






在第二次上海大数据流处理聚会上,来自 Intel,大众点评与 Cloudera 的大数据工程师与大家分享时下大数据流处理最火热的话题。
张天伦:Storm over Gearpump

演讲开始前,张天伦通过介绍自己的工作表达了对streaming的兴趣,并向大家推荐自己搜集在GitHub上的projects,希望有更多有兴趣的人一起交流。
Gearpump - Distributed Real-time Streaming Engine
Storm over Gearpump,即在Gearpump上提供一个Storm的透明的兼容层,用户可以不改一行代码,不用重新定义它的jar包,就可以把Storm 运行到Gearpump上。Storm 是业界使用最广泛的流处理引擎,但也暴露出了不少局限性。这些局限性在 Intel 最新开源的流处理系统 Gearpump 中都得到了良好的解决。为了让广大 Storm 用户零成本地体验到 Gearpump 的优良特性,Gearpump 实现了对 Storm 的透明兼容,即用户无需修改代码,重新编译,就可以直接将二进制包运行在 Gearpump 上。
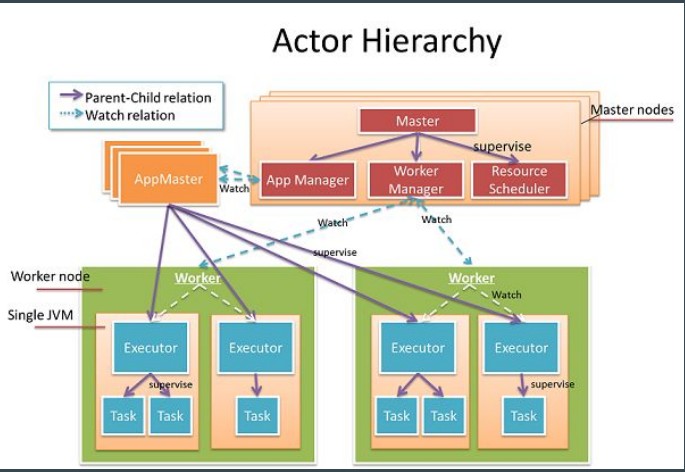
Gearpump 基于 Akka 和 Actor 模型构建了一个高可靠高性能的实时流处理系统,图1为Gearpump的一个cluster,它有一个master和多个worker,每个worker会管理各个集群上各个节点的资源。层级化的好处是系统一部分出问题时不会影响到其它部分,在Gearpump里,一个master可以管理多个worker,多个应用之间是相互隔离的,每个应用会有一个对应的appmaster,每个appmaster向master申请资源后可以在worker上部署executer,相当于一个JVM,具体的执行单元是Task,一个Task就是一个Actor。Gearpump的Dynamic DAG是可以在线修改的,而且计算快,延时低。
Gearpump Updates
为什么要做Gearpump在Storm上的兼容性呢?
Storm是最为广泛的流处理系统,在使用过程中也发现了它的一些局限性,Gearpump的设计之初就是为了克服Storm的局限性,同时希望广大的Storm用户可以无代价的享受到Gearpump这些优良的特性,所以要实现在Gearpump上能够透明的支持Storm的应用。
Storm over Gearpump – Features
Gearpump现在支持0.9版本的Storm,支持multi-lang,就是Storm支持一些Python/Ruby/Node的脚本,支持Storm里DRPC的功能,也支持KafkaSpout / KafkaBolt,Trident这部分的工作目前还在进行当中。
Similarities of Gearpump and Storm
首先Gearpump和Storm都是对单条数据单个消息进行处理,其次它们的用户接口都是相似的,Storm是通过Topolgy,Gearpump是通过DAG。另外Task接口也是相似的。
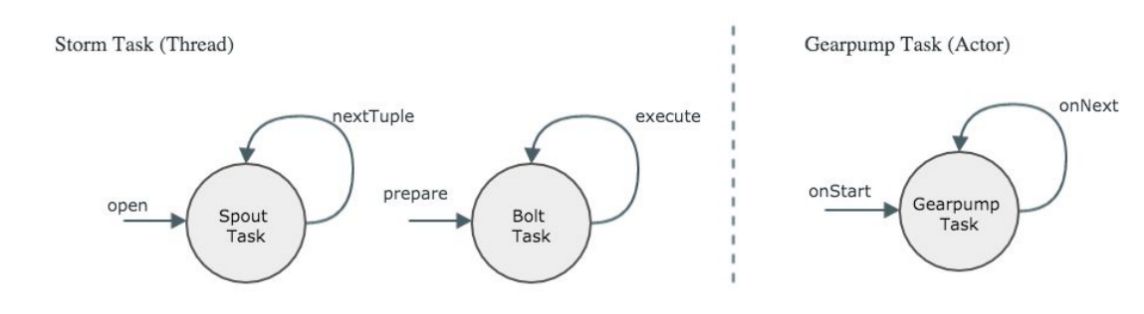
图3左边为Storm的Task接口,Storm里面有两种角色,Spout和Bolt,对于Spout的生命周期会有一个初始的Open方式,然后不停的循环调用nextTouple向下游发消息,对于Bolt来说开始会有一个prepare阶段,每收到一个消息它会调用execute。右边是Gearpump的Task接口,一开始会有一个onStart阶段,每收到一条消息会调用onNext。这两者是非常相似的,但是Strom的Task会占用到一个线程,Gearpump的Task是一个Actor,是比线程更小的一个执行单元。
Storm over Gearpump – Overview
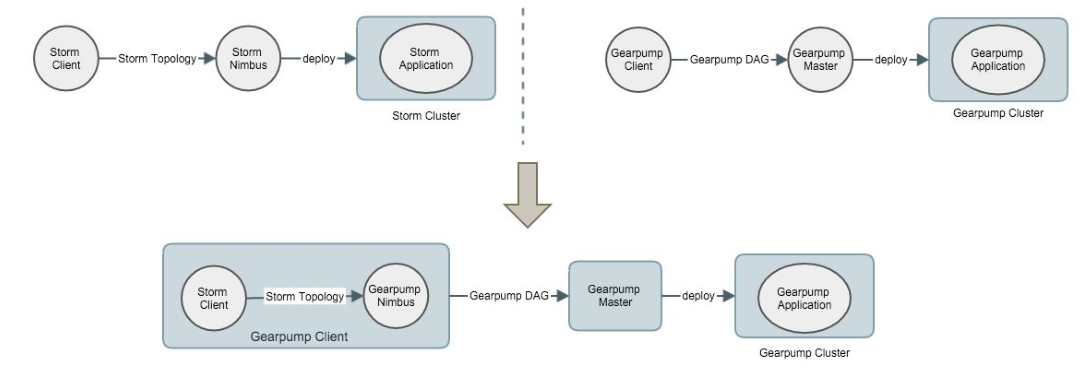
图4上半部分左右两边的实现过程很相似。Storm Nimbus与Client是通过协议进行交互的,我们可以灵活的在Gearpump里实现Nimbus来遵守Storm的协议,具体做法是在StormClient提交请求时在本地起一个Gearpump的Nimbus,在Gearpump的Nimbus里把Storm Topology翻译成Gearpump DAG,再把Gearpump DAG提交给Gearpump master,这样,一个Storm应用就可以运行在Gearpump cluster上面了。
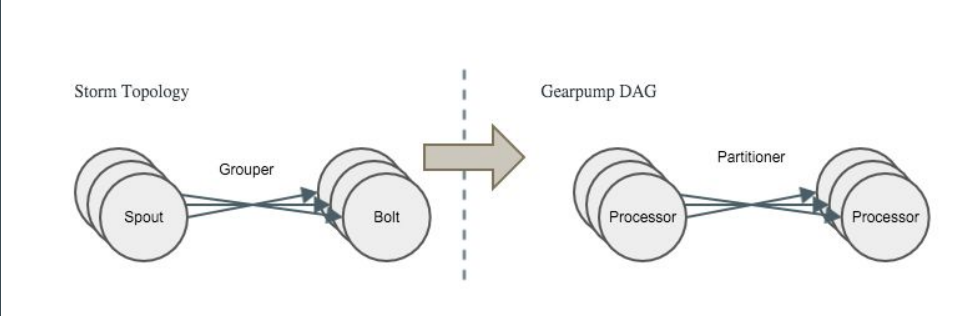
图5中,Spout翻译成Gearpump的逻辑节点Processor,所有的Grouper牵引到Gearpump里的partitioner,整个图实现是一一对应的。
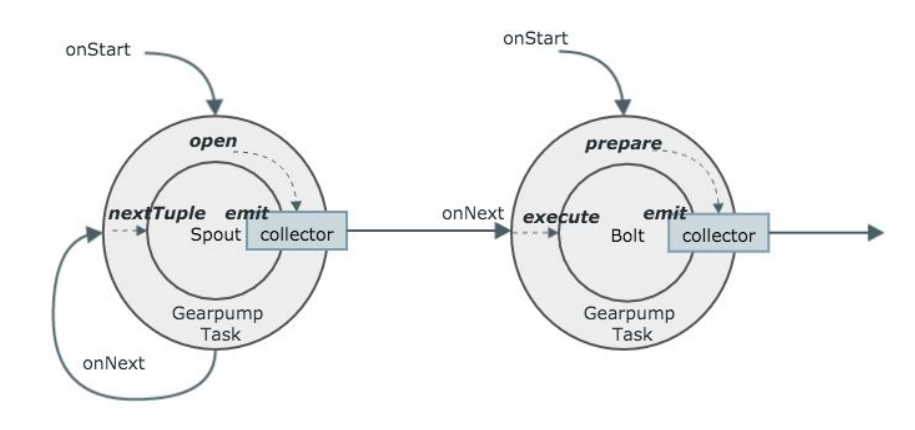
图6中在Gearpump里运行Storm的Spout和Bolt,并且把二者的生命周期结合在一起。传输Spout需要Gearpump的传输层,所以每次调用onStart时,会把Gearpump的collector注册到Spout里,通过这条通道会把Storm的消息传到Gearpump里面。
Storm over Gearpump - Flow Control
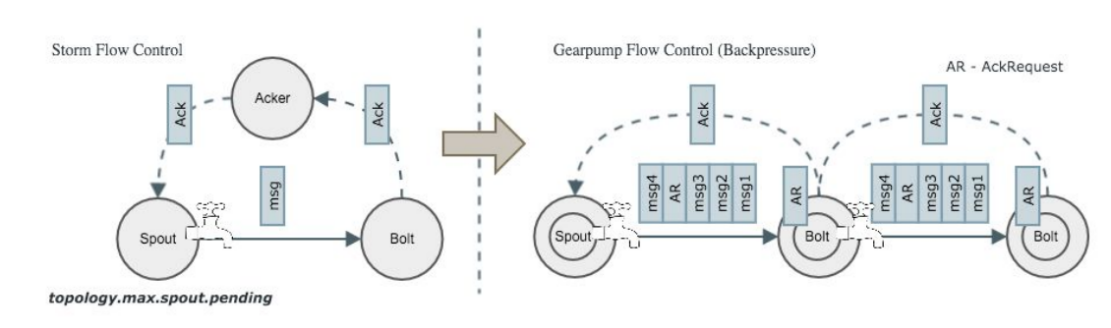
Storm是通过Acker实现流控制,当有一定数量的消息没有被Ack后,Storm在Spout端就不会向下游发消息了,在Gearpump里面,每隔一定的消息数量上游Task会向下游Task发一个AckRequest,下游收到AckRequest后会给上游回一个Ack,这时在一个Task里我们维护了一个滑动窗的概念,通过这样一种机制,下游的压力会一层层的向上游传播,直到传到Spout这一层,Spout会停止或者减慢向下游发消息。
Storm over Gearpump - At Least Once
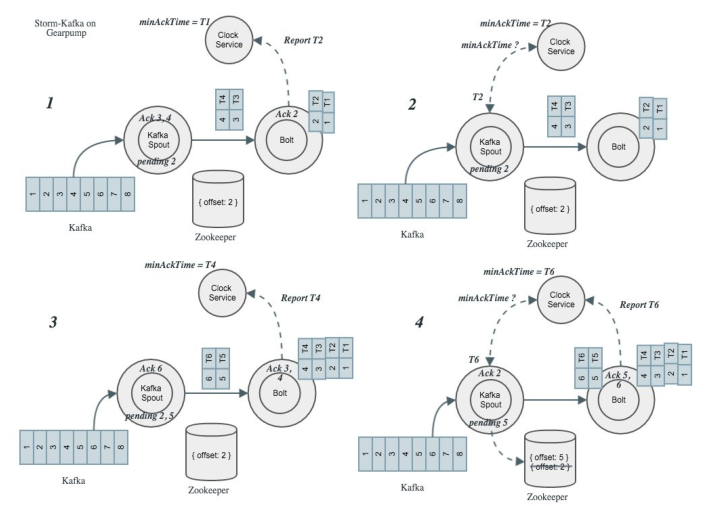
Stormm会把Kafka的Offset存到Zookeeper里,如果出错后,它可以重新从Zookeeper里了解到消息发到哪里了,在Gearpump里也支持Kafka的At least once的语意,但是和Strom做法不一样,图8中,2中开始发消息时是处于pending的位置,3、4发消息时直接Ack,由于2中没有Ack,此时Storm的Kafka里Offset没有更新,即使出问题时依然回来从2开始,这是为了避免Storm的Spout中累积大量消息。所有消息在Gearpump上都会打上系统的时间印记,当下游的Task收到消息后会汇报给Clock Service,Clock Service会维护全局的最小的Ack时间。
性能
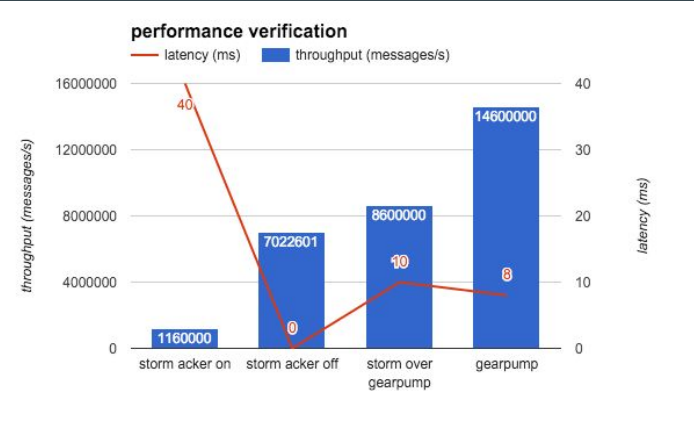
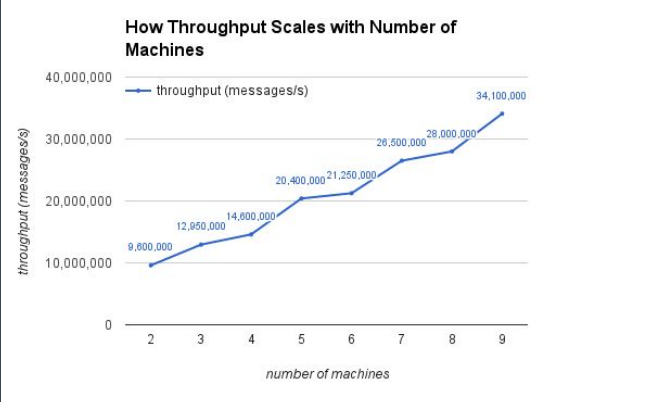
实现这样的兼容层的性能怎么样呢?我们在四个节点上做了测试,用的是 storm-benchmark 中的 SOL,这个例子没有任何用户逻辑,纯粹测试的是系统框架本身的性能,有48个Spouts和Bolts,16个workers。图9中可以看出Gearpump的性能良好。
下一步工作
增加在界面上直接提交Storm Job,增加Storm 0.10的支持,增加At least once对更多Spouts的支持,增加Trident的支持。
王新春: Storm 计算平台在大众点评的实践

点评的实时应用场景
流量、交易相关的 Dashboard。包括UV(每天独立用户访问数)相关的各个平台:主APP(Android/iPhone/iPad)、团APP、周边快查、PC、M站;新激活用户数;分层次分品类的实时交易额。
个性化搜索与推荐。用户在点评的每一步有价值的操作(包括:搜索、点击、浏览、购买、收藏等),都将实时、智能的影响搜索排序,从而显著提升用户搜索体验、搜索转化率。
广告的点击率,广告的反作弊、实时计费,及反爬虫反作弊的业务安全。
点评的实时平台
基本架构
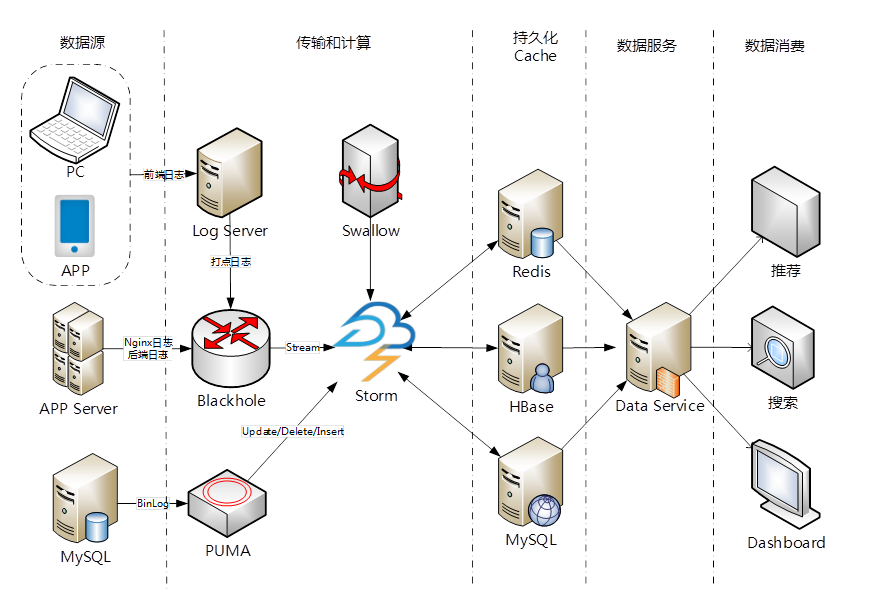
点评的实时平台架构主要分几块,首先是数据源,数据的输入包括PC和APP上打点的数据,打点数据是指用户的浏览数据,Blackhole主要是支持日志类的,PUMA主要是获取MySQL线上数据库的,Swallow主要是MQ系统。那么在Storm上能拿到哪些数据呢?几乎所有点评线上产生的数据都可以秒级内拿到,封装对应的数据输入源Spout;通过Blackhole支持日志类实时获取,打点日志/业务Log/Nginx日志等;整合Puma Client(MySQL Binlog):第一时间获取数据库数据变更;整合Swallow(MQ):获取应用消息整合Pigeon(RPC 框架):支持调用第三方业务。其他业务如何获取Storm计算的数据输出呢?实时计算和第三方业务解耦:通过data-service服务,数据可以输出Redis/HBase/MySQL等存储中;同样,第三方业务通过data-service服务,获取Storm计算的持久化数据。
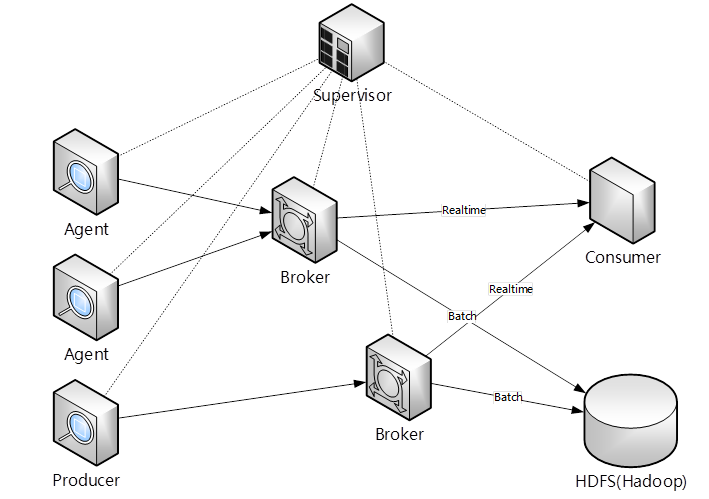
每台线上的应用服务器都是有Agent部署的,与Kafka不太一样的是Supervisor做所有信息的控制,传输数据时通过Broker,在Blackhole上一是做实时数据消费,二是拉取到线上很多应用日志直接放到HDFS里。
集群监控
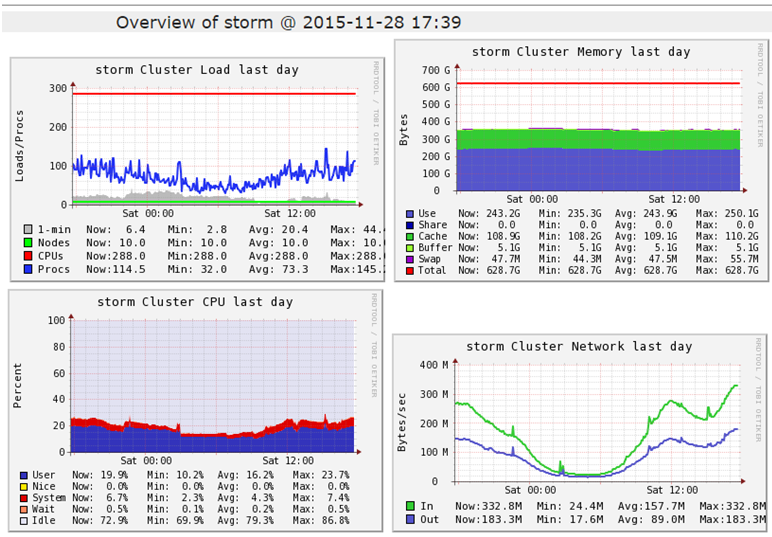
用ganglia搜集一些主机层次的数据,也就是集群的基本的状态,包括Load、内存、cpu、网络的总体情况,这样在排查问题时就可以看到主机层次的基本信息有没有异常。
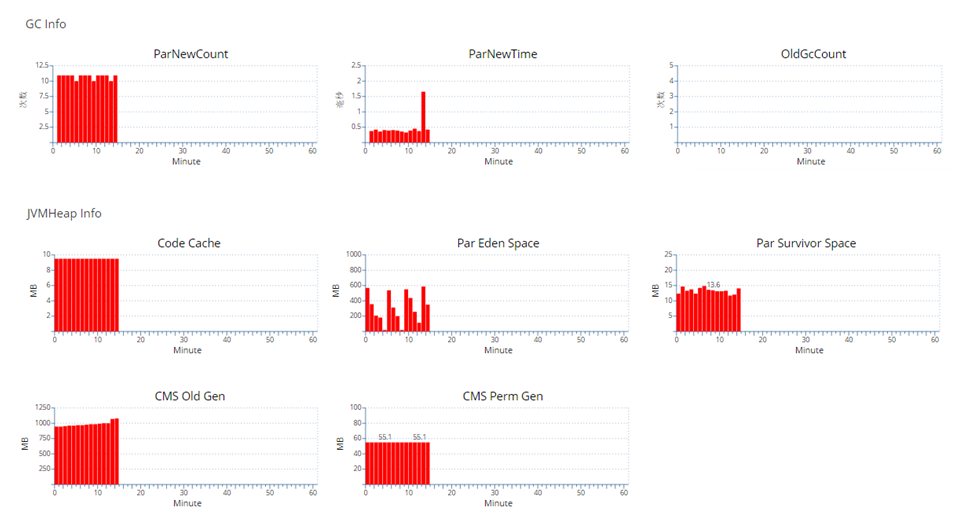
具体到一个worker时,是把统一的信息打到点评内部的监控系统CAT里面,很多应用类的监控也会依赖CAT。
业务监控
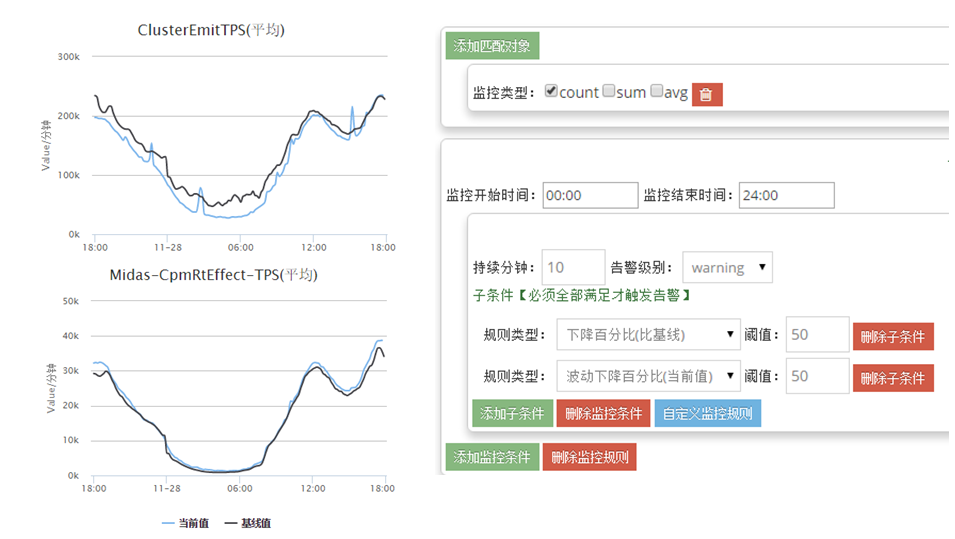
把所有的Topology通过Nimbus API和Metric API把数据抓出来,输出到点评的CAT里面。可以对每张图配报警值,它的当前值和极限值,变化率,连续几分钟的跌落多少,最小值最大值,这些可以配相应的报警规则,出问题时就会收到报警,像微信、邮件、短信等。
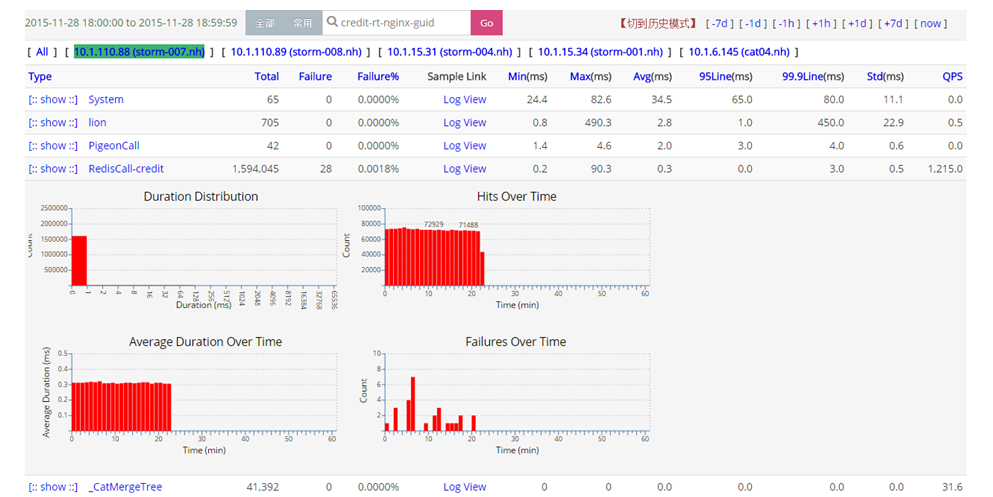
我们可以把自己关心的业务数据打到CAT里面去看,Spout里Blackhole消费的Topic数据,失败数量,TPS等,这样也可以设置一些报警规则。
点评使用 Storm 以来的经验教训与解决方案
1、某个Worker吃掉了几乎所有的CPU,其他Topology也遭殃:Topology一共就2个Worker并且Bolt里面自己启动了200个线程,解析json。
解决方案:CGroup限制单个Worker的资源。
2、Storm无权限管理,收到一堆报警,Owner不知道是谁。
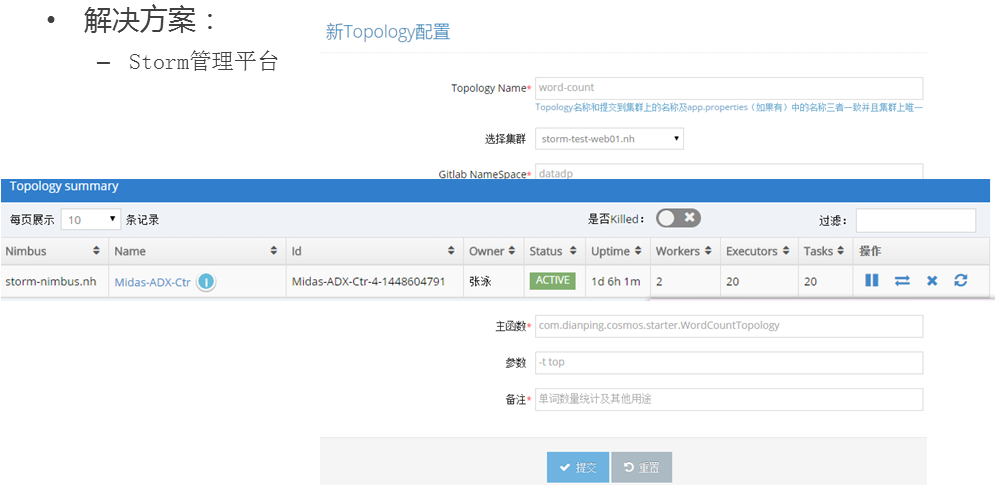
3、Topology提交到Storm,却启动不起来:Cause:free slot < worker num。
解决方案:
import backtype.storm.nimbus.ITopologyValidator;
public class DPTopologyValidator implements ITopologyValidator {
//Topology Name合法性
//Worker、Executor数量合理性
//free slot数量必须大于单Supervisor节点数量,保证集群整体可靠性
}4、Zookeeper磁盘被刷爆了:Casue:Storm集群上的Topology Task大量心跳信息,zk产生的日志> 20G/H。
解决方案:
减少Zookeeper日志保存的数量;
控制单集群规模;
task.heartbeat.frequency.secs 默认3s,适当增大。
5、Namenode被Topology DDoS了
Cause:
Hadoop集群开启了Security;
流量日志依赖storm-hdfs写HDFS,业务重构逻辑,write失败后反复重试,Namenode ;RPC 超过8000QPS、负载过高,所有离线Job都受到影响。
解决方案:
提供统一的写HDFS的服务,只需要把需要写入的数据发送给blackhole。
6、流量上来,Worker OOM了
Cause:Storm目前无backpress机制(JStorm 2.1.0新增)
解决方案:
开启ACK;
设置topology.max.spout.pending。
无不引起了小伙伴们的极大共鸣,这真是 “那些年,我们一起踩过的 Storm 坑啊“。
此外,他还分享了一些 Storm Topology 优化的小技巧,可谓是干货十足。
后续规划
Worker日志统一收集和展现(doing):现有log查看比较不方便,Topology、Worker、Package、Class、Level等多维度统一展现。
管理平台集成更多监控数据:支持细粒度的tracking,Storm/JStorm同时支持。
Storm on Docker ?:增强隔离性,Topology环境可以独立开。
程浩:StreamingSQL on Spark
Intel 大数据工程师程浩

演讲前,程浩简要介绍了他们团队是 Spark开源社区的活跃开发者,他带来的是 Intel 开源项目 StreamingSQL 的第一手资料。
为什么需要StreamingSQL?
从用户使用的层面上讲,如何为用户提供一个非常简易操作的一套封装,让大家更好的去操作Streaming,简化我们的操作。StreamingSQL 的出现使得开发者可以通过 SQL 无缝集成流处理和批处理两种运算,大大降低了开发和维护成本。程浩从 Spark Streaming 和 Spark SQL 的基本原理讲起,SparkStreaming就是把指定的时间片段内的批量的数据组织成一个迷你的Batches,然后封装成一个RDD,可以对RDD进行各种转换操作,最后把小的数据提交给Spark执行引擎去执行,它是一个不断的向前的迭代的过程。
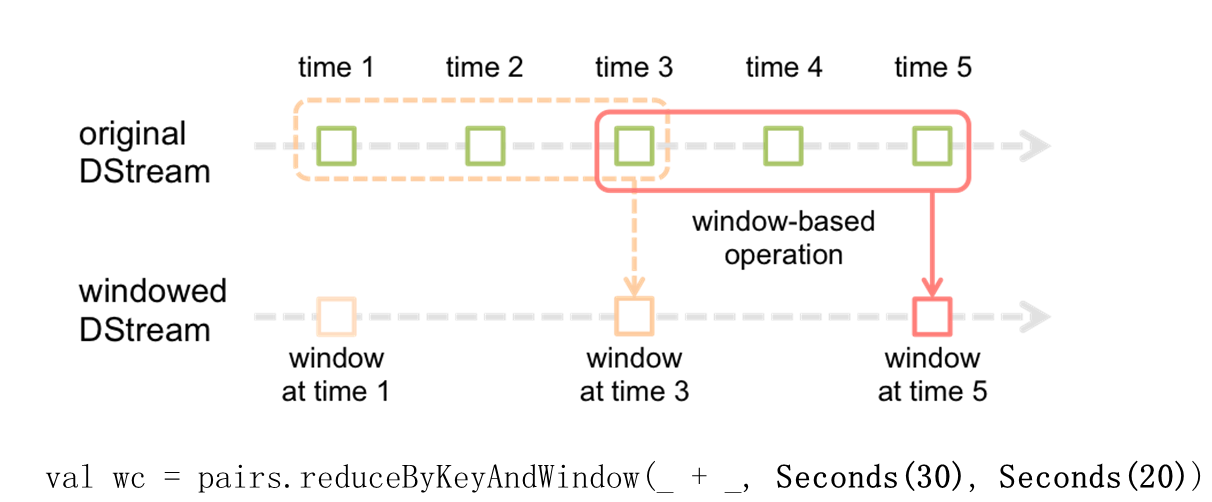
每搜集一个单位时间内的数据代表一个小格子,我们可以有若干个单位时间组成一个window,我们希望对window内的数据进行操作,由于是流式处理,整个window可以不停的向前移,图1中定义一个window长度30S,每隔20S要执行一次相关的操作。
StreamingSQL 的设计思想
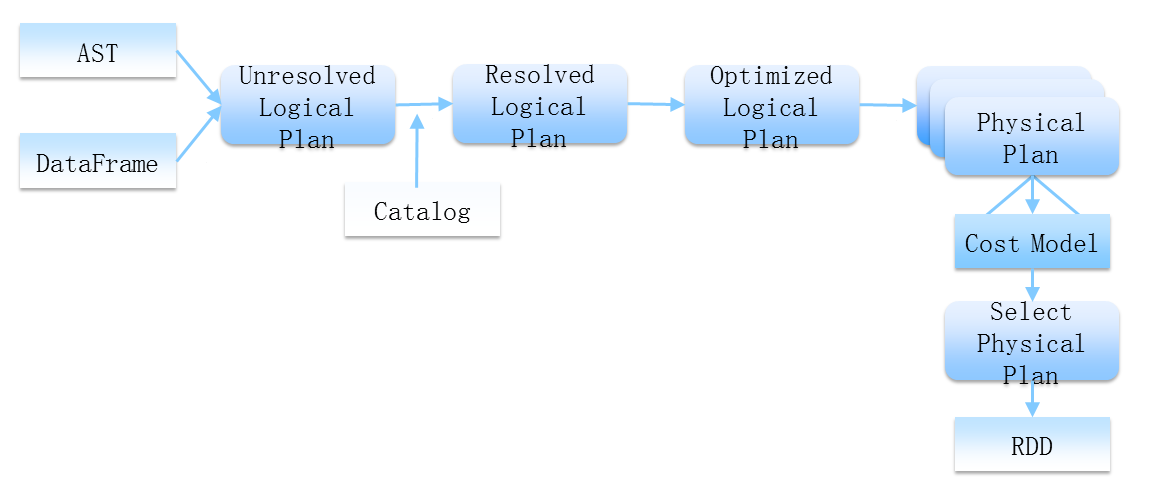
图2表现出两个意思。第一,AST和DataFrame作为前端的输入,只需告诉它我们要干什么,至于怎么去做是引擎自己的事情,比如说进行语意分析,对其进行优化,用一个代价最低的方式帮我们去完成。第二,Spark SQL最后的执行是交给Spark集群来做的,整个的执行引擎最后的输出是RDD。
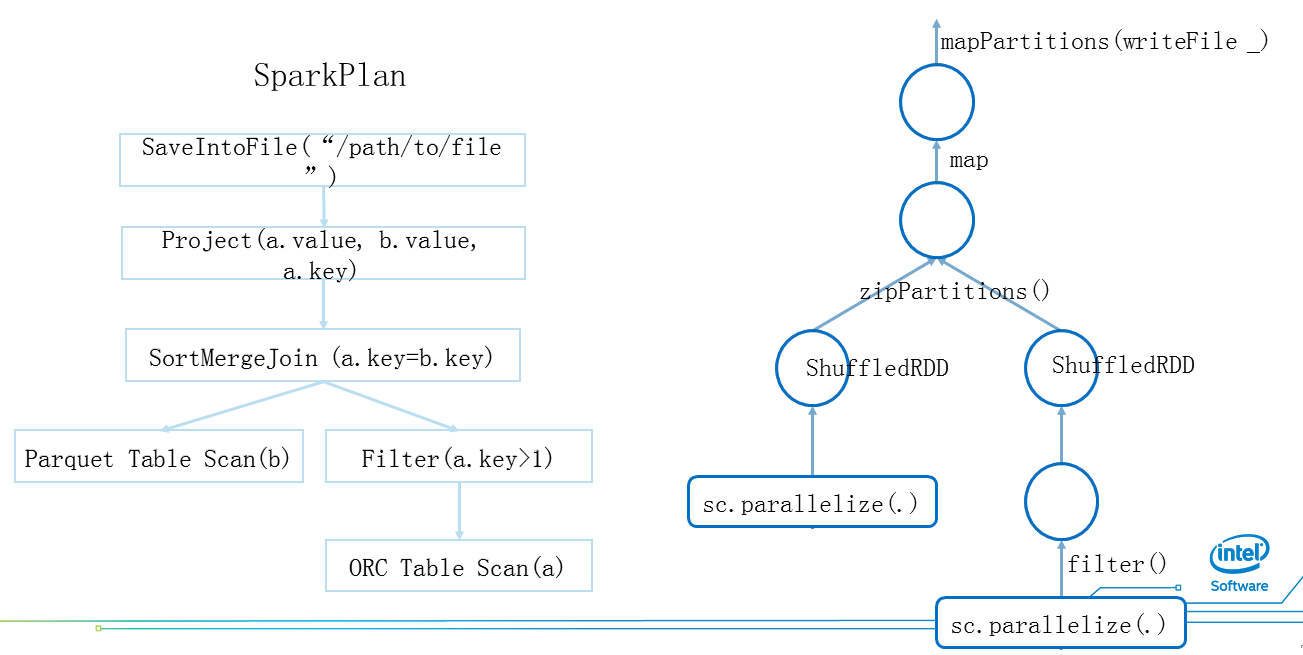
图3为Spark的一个物理计划,左侧树状图把它理解为两个表,右边为ORC,左边为Parquet,对ORC进行过滤后两个表的数据进行Join,然后进行投影,再把数据写回文件。对应图左的Sparkplan的RDD如图右侧,它有一个非常简单的对应关系。
怎样实现Spark Streaming SQL?
如何承用Spark SQL和Steraming SQL的组建,即如何使用现有的代码以及如何继承现有的功能?

图4中第一个为WindowedPhysicalPlan,它是SparkPlan的一个子类,但windowDuration和slideDuration是用来描述Window的,这就把Spark和Streaming的概念结合起来了,execute的方法最后要返回一个RDD,在整个的Planning Stage,如果想把SQL当中的概念和流的概念结合起来,就是通过WindowPhysicalPlan这个操作算子连接起来的。Spark Streaming要操作的是DStream,第二个SchemaDStream封装了一个streamSQLContext,compute的方法最后也要返回一个RDD。
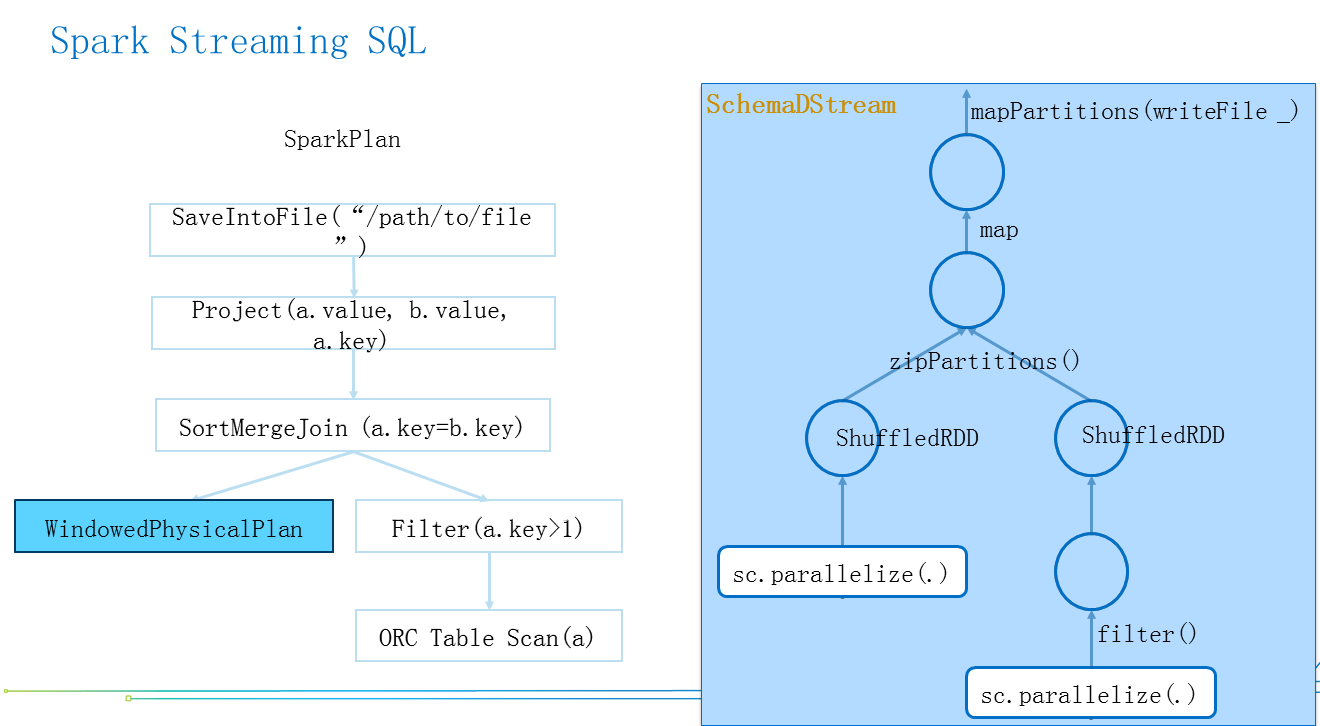
假设图5中左边的表的Parquet替换成Streaming的Datasource,简单把物理计划的节点换成WindowPhysicalPlan后,会生成一个RDD,帮助我们把Streaming和SQL结合起来,然后把右边生成的RDD的DAG包装成SchemaDStream,封装起来,于是我们既可以通过左边的方式达到SQL的转换变成一个RDD,通过右边的方式把拿到的RDD变成DStream提交给Spark Streaming去工作,这就完成了Spark Streaming SQL的过程。
如何去创造一个基于流式的Datasource?
Spark Streaming SQL完全走的是Spark SQL标准的Datasource的接口去实现,只不过要特别建立一个kafka的datasource。
如何在SQL中定义Window?
我们对SQL做了一点点扩展,就是over,关于时间序列的定义。去掉over后与SQL一模一样。

两者对比发现,Spark Streaming的可读性较差,而Streaming SQL一目了然。
更多好处
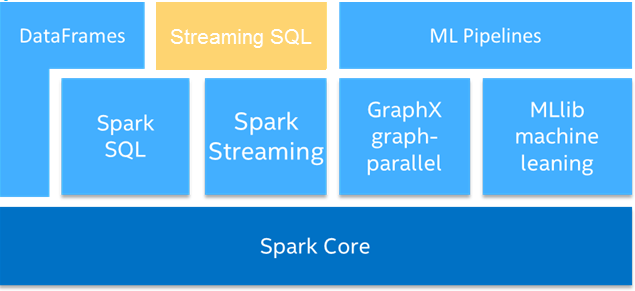
图7中底层Spark Core,上面的DataFrames旁边插入Streaming SQL,它是基于Spark SQL和Spark Streaming来完成这样的组建,完全兼容Spark SQL,如果SQL或Streaming有什么改进时,会自动获得这些好处,不需要做额外的修改,而且流式数据可以和静态表进行交互操作,代码简单。
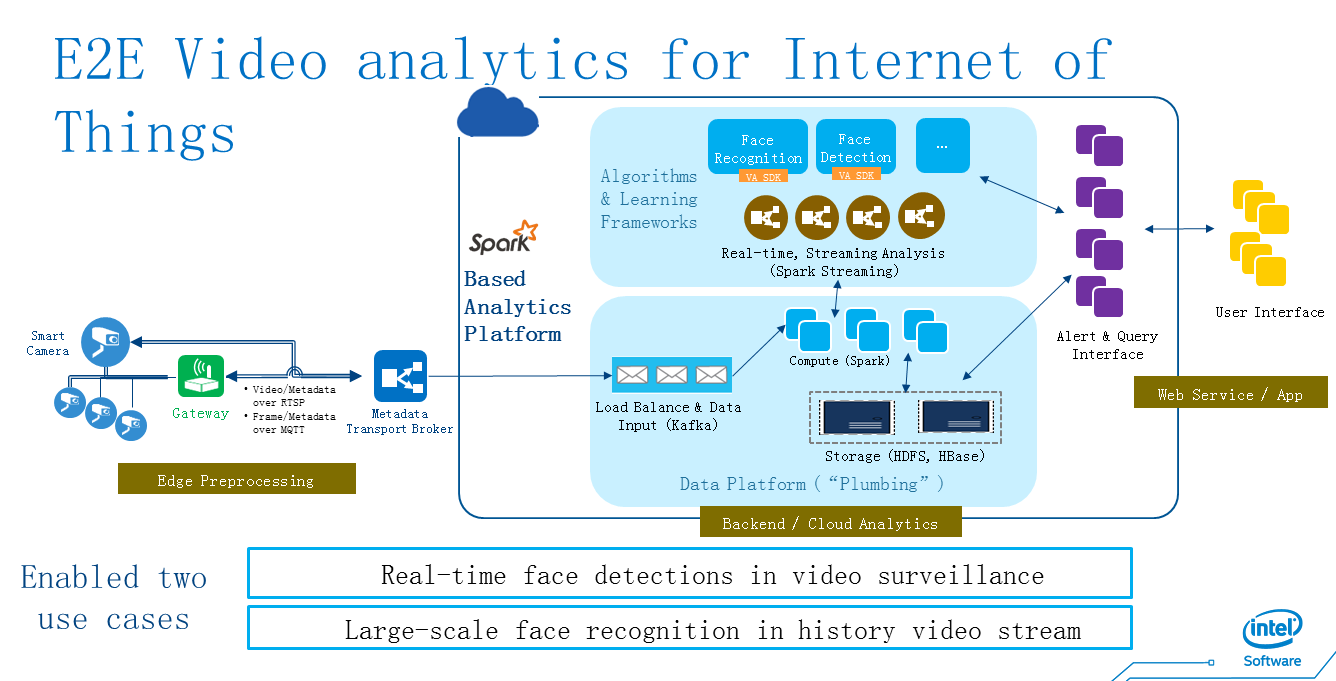
最后分享了使用 StreamingSQL 从摄像头数据中实时分析和预处理,与历史数据和犯罪嫌疑人数据进行匹配,抓捕嫌疑犯的使用案例。StreamingSQL 当前基于 Spark 1.4.1 版本,而 Spark 社区里正在打造另一套融合批量数据和流式数据的方案, Streaming DataFrames。程浩认为未来 Spark 中的批处理和流处理两种运算将会合二为一。
Todd Lipcon: Fast Analytics on fast data##

Todd 是 Hadoop 社区的神一样的工程师,Hadoop 和 HBase 的 PMC 和 Committer,包括highly-available metadata journaling (QJM) and automatic failover for HDFS。 自2012年起,开始在Cloudera领导Kudu项目。
当前的Hadoop生态系统
演讲中,Todd 首先指出了当今 Hadoop 存储系统中存在的问题。HDFS (Parquet) 适合做大量数据的离线分析,HBase 适合作在线数据的随机访问,没有一个系统兼具两者的优势。随着超快速超大容量内存设备的出现,存储系统的瓶颈将转向 CPU,而当前的存储系统在设计之初并未考虑到 CPU 的效率。
Kudu设计目标
大扫描高通量,短期访问的低延迟,类数据库的语义,关系数据模型等。Kudu 就是为了解决这些问题而诞生的,它能同时满足 OLAP 和 OLTP 两种需求。在使用上,Kudu 的表像传统数据库,有主键,不能无限制添加列;同时 Kudu 提供了 NoSQL 风格的用户接口;此外,Kudu 实现了与 MapReduce,Spark 与 Impala 的集成。在性能上,Kudu 可以扩展到上千个节点,存储 PB 级数据,每秒处理百万次读写。
Kudu 最适合于顺序读写和随机读写混合的应用,这一点 Todd 以小米的使用场景为例。借助 Kudu, 小米简化了大数据分析平台,原数据无需通过其它组件即可直接导入 Kudu 进行分析。每天有超过 50 亿条记录写入 Kudu,延时从小时(天)级下降到秒级。
Kudu的使用案例
Kudu是随机读取和写入同时结合。
时间序列示例:流市场数据;欺诈检测和预防;风险监控。
工作负载:插入,更新,扫描,查找。
机器数据分析例如:网络威胁检测。
工作负载:插入,扫描,查找。
在线报告示例:ODS。
工作负载:插入,更新,扫描,查找。
什么是Kudu
Todd 详细解释了 Kudu 的架构设计。Kudu 中表被水平分割为多个 Tablets,数据存在服务器的本地硬盘上。每个 Tablet 有多个备份,备份之间通过 Raft 协议保持一致性。master 负责管理表的元数据,为了提高性能,元数据同时缓存在客户端的内存中。Kudu 采用了列存储,这既能压缩节省空间提高吞吐量,同时对于高选择性的请求非常高效。
在 TPC-H 的大部分测试上,Kudu 都比 Parquet 有更好的性能,这也在小米的真实业务测评中得到验证。此外,Kudu 正在成为 Apache Incubator 项目。
责编:魏伟,关注Docker和OpenStack,欢迎投稿,邮箱weiwei@csdn.net
更多云计算资讯,请扫描下方二维码关注我们:
















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









