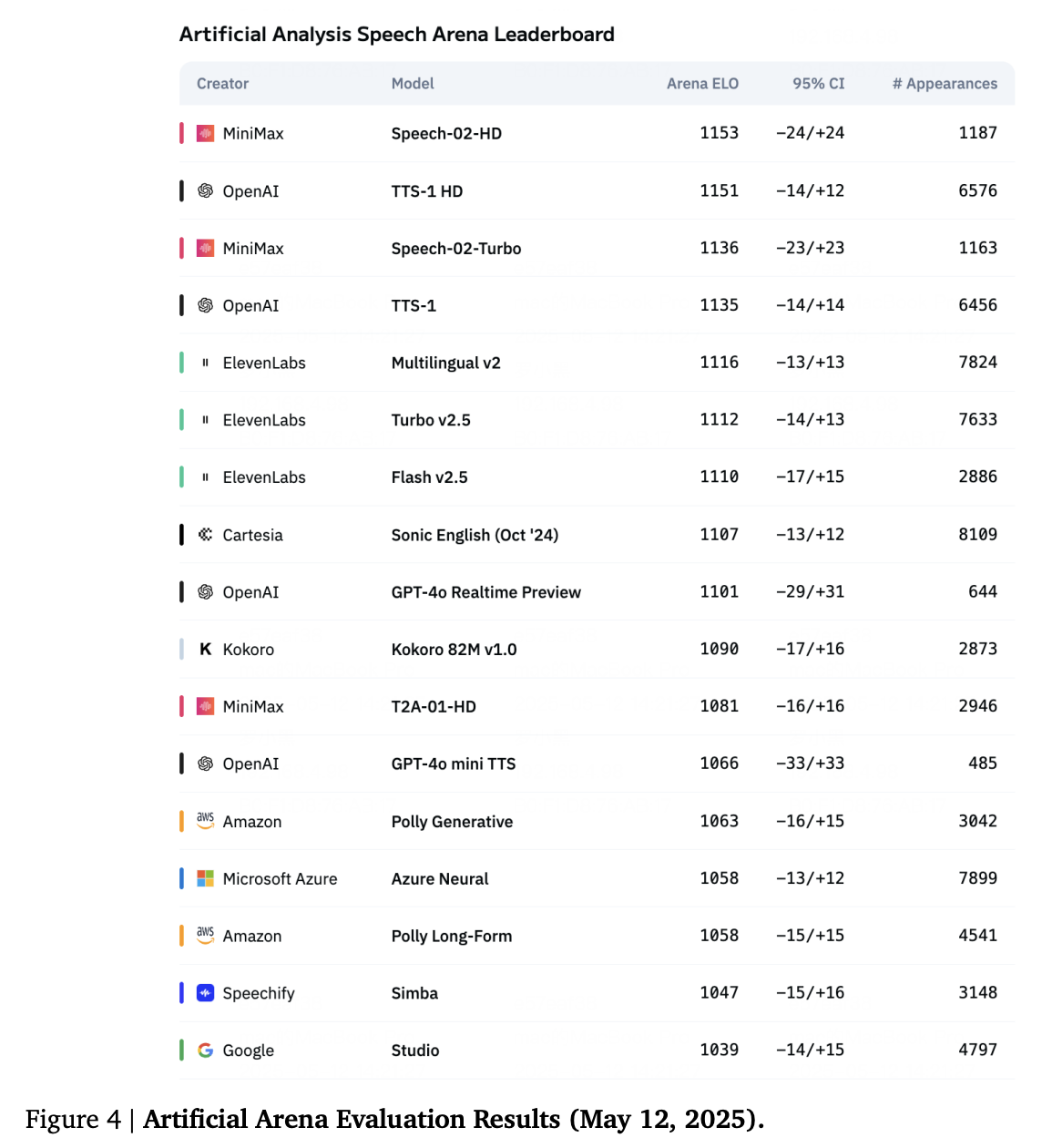
文本转语音(TTS)技术,作为人机交互的关键一环,近年来在深度学习的驱动下取得了长足的进步。我们不再满足于仅仅“听得清”,更追求“听得自然”、“听得悦耳”,甚至希望能让 AI 用“我喜欢的声音”说话。语音克隆 (Voice Cloning),特别是零样本 (Zero-Shot) 和小样本 (One-Shot) 语音克隆,成为了 TTS 领域的研究热点。
传统的 TTS 模型在进行语音克隆时,往往面临以下挑战:
- 依赖参考文本转录:许多模型需要提供目标说话人的语音片段及其对应的文本转录,才能进行声音克隆。这限制了其在只有音频素材时的应用。
- 韵律和风格迁移困难:简单地模仿音色容易,但要捕捉并迁移说话人独特的韵律、停顿、语调等风格特征,则非常困难。
- 跨语言能力不足:基于文本和语音对进行克隆的方法,在参考语音和目标合成语言不一致时,效果往往不佳。 <

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











