







 本文介绍了去哪儿网如何基于Marathon和Docker实现Spark 2.0动态扩容,解决了Mesos-dispacher架构存在的问题。通过Marathon+Docker统一架构,实现了Spark Executor的动态挂载,确保Driver和Executor的同步,优化了资源管理和监控。
本文介绍了去哪儿网如何基于Marathon和Docker实现Spark 2.0动态扩容,解决了Mesos-dispacher架构存在的问题。通过Marathon+Docker统一架构,实现了Spark Executor的动态挂载,确保Driver和Executor的同步,优化了资源管理和监控。
作者简介:李雪岩:趣拿软件平台事业部数据平台研发工程师,现主要负责资源管理系统Mesos和分布式计算系统的持续集成开发,为各业务线的数据方面基础公共服务支持,主要设计ELK日志ETL平台,Spark+Flink批处理系统和流式处理系统,Zeppelin交互式处理系统的发布与监控。
徐磊:去哪儿网平台事业部数据平台高级研发工程师,负责实时日志处理工作,曾任职于RedHat。
吕晓旭:去哪儿网平台事业部资深工程师,在大规模业务系统监控和数据处理领域有较丰富的经验,曾供职于Yahoo!和淘宝。
声明: 本文为《程序员》原创文章,未经允许请勿转载,更多精彩文章请订阅 2017 年《程序员》。
背景:去年10月,我们实现了Spark 1.5.2版本运行在Mesos这个资源管理框架上。随后Spark出了新版本我们又对Spark进行了小升级,升级并没有什么太大的难度,沿用之前的修改过的代码重新编译,替换一下包,把历史任务全部发一遍就能很好的升级到1.6.1也就是现在集群的版本,1.6.2并没有升级因为感觉改动不是很大。到现在正好一年的时间,线上已经注册了44 个Spark任务,其中28个为Streaming任务,在运行这些任务的过程中,我们遇到了很多问题,其中最大的问题是动态扩容问题,即当业务线增加更复杂的代码逻辑或者业务的增长导致处理量上升的时候会使Spark因计算资源不足,这时候如果没有做流量控制则Spark任务会因内存承受不了而失败,如果做了流量控制则Kafka的lag会有堆积,这时候一般就需要增加更多的executor来处理,但是增加多少合适一般不太好判断,于是要反复地修改配置重新发布来找到一个合理的配置。
我们在Marathon上使用Logstash的时候也有类似的问题,当由于接入一个比较大的日志导致流量突然增加使得Logstash处理不了时,Kafka的Lag产生堆积,这时我们只需直接上Marathon的界面上点Scale然后填入更大的实例数字就能启动了一些Logstash实例自动平衡地去处理了。当发现某个结点是慢结点不干活的时候,只需要在Marathon上将对应的任务Kill掉就会自动再发一个任务替补他的位置,那么Logstash既然都可以做到为什么Spark不可以?因此我们决定在Spark 2.0版本的时候来实现这个功能,同时我们也会改进其它的一些问题,另外Spark2.0是一个比较大的版本升级,配置与之前的1.6.1不同,不能做到直接全部重发一遍任务来做到全部升级。
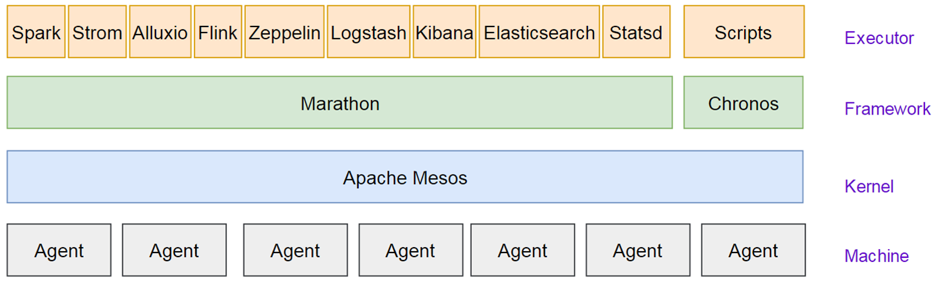
Mesos-dispacher架构与问题
在这里我们首先介绍一些Mesos的一些相关概念,Mesos的Framework是资源分配与调度的发起者,Spark自带了一个spark-mesos-dispacher的Framework用来管理Spark的资源调度。而Marathon也是一个Framework他的本质和mesos-dispacher或spark schedular相同。
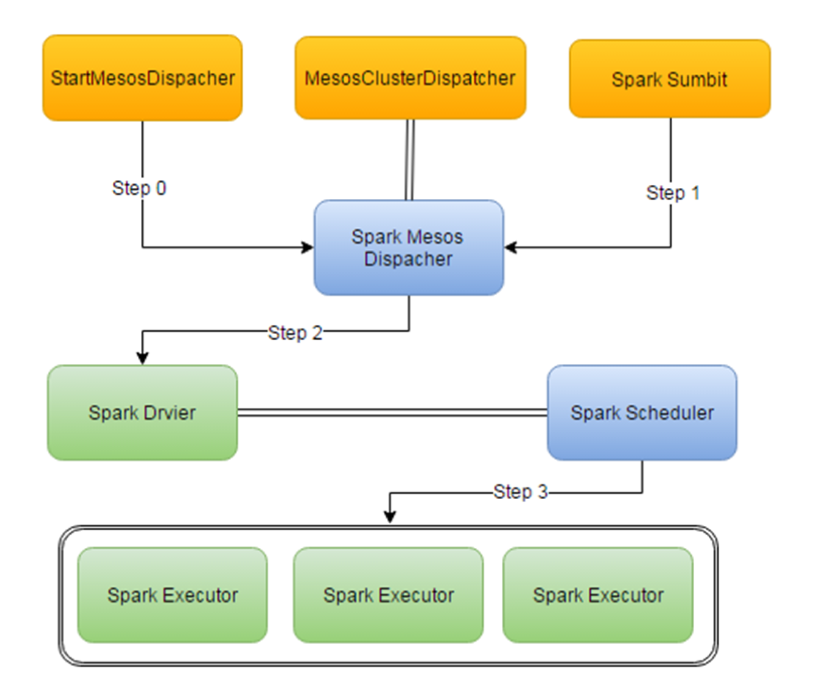
在图2在这个架构中,你首先得向mesos注册一个mesos-dispacher的Framework,然后,通过spark-sumbit脚本来向mesos-dispacher发布任务,mesos-dispacher接到任务以后开始调度他负责发一个Spark Driver,然后driver在mesos模式下,他会再次向mesos注册这个任务的Framework也就是我们看到的Spark UI,也可以理解为他自己也是个调度器,然后这个Framework根据配置来向Mesos申请资源来发一些Spark Executor。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









