






给数据科学家提供最好的工作工具是非常困难的。他们的电脑上几乎需要有所有的功能,如极致的性能,最新的软件,以及随心所欲的试验。
我们为此开发了一套满足上述所有需求的方案,并且避免了经常困扰系统管理员和开发团队构建系统的重复性劳动。
tl;dr - 环境创建代码已经上传至Github上。
它目前仍然是完善中的实验品,但是已经可以工作。因为它的许多工具目前都还在软件生存周期的早期,所以它日后会越来越好。

告别云
对于计算密集型业务,公有云的托管费用高的令人望而却步。一个AWS上高性能的跑在GPU上的虚拟机大概要超过正常价格20倍的费用,以日计费会更贵。年费大约是25,000美元。
内部部署的虚拟服务器会相对便宜点,但是并没有对这些科学计算的用例而针对性调整,并且也不是共享环境友好的。
当然,还有其他一些问题… …
你好,老朋友
你身边的服务器又回来了,并且比以往更好。Nvidia在2015年发布了“Dev Box”,一种数据科学家的梦想机器。虽然它有一点点小贵,大概15,000美元。
Andrej Karpathy 创建了一个相对完美并且廉价的家庭套装。并且它可以扩展到和Nvidia的机器同样的性能。我们的产品相当类似,并且给它找了个好地方,就在桌子的右下角。
开发即产品
现在你已经有了合适的硬件。然后你可以参照Nvidia的指示文档来安装和配置所需的所有软件。接下来花上几个小时手工处理软件包和相互依赖性上。它工作很完美,但是这对系统管理员是个噩梦,因为它是完全定制化的。
你用这个机器的时间越长,你就越难以去重建它。假如它死机了,或者是你需要做大的版本升级,或者是你需要创建多个一次性使用的临时方案。
停机时间是你的敌人,但是你引入了一个丑陋的故障点,并且无法享受全自动构建的所有益处。
解决方案
第一步:构建Vanilla CoreOS
假设你已经得到了合适的硬件,然后按照已经验证的快速入门指南之一构建你的裸机。CoreOS支持PXE(无盘工作站),iPXE或者是有盘工作站。选择其中任何适合你的方案即可。我们的方案选择的是PXE构建我们的CoreOS系统
第二步:安装CUDA驱动以及Nvidia的设备-一次性操作
克隆Github上的es-dev-stack
$ git clone http://github.com/emergingstack/es-dev-stack.gitDocker镜像编译(大概会花费30分钟时间,需要下载大约2.5G的数据)
$ cd es-dev-stack/corenvidiadrivers
$ docker build -t cuda .编译完成之后,假如这个镜像非常好使,你可能会想要把这个镜像推送到Docker的registry。从而方便你将来基于这个镜像编译其他的镜像。Dockerfile的示例如下:
FROM ubuntu:14.04
MAINTAINER Mike Orzel <mike.orzel@emergingstack.com>
RUN apt-get -y update && apt-get -y install git bc make dpkg-dev && mkdir -p /usr/src/kernels && mkdir -p /opt/nvidia/nvidia_installers
ADD http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run /opt/nvidia/
WORKDIR /usr/src/kernels
RUN git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux
WORKDIR linux
RUN git checkout -b stable v`uname -r` && zcat /proc/config.gz > .config && make modules_prepare
RUN sed -i -e "s/`uname -r`+/`uname -r`/" include/generated/utsrelease.h # In case a '+' was added
# Nvidia drivers setup
WORKDIR /opt/nvidia/
RUN chmod +x cuda_7.0.28_linux.run && ./cuda_7.0.28_linux.run -extract=`pwd`/nvidia_installers
WORKDIR /opt/nvidia/nvidia_installers
RUN ./NVIDIA-Linux-x86_64-346.46.run -a -x --ui=none
RUN sed -i "s/read_cr4/__read_cr4/g" NVIDIA-Linux-x86_64-346.46/kernel/nv-pat.c
RUN sed -i "s/write_cr4/__write_cr4/g" NVIDIA-Linux-x86_64-346.46/kernel/nv-pat.c
CMD ./NVIDIA-Linux-x86_64-346.46/nvidia-installer -q -a -n -s --kernel-source-path=/usr/src/kernels/linux/ && insmod /opt/nvidia/nvidia_installers/NVIDIA-Linux-x86_64-346.46/kernel/uvm/nvidia-uvm.ko现在运行CUDA的Docker容器
# docker run -it --privileged cuda确认Nvidia的驱动已经安装
# lsmod你应该能看到几个名为‘Nvidia’的项目已经安装
安装设备
在root下执行‘mkdevs’脚本来创建设备
# ./mkdevs.sh确认Nvidia的设备已经安装
# cd /dev
# ls -al | grep -i "nvidia"现在你应该能够看到如下的设备已经存在并准备好映射入Docker的容器
crw-rw-rw- 1 root root 247, 0 Jan 4 05:54 nvidia-uvm
crw-rw-rw- 1 root root 195, 0 Jan 4 05:54 nvidia0
crw-rw-rw- 1 root root 195, 1 Jan 4 05:54 nvidia1
crw-rw-rw- 1 root root 195, 255 Jan 4 05:54 nvidiactl至此一切完毕。
现在你应该就可以开始使用几乎一成不变的系统,从而享受容器化带来的益处。请注意,这里我们使用的是特权模式来映射GPU设备到Docker容器,这从共享主机模式角度是一个不安全的方式。
第三步:基于Google TensorFlow的测试案例
警告:这个Dockerfile的编译产生的Docker镜像超过10GB,大概会需要30-40分钟来生成。
这里我们已经添加了一个Jupyter的笔记到Docker镜像来验证GPU功能正常。这是个基本的基于TensorFlow的ConvNet,并足以验证效果。
Docker镜像构建如下:
$ cd es-dev-stack/tflowgpu
$ docker build -t tflowgpu .Dockerfile如下:
FROM b.gcr.io/tensorflow/tensorflow:latest-gpu
MAINTAINER Mike Orzel <mike.orzel@emergingstack.com>
# Add some dependent packages we will need for the build process
RUN apt-get -y update && apt-get -y install git bc make dpkg-dev && mkdir -p /usr/src/kernels && mkdir -p /opt/nvidia/nvidia_installers
# Download the nvidia cuda package
ADD http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run /opt/nvidia/
RUN chmod +x /opt/nvidia/cuda_7.0.28_linux.run
# download the linux kernel source and prepare it for use
WORKDIR /usr/src/kernels
RUN git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux
WORKDIR linux
RUN git checkout -b stable v`uname -r` && zcat /proc/config.gz > .config && make modules_prepare
RUN sed -i -e "s/`uname -r`+/`uname -r`/" include/generated/utsrelease.h # In case a '+' was added
RUN sed -i -e "s/`uname -r`+/`uname -r`/" include/config/kernel.release # In case a '+' was added
# Nvidia drivers setup
WORKDIR /opt/nvidia/
RUN chmod +x cuda_7.0.28_linux.run && ./cuda_7.0.28_linux.run -extract=`pwd`/nvidia_installers
WORKDIR /opt/nvidia/nvidia_installers
RUN ./NVIDIA-Linux-x86_64-346.46.run -a -x --ui=none
RUN sed -i "s/read_cr4/__read_cr4/g" NVIDIA-Linux-x86_64-346.46/kernel/nv-pat.c
RUN sed -i "s/write_cr4/__write_cr4/g" NVIDIA-Linux-x86_64-346.46/kernel/nv-pat.c
RUN ./NVIDIA-Linux-x86_64-346.46/nvidia-installer -q -a -n -s --kernel-source-path=/usr/src/kernels/linux/ --no-kernel-module
# install modules to expected location, cuda will do modprobes in certain situations which require this
WORKDIR /usr/src/kernels/linux
RUN make modules && make modules_install
RUN mv /lib/modules/`uname -r`+ /lib/modules/`uname -r`
WORKDIR /opt/nvidia/nvidia_installers
RUN depmod
# Run jupyter notebook and create a folder for the notebooks
RUN chmod +x /run_jupyter.sh
RUN mkdir /examples
WORKDIR /examples
COPY CNN.ipynb /examples/CNN.ipynb
CMD /run_jupyter.sh执行TensorFlow的Docker容器
下面这个‘docker run’命令会映射新安装的GPU设备到TensorFlow容器中。详细命令如下:
$ docker run --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidia1:/dev/nvidia1 --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia-uvm:/dev/nvidia-uvm -it -p 8888:8888 --privileged tflowgpu打开浏览器并访问Jupyter如下:http://{your dev box IP}:8888,并跑几个实例。Nvidia Titan X上的性能测试应该比Intel i7 CPU快了十倍不止。
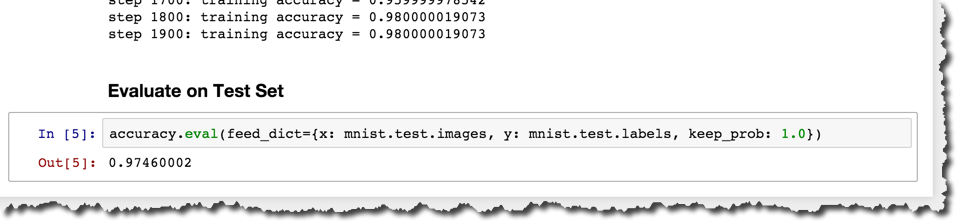
现在就开始使用es-dev-stack,也非常欢迎贡献你的版本。本解决方案的灵感来源于以下几个社区,在此感谢:
Nvidia driver setup via Docker - Joshua Kolden joshua@studiopyxis.com
ConvNet demo notebook - Edward Banner edward.banner@gmail.com
在文下一篇章,我们将会演示如何容器化的Spark环境和Kubernetes整合的潜力(依赖于标准 issue 19049的状态)
原文链接:
http://www.emergingstack.com/2016/01/10/Nvidia-GPU-plus-CoreOS-plus-Docker-plus-TensorFlow.html
责编,魏伟,关注Docker,寻求报道和投稿,请联系邮箱weiwei@csdn.net
















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









