







convolutional neural network
卷积神经网络(CNN)小问答
Q:CNN和神经网络(RNN)不是完全独立的吧?
A:对,不是。
Q:CNN和RNN有什么不同啊?
A:RNN的结构如下图所示:
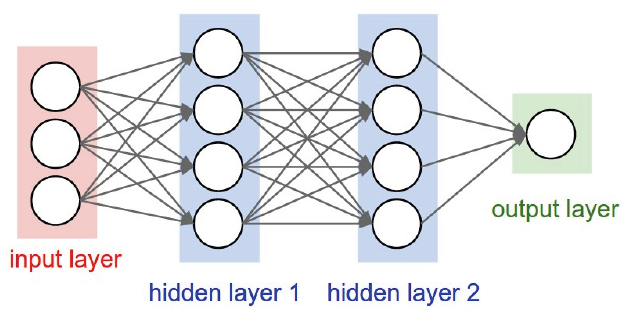
他们层与层之间没太多区别,而CNN就不一样了,如下图所示:

上图中词的意思:
CONV:卷积层;RELU:激励层(激活函数的一种);POOL:池化层;FC:全连接层
其中CONV和POOL是RNN中没有的。
Q:那什么是卷积层和池化层?
A:嗯..卷积层和池化层在之后会详细讲解,这里先说说为什么要有他们。
对于RNN:
首先深度学习的应用目前集中在图像识别,而即使是一张32(个像素)*32(个像素)*3(RGB三个通道)这么一张小图片,最后输入的数据都是32*32*3=3072维。
可见图像数据输入的维度会很高,而这样一来就不方便降维。
其次,输入的数据的有3072维,那输入层后面紧挨着的那一层也需要至少有3072个神经元啊(一个神经元对应一个像素),不过这样一来神经元的个数就会很多很多,而这就会有2个问题:
1,神经网络的层数上不去(一层就3072个了....)
2,学的太细了,有必要一个像素一个像素的学吗?
所以为了解决上面的问题就有了CONV和POOL。
好了,小问答到此为止,下面开始对CNN做细致讲解。
卷积层(CONV)
首先看这层的名字就知道这层不简单,而事实确实如此,卷积神经网络之所以叫这个名字,就和卷积层有着很大的关系。
既然卷积层如此重要,那我们就看看它到底干了些什么。
CONV的思想
现在已经知道,对RNN来说每个像素点是独立的,但真实情况并不是如此,因为某个像素点和其周围的像素点一定有关联,于是CNN就让卷积层的神经元从只关联一个像素点改成关联一小块像素点(如3行3列的一个正方形小块),如下图所示:
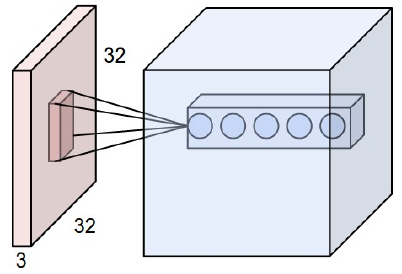
到此就是卷几层(CONV)中的每个神经元的工作内容的简要说明。
| 小知识 链接每个神经元的权重不一样,而这就代表着每个神经元关注的信息不一样 |
话说RNN是把所有的像素一行行逐个传给每个神经元,打个比方的话就是:拿一个只能看到长和宽都是1(个像素)的正方形的摄像机把第一行从左向右扫一遍后把第二行从左向右扫一遍,就这样直到扫完最后一行。
CONV中的步长、填充值和深度
而CNN中的卷几层本质上与其没什么不同,只不过这个摄像机一次能看到的是长和宽为n(个像素)的正方形,当然了,也因此CNN中多定义了这些东西:
1,步长(stride):CONV在扫描第k+1块时是把“摄像机看到的正方形向右移动“步长”个像素(假设这一行还没扫描完)”,如:
第k=1次扫描时扫描的正方形是下图所示

假设步长为2,那k+1次扫描时就是向右移动2个像素,如下图所示:
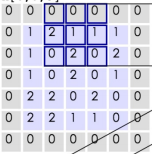
2,填充值(zero-padding):上图最外面的那一圈0就是填充值。嗯..这个我的说两句:
其实真正的样本数据是下图这一块:
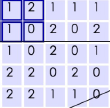
这时若直接把数据拿来扫描(摄像机是2*2的正方形)且步长为2时会发现无法把一行扫描完,为了解决这个问题就在外面添加一圈0,而添加的这一圈就是填充值,当然填充的圈数可以不止一圈。
3,深度(depth):下一层有多少个神经元。
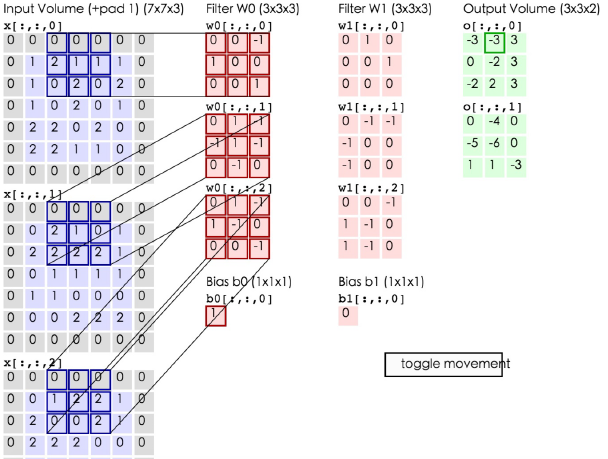
CONV的执行过程

如上图所示:
最左边的三个蓝色的是一幅图片的R\G\B三个颜色通道的样本数据;
中间6个红色的是两个神经元(一列是一个神经元),因此深度(depth)=2;
PS1:因为一个神经元要处理三个颜色通道,所以一个神经元有3个矩阵矩阵中的值是权重。
PS2:b0和b1是偏移项,即:wx+b中的b。
最右边绿色的是两个神经元的输出值。
我们每次取3*3的窗口。
这里令步长(stride)=2。
于是这里就是令图中连线的矩阵相乘得到输出-3。
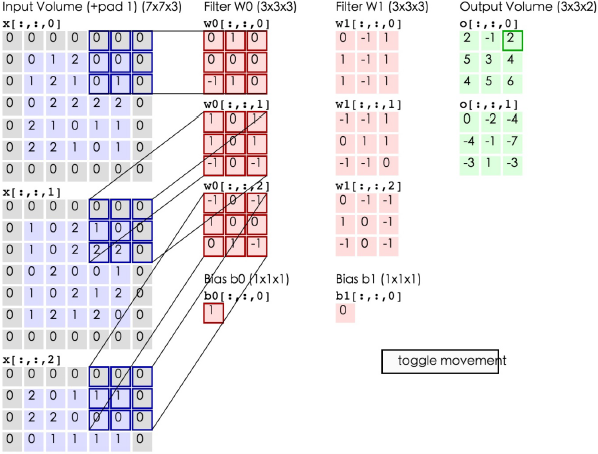
同理,下一次的情况如下图所示:
在下一次
在下一次
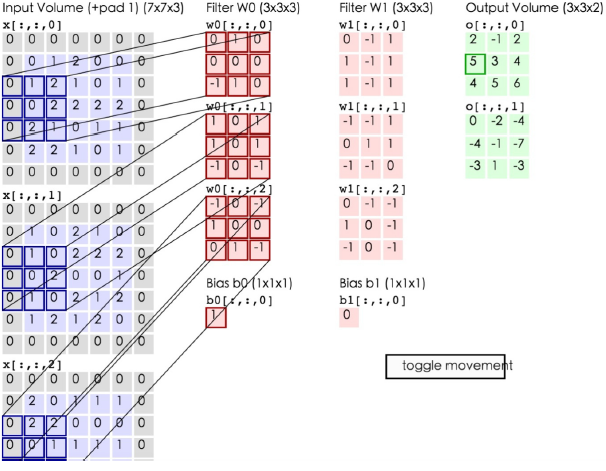
CONV的最后说明
有没有注意到这里对于所有的“方框”都是使用同样的权重,而这就降低了权重的数量。
激励层(ReLU)
还记得这个图吗

CONV后面是ReLU,那这里就按顺序说明,当然了,这里的激励层和RNN中的一样,如下图:
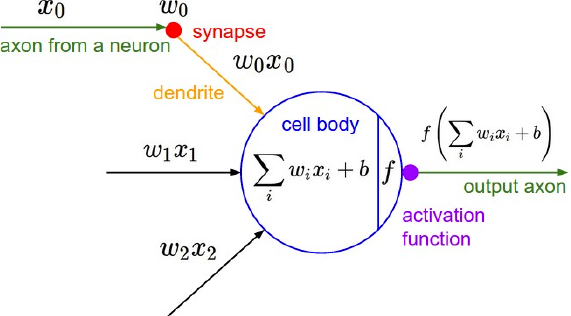
激励层用到的激活函数见我总结的《神经网络的传递函数(激活函数)》
池化层(POOL)
它经常夹在连续的卷积层和激励层之间。
它干的活只有一个:进一步压缩数据和参数的量,减少过拟合。
那它是怎么压缩数据的呢?请看下面这张图:
对这张图,我任取一个像素点都可以用它代表周围的一小块吧,OK,池化层就是这么做的,当然了它的做法有个名字:下采样(downsampling),如下图所示:
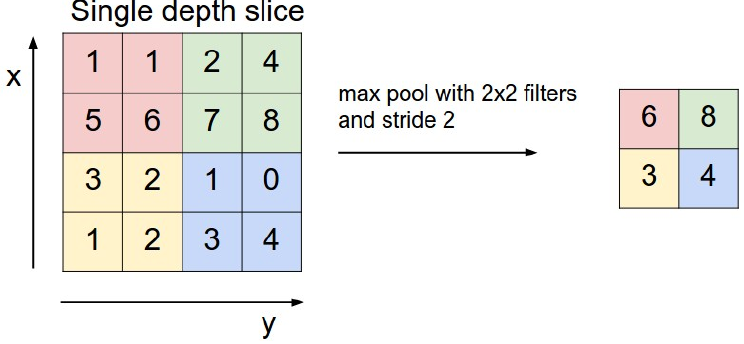
左边是原始数据,右边是压缩后的数据。对于原始4*4的数据,POOL将其压缩成2*2的窗口,而方法就是如图所示的4个颜色用1个表示,表示方法有两种:
1,用该区域的最大值表示该区域。
上图就是这么做的:红色块中最大值是6,于是用6代表红色;其他同理。
2,用该区域的平均值表示该区域。
全连接层(FC)
放在CNN尾部,该层的神经元和上一层之间所有神经元都有权重链接。















 6755
6755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









