







 本文详细介绍了OpenStack Nova的Cell V2架构,旨在解决控制平面的性能瓶颈,尤其是Message Queue和Database的问题。相较于Cell V1,Cell V2提供了更清晰的边界,提升了性能,并简化了架构。主要内容包括Cell V2的架构、流程、优势以及Kolla的实现。此外,还讨论了自动发现计算节点的功能和性能分析。
本文详细介绍了OpenStack Nova的Cell V2架构,旨在解决控制平面的性能瓶颈,尤其是Message Queue和Database的问题。相较于Cell V1,Cell V2提供了更清晰的边界,提升了性能,并简化了架构。主要内容包括Cell V2的架构、流程、优势以及Kolla的实现。此外,还讨论了自动发现计算节点的功能和性能分析。
现在 ,OpenStack 在控制平面上的性能瓶颈主要在 Message Queue 和 Database 。 尤其是 Message Queue , 随着计算节点的增加 , 性能变的越来越差 。 为了应对这种情况 , Nova 很早之前提出来 nova-cell ( 以下以 cellv1 代替 ) 的解决方案 。 目的是在把大的 OpenStack 集群分成小的单元 , 每个单元有自己的 Message Queue 和 Database。 以此来解决规模增加时引起的性能问题 。 而且不会向 Region 那样 , 把各个集群独立运行 。 在 cell 里面 ,Keystone、Neutron、Cinder、Glance 等资源还是共享的 。
cell v1
cellv1 最初的想法很好 , 但是局限于早期 nova 的架构 , 硬生生的加个 nova-cell 服务来在各个 cell 间传递消息 , 使得架构更加复杂 。 以下是 cellv1 的架构
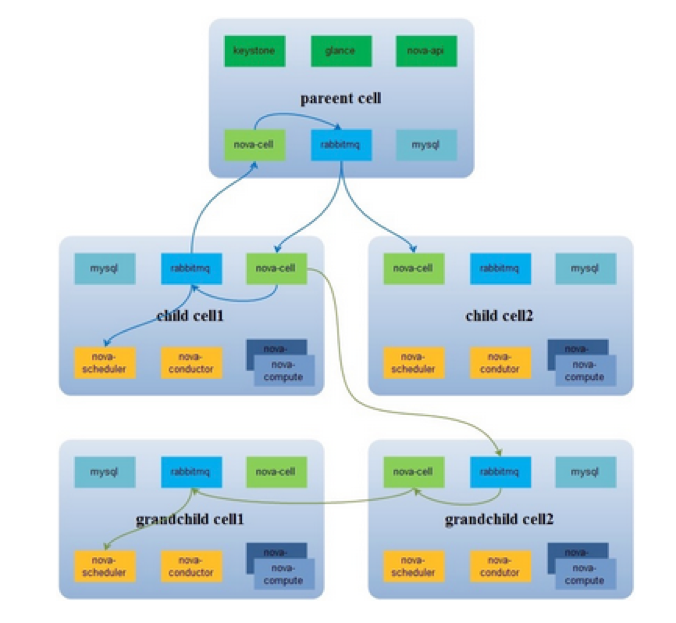
cell v1 的问题在于 :
- 一直以来 ,cell v1 被标记为实验性质
- 相关的测试很少 , 而且也没有 v1 + neutron 的测试
- 现在来说功能已经冻结 , 不会加入新的功能
- 不严重的 Bug 根本不会去修复
- 使用案例很少 。 现在经常提到的使用案例也只有 CERN( 欧洲原子能研究中心 )。 一般规模下 , 完全没有必要搭建 cell v1
所以, 现在进行部署的话,如果用 cell, 就尽量使用 cell v2 吧 。
cell v2
cell v2 自 Newton 版本引入 ,Ocata 版本变为必要组件 。 以后默认部署都会初始化一个单 cell 的架构 。cell v2 的架构图如下 , 看着比 cell v1 清爽不少 。
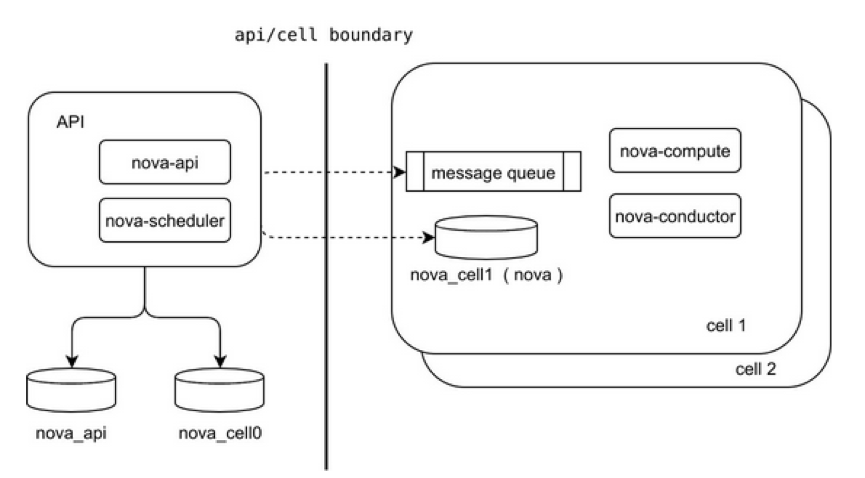
从架构图上 , 可以看到 :
- api 和 cell 有了明显的边界 。 api 层面只需要数据库 , 不需要 Message Queue。
o nova-api 现在依赖 nova_api 和 nova_cell0 两个数据库 。 - nova-scheduler 服务只需要在 api 层面上安装 ,cell 不需要参数调度 。 这样实现了一次调度就可以确定到具体在哪个 cell 的哪台机器上启动
o 这里其实依赖 placement 服务 , 以后的文章会提到 - cell 里面只需要安装 nova-compute 和 nova-conductor 服务 , 和其依赖的 DB 和 MQ
- 所有的 cell 变成一个扁平架构 。 比之前的多层父子架构要简化很多 。
- api 上面服务会直接连接 cell 的 MQ 和 DB, 所以不需要类似 nova-cell 这样子的额外服务存在 。 性能上也会有及大的提升
nova_api & nova_cell0
自 Newton 版本 ,nova 就一直拆分 nova 数据库 , 为 cell v2 做准备 。 把一些全局数据表从 nova 库搬到了 nova_api, 下面是现在 nova_api 里面的所有表 。
+------------------------------+ +------------------------------+
| Tables_in_nova_api | | Tables_in_nova_api |
+------------------------------+ +------------------------------+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









