






Redisson 可重入 & 可重试 & 超时释放 & multiLock 的实现思路
本文旨在帮助你快速了解 Redission 可重入 & 可重试 & 超时释放 & multiLock 的实现的思路原理,流程图来自黑马redis课程(流程图就是详细的实现思路了,可以作为拓展补充)
目录:
- 简单Redis分布式锁
- setnx锁的不足
- 可重入
- 超时释放
- multiLock
- 体会
简单Redis分布式锁
最基础的redis锁使用setnx k v的特性,k不存在时返回1,存在则不能覆盖,返回-1。使用这个可以做到添加锁成功,返回1(SpringDataRedis转为true),重复获取锁失败,返回0(转为false),del删除key(释放锁),这样便可以是实现一个简单的redis锁。
setnx锁的不足:
基于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
超时释放:我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。
这些问题,通过Redisson实现的锁中得到了解决
可重入
可重入指的是同一个线程可以重复获取一个锁,这样可以避免同线程锁调用出现的死锁问题。
实现原理类似jdk的 ReentrantLock,存储的是一个hash类型,Key (k,v),k存储的是线程标识符,v存储该线程获取锁的次数。
实现的整个逻辑简单来说就是,线程a第一次获取锁,存储hash类型,v为1,第二次获取锁v++。。。当第一次释放锁v- -,一直到v减到0,表示锁释放完毕。(整个过程为了确保原子性,使用lua脚本实现,原码的lua脚本是在代码中写死的)
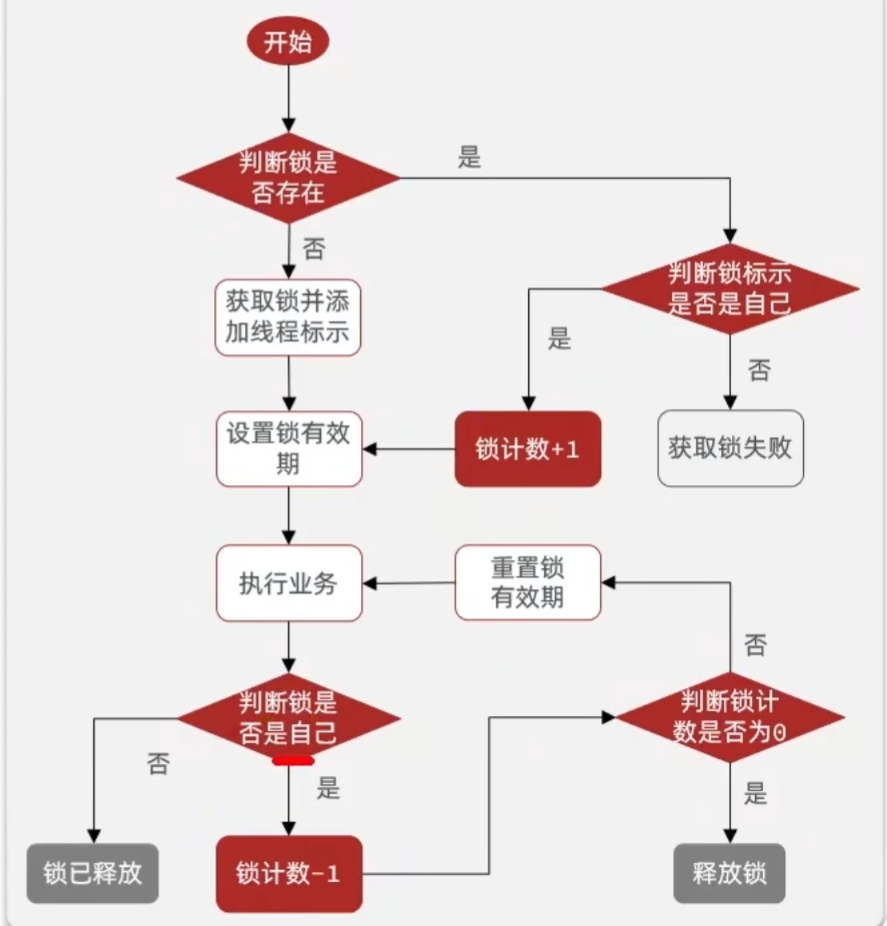
可重试
代码很复杂,这里简述逻辑,当你参数传递waitTime,假设是1s,线程a第一次尝试获取锁失败,说明线程被别的锁拿着,这时线程a会执行waitTime-=(前面这整个流程的时间),如果剩余时间>0,说明还有可以用来尝试的时间。
然后,它会”订阅”获取锁的那个线程,因为源码中,成功线程释放锁会publish一个通知给别的线程,它订阅监听这个通知,有通知了,再来获取锁(当然,这之前还要再判断时间是否有剩余)。
这个订阅的思想,可以避免线程获取锁失败之后重复的无效循环获取,防止给cpu上压力。
然后就是循环上面这个流程,具体代码实现可能不同,但是基本就是这个思想,一直到时间超时return false或者成功获取到锁为止。
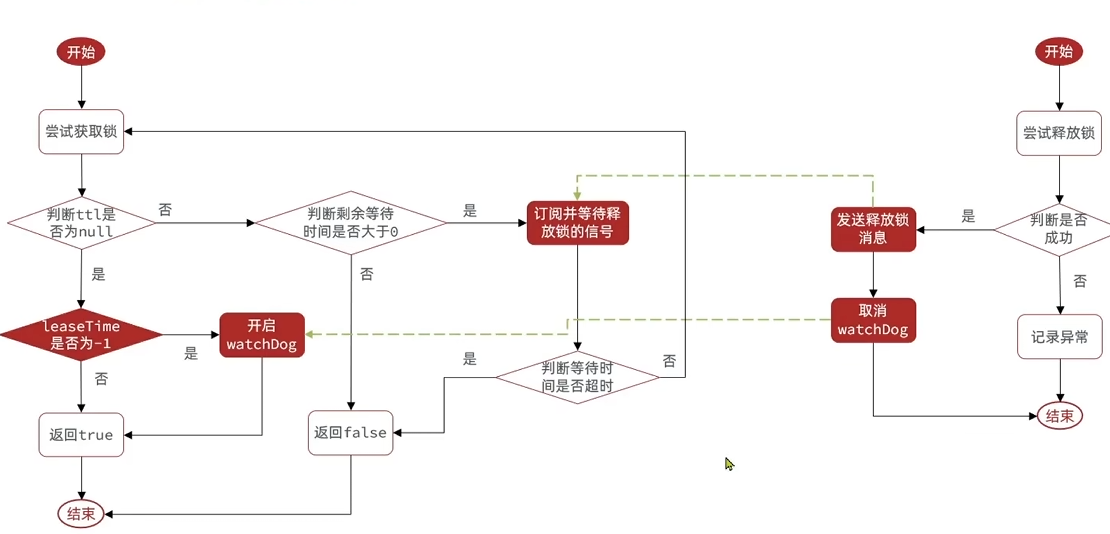
超时释放
- 当
leaseTime = -1时(默认值):- 会启用看门狗机制,锁的默认过期时间为30秒(可通过
Config.lockWatchdogTimeout配置)。 - 看门狗会每10秒自动续期一次(即
internalLockLeaseTime / 3),将锁的过期时间重置为30秒,从而保证锁在业务执行期间不会因超时而被释放。 - 这种机制实现了递归续期的效果,只要锁未被显式释放(
unlock()),看门狗会持续续期,直到锁被主动释放或客户端宕机(此时续期停止,锁最终超时释放)。
- 会启用看门狗机制,锁的默认过期时间为30秒(可通过
- 当
leaseTime ≠ -1时(用户显式设置过期时间):- 不会启用看门狗机制,锁的过期时间严格按用户设置的
leaseTime生效。 - 锁会在
leaseTime到期后自动释放,无自动续期功能。这种设计适用于需要精确控制锁持有时间的场景
- 不会启用看门狗机制,锁的过期时间严格按用户设置的
multilock
一主多从的形式,当主刚刚获取锁,还没来得及同步到其他从节点时宕机,这时从节点中其中之一成为主节点,没有刚刚锁的信息,相当于原本主节点的锁失效了,可能造成并行问题。
Redisson的多redis节点部署采取multilock的形式,意思是默认所有节点都是主节点,获取锁所有节点都获取锁,释放锁必须所有节点都释放锁,才算成功。
这样最可靠,但是对应成本更高,实现复杂。
体会
看了一些源码和思路实现,发现大佬的源码也是朴实无华的,思路很多也是简单粗暴的,引用《代码大全》一句话:“聪明的数据结构和笨拙的代码,比相反的组合工作得更好。”

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









