







谷歌于2015年正式推出的Kubernetes开源项目目前已经吸引了众多IT公司的关注,这些公司包括Redhat、CoreOS、IBM、惠普等知名IT公司,也包括国内如华为、时速云等公司。为什么Kubernetes会引发这么多公司的关注?最根本的原因是Kubernetes是新一代的基于先进容器技术的微服务架构平台,它将当前火爆的容器技术与微服务架构两大吸引眼球的技术点完美的融为一体,并且切切实实的解决了传统分布式系统开发过程中长期存在的痛点问题。
本文假设您已经很熟悉并掌握了Docker技术,这里不会再花费篇幅介绍它。正是通过轻量级的容器隔离技术,Kubernetes实现了“微服务”化的特性,同时借助于Docker提供的基础能力,使得平台的自动化能力得以实现。
概念与原理
作为一个架构师来说,我们做了这么多年的分布式系统,其实我们真正关心的并不是服务器、交换机、负载均衡器、监控与部署这些事物,我们真正关心的是“服务”本身,并且在内心深处,我们渴望能实现图1所示的下面的这段“愿景”:
我的系统中有ServiceA、ServiceB、ServiceC三种服务,其中ServiceA需要部署3个实例、而ServiceB与ServiceC各自需要部署5个实例,我希望有一个平台(或工具)帮我自动完成上述13个实例的分布式部署,并且持续监控它们。当发现某个服务器宕机或者某个服务实例故障的时候,平台能够自我修复,从而确保在任何时间点,正在运行的服务实例的数量都是我所预期的。这样一来,我和我的团队只需关注服务开发本身,而无需再为头疼的基础设施和运维监控的事情而烦恼了。
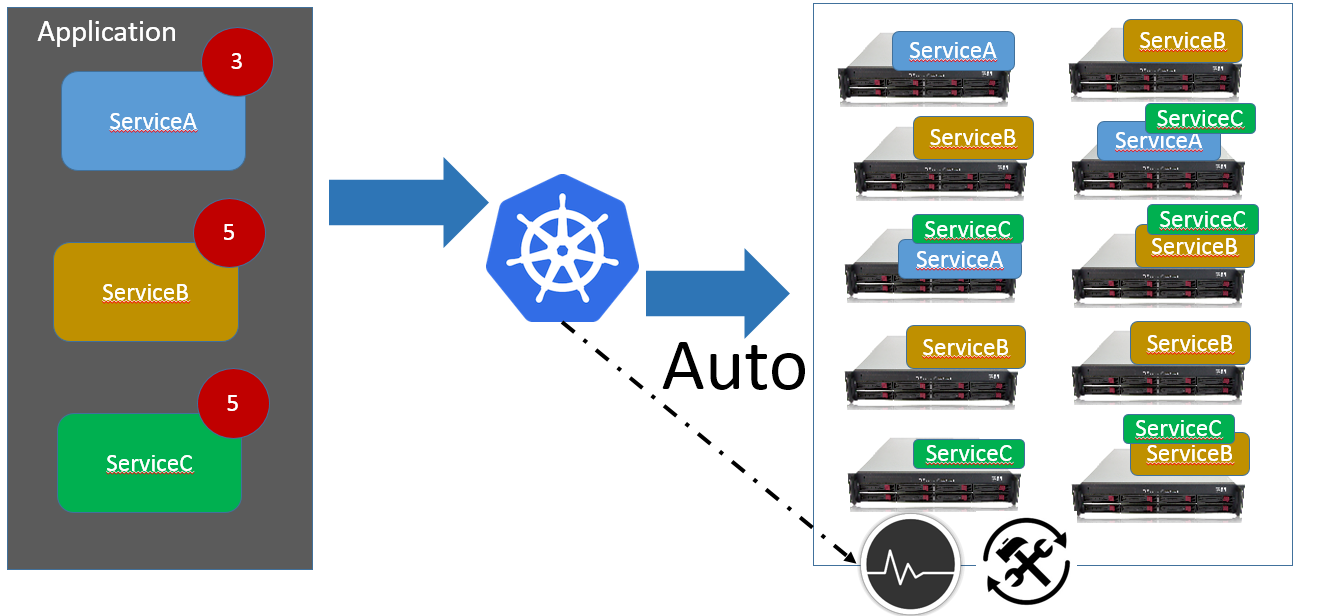
直到Kubernetes出现之前,没有一个公开的平台声称实现了上面的“愿景”,这一次,又是谷歌的神作惊艳了我们。Kubernetes让团队有更多的时间去关注与业务需求和业务相关的代码本身,从而在很大程度上提升了整个软件团队的工作效率与投入产出比。
Kubernetes里核心的概念只有以下几个:
- Service
- Pod
- Deployments(RC)
Service表示业务系统中的一个“微服务”,每个具体的Service背后都有分布在多个机器上的进程实例来提供服务,这些进程实例在Kubernetes里被封装为一个个Pod,Pod基本等同于Docker Container,稍有不同的是Pod其实是一组密切捆绑在一起并且“同生共死”的Docker Container,从模型设计的角度来说,的确存在一个服务实例需要多个进程来提供服务并且它们需要“在一起” 的情况。
Kubernetes的Service与我们通常所说的“Service”有一个明显的的不同,前者有一个虚拟IP地址,称之为“ClusterIP”,服务与服务之间“ClusterIP+服务端口”的方式进行访问,而无需一个复杂的服务发现的API。这样一来,只要知道某个Service的ClusterIP,就能直接访问该服务,为此,Kubernetes提供了两种方式来解决ClusterIP的发现问题:
- 第一种方式是通过环境变量,比如我们定义了一个名称为ORDER_SERVICE 的Service ,分配的ClusterIP为10.10.0.3 ,则在每个服务实例的容器中,会自动增加服务名到ClusterIP映射的环境变量:ORDER_SERVICE_SERVICE_HOST=10.10.0.3,于是程序里可以通过服务名简单获得对应的ClusterIP。
- 第二种方式是通过DNS,这种方式下,每个服务名与ClusterIP的映射关系会被自动同步到Kubernetes集群里内置的DNS组件里,于是直接通过对服务名的DNS Lookup机制就找到对应的ClusterIP了,这种方式更加直观。
由于Kubernetes的Service这一独特设计实现思路,使得所有以TCP /IP 方式进行通信的分布式系统都能很简单的迁移到Kubernetes平台上了。如图2所示,当客户端访问某个Service的时候,K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









