







接上文,名片全能王,虽然自称王,且敢当王的肯定不白给,但不代表这款产品没有毛病的地步。
做为专业人士,不得不吐槽一下,中文名字处理问题就很大,片全能王还得有做更多的工作才配那78块钱和那个名字,先看个错误:
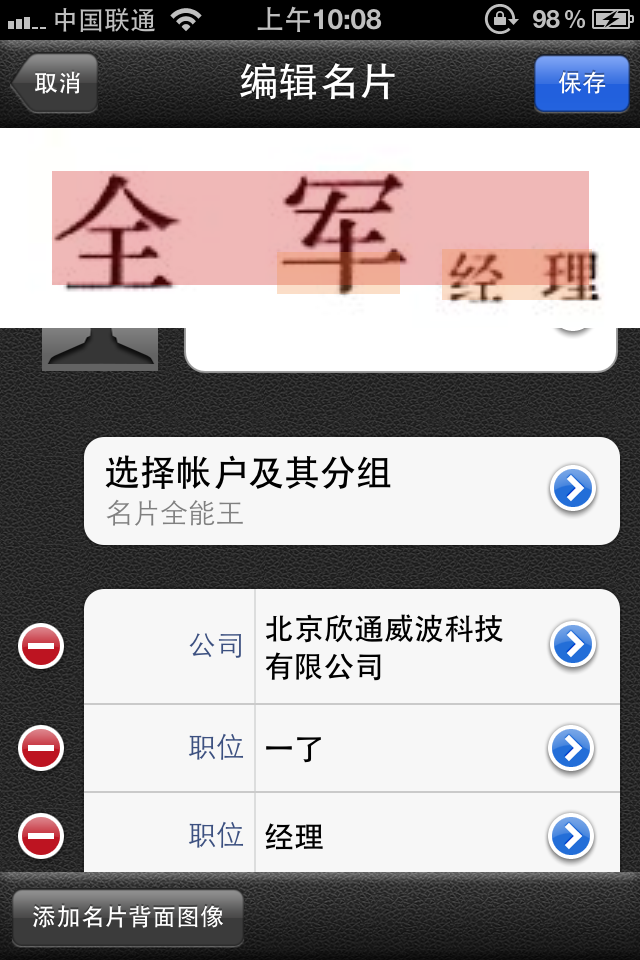
正确的处理结果应当是这样的

名片全能王的错误在于:全军识别成了全室,职位还多了个 ”一了“,很是莫名其妙。
出现这类错误,只能说名片全能王 名字提取处理过于简单了,仅仅是联通区测试。
当然,名片识别过程中,名字是最难提取的,因为名字样式极其多变,要100%准确提取名字内容,并非易事。但名片扫描通
ScanZen做了这件事,并且愿意分享这些成果。
那如何才能100%准确提出名字呢?让我们先对名字进行分类以及约定:
- 大字体名字
- 名字字符间距大
- 有Title环绕的名字
- title与名字距离大
- title与名字距离小
- 无Title环绕的名字
- 有Title环绕的名字
- 名字字符间距小
- 名字字符间距大
- 小字体名字
- 有Title环绕的名字
- 无Title环绕的名字
名字提取要考虑因素有:字体大小、字符间距、字体粗细、Title环绕(左右上下),只要针对这多种组合进行处理,名字是完全能准确提取出来的。
处理办法:
在做版面分析时,分阶段强化提取联通区,找到象大字体名字行
LogoParse::LogoParse(Mat& card):m_scale(SCALE_IMG_WHEN_LAYOUT_PARSE)
{
INFO << __FUNCTION__ <<std::endl;
assert(1==m_scale);
cv::bitwise_not(card, m_cropped);
//如果比BCR_5Point更大的话,会引发版面左右粘连
rlsaInHorizon(m_cropped, BCR_10POINT/m_scale);
//x方向不要处理,会引发左右丢字或者 名字名 孟,上面的子被处理没了
int erosion_type = MORPH_RECT; // MORPH_RECT, MORPH_CROSS, MORPH_ELLIPSE
int erosion_size = 2;
Mat erosion_element = getStructuringElement( erosion_type, Size( 2*0 + 1, 2*erosion_size+1), Point( 0, erosion_size));
cv::erode(m_cropped, m_cropped,erosion_element);
cv::dilate(m_cropped, m_cropped,erosion_element);
//find blobs
{
IplImage cropped(m_cropped);
// get blobs and filter them using its area
//CBlobResult blobs;
// find blobs in image
try {
blobs = CBlobResult( &cropped, NULL, 0 );
} catch (...) {
ERROR << "CBlobResult throw exception" <<std::endl;
}
int N = blobs.GetNumBlobs();
for( int j=0; j<N; j++)
{
CBlob *currentBlob = blobs.GetBlob(j);
CvRect rect = currentBlob->GetBoundingBox();
//scale it
rect.x *= m_scale;
rect.y *= m_scale;
rect.width *= m_scale;
rect.height *= m_scale;
//过滤没有成行的版面(如长宽比不足的,小于2);简章的版面识别
if (
rect.height > BCR_1POINT &&
rect.height < BCR_10POINT&&
double(rect.width)/rect.height > 2
)
{
currentBlob->FillBlob(&cropped, CV_RGB(0, 0, 0));
}
}
rlsaInHorizon(m_cropped, BCR_20POINT*1.5/m_scale);
rlsaInVertical(m_cropped, BCR_10POINT/m_scale);
int erosion_type = MORPH_RECT; // MORPH_RECT, MORPH_CROSS, MORPH_ELLIPSE
int erosion_size = 2;
Mat erosion_element = getStructuringElement( erosion_type, Size( 2*erosion_size + 1, 2*erosion_size+1), Point( erosion_size, erosion_size));
cv::erode(m_cropped, m_cropped,erosion_element);
cv::dilate(m_cropped, m_cropped,erosion_element);
{
// find blobs in image
try {
blobs = CBlobResult( &cropped, NULL, 0 );
} catch (...) {
ERROR << "CBlobResult throw exception" <<std::endl;
}
IplImage editImage(card);
int N = blobs.GetNumBlobs();
for( int j=0; j<N; j++)
{
CBlob *currentBlob = blobs.GetBlob(j);
CvRect rect = currentBlob->GetBoundingBox();
//scale it
rect.x *= m_scale;
rect.y *= m_scale;
rect.width *= m_scale;
rect.height *= m_scale;
//提取大概的大字体名字行
if (
rect.height > BCR_10POINT &&
rect.height < BCR_20POINT &&
double(rect.width)/rect.height > 2.0 &&
double(rect.width)/rect.height < 10.0
)
{
m_nameBox.push_back(rect);
}
else
{
currentBlob->FillBlob(&editImage, CV_RGB(255, 255, 255));
}
}
}
}
//尽快释放内存
m_cropped.release();
INFO << __FUNCTION__<< " end" <<std::endl;
}大字体名字行可能包含了Tile,对名字行还需要进行分割处理,行内进行聚类分析,将名字与Title拆开
std::vector<LineStatic> LineStatic::ccl_name_title() const
{
/**
* case 1: NNN TTT (可归为按空格分)
* case 2: NNN ttt (字体高低有别且有别处有空格)
* case 3: N N N ttt
*/
//字体高度分类
此处理省去1000字 // 输出分簇结果
for(int i=0;i<clusters.size();i++)
{
BCR::Point center = clusters[i].getCenter();
mincomplexity = std::min(mincomplexity, center.coordinate[0]);
if (mincomplexity == center.coordinate[0]) {
mini = clusters[i].getPoints();
num_eng = mini.size();
}
else
{
num_chi = clusters[i].getPoints().size();
}
cout << clusters[i] << endl;
}
INFO << "TotalClustersDistance:" << BCR::KMeans::TotalClustersDistance(clusters) << endl;
for (std::vector<BCR::Point>::iterator it = mini.begin(); it != mini.end(); it++) {
mini_bg = std::min(mini_bg, it->coordinate[0]);
mini_ed = std::max(mini_ed, it->coordinate[0]);
}
BCR::Point eng_center = clusters[0].getCenter();
BCR::Point chi_center = clusters[1].getCenter();
if (eng_center.coordinate[0] > chi_center.coordinate[0]) {
std::swap(eng_center, chi_center);
}
title_height = eng_center.coordinate[0];
name_height = chi_center.coordinate[0];
title_width = eng_center.coordinate[1];
name_width = chi_center.coordinate[1];
}
//高低相差大于5号字,分行
std::vector<LineStatic> nametitle;
double averHeightDiff = this->rect.height*0.2;
if ((std::abs(name_height - title_height) > averHeightDiff ||
std::abs(name_width - title_width) > averHeightDiff)
&&
title_height > BCR_5POINT/2 &&
name_height > BCR_5POINT*1.5
)
{
t_boxes name;
t_boxes title;
t_boxes::const_iterator it = words.begin();
t_boxes::const_iterator it_pre = it;
for (; it != words.end(); it++)
{
//名字字体大于title,且在空格处
int space = it->x - it_pre->x - it_pre->width ;
it_pre = it;
if( std::max(it->width,it->height) < name_height - averHeightDiff && space > BCR_5POINT/2)
{
break;
}
else
{
name.insert(*it);
}
}
for (; it != words.end(); it++)
{
//名字字体大于title
title.insert(*it);
}
//double check
LineStatic nameL(name);
LineStatic titleL(title);
if (nameL.rect.height - titleL.rect.height > BCR_DOT_POINT*2) {
nametitle.push_back(nameL);
nametitle.push_back(titleL);
}
}
if (0==nametitle.size()) {
nametitle.push_back(words);
}
return nametitle;
}
// 输出分簇结果
for(int i=0;i<clusters.size();i++)
{
BCR::Point center = clusters[i].getCenter();
mincomplexity = std::min(mincomplexity, center.coordinate[0]);
if (mincomplexity == center.coordinate[0]) {
mini = clusters[i].getPoints();
num_eng = mini.size();
}
else
{
num_chi = clusters[i].getPoints().size();
}
cout << clusters[i] << endl;
}
INFO << "TotalClustersDistance:" << BCR::KMeans::TotalClustersDistance(clusters) << endl;
for (std::vector<BCR::Point>::iterator it = mini.begin(); it != mini.end(); it++) {
mini_bg = std::min(mini_bg, it->coordinate[0]);
mini_ed = std::max(mini_ed, it->coordinate[0]);
}
BCR::Point eng_center = clusters[0].getCenter();
BCR::Point chi_center = clusters[1].getCenter();
if (eng_center.coordinate[0] > chi_center.coordinate[0]) {
std::swap(eng_center, chi_center);
}
title_height = eng_center.coordinate[0];
name_height = chi_center.coordinate[0];
title_width = eng_center.coordinate[1];
name_width = chi_center.coordinate[1];
}
//高低相差大于5号字,分行
std::vector<LineStatic> nametitle;
double averHeightDiff = this->rect.height*0.2;
if ((std::abs(name_height - title_height) > averHeightDiff ||
std::abs(name_width - title_width) > averHeightDiff)
&&
title_height > BCR_5POINT/2 &&
name_height > BCR_5POINT*1.5
)
{
t_boxes name;
t_boxes title;
t_boxes::const_iterator it = words.begin();
t_boxes::const_iterator it_pre = it;
for (; it != words.end(); it++)
{
//名字字体大于title,且在空格处
int space = it->x - it_pre->x - it_pre->width ;
it_pre = it;
if( std::max(it->width,it->height) < name_height - averHeightDiff && space > BCR_5POINT/2)
{
break;
}
else
{
name.insert(*it);
}
}
for (; it != words.end(); it++)
{
//名字字体大于title
title.insert(*it);
}
//double check
LineStatic nameL(name);
LineStatic titleL(title);
if (nameL.rect.height - titleL.rect.height > BCR_DOT_POINT*2) {
nametitle.push_back(nameL);
nametitle.push_back(titleL);
}
}
if (0==nametitle.size()) {
nametitle.push_back(words);
}
return nametitle;
}
还要对OCR结果进行分析,找到最象名字的那个名字框
//(1): first name
if (double(line.rect.width) / line.rect.height < 5.0 && strlen(name) > 1) {
std::string firstCharactor(name,3);
char* pos = strstr(ALL_CHINESE_FIRSTNAME, firstCharactor.c_str());
if (pos) {
weight += 10000;
tprintf("Chinese Name checked %s\n", firstCharactor.c_str());
}
}经过这样 联通区提取、再分割、再确认,最终总能找到名片中最象名字的那一块内容。整个识别过程与人脑看名字的思路是一样的,先缩小范围,聚焦,再识别。
识别结果是这样的,有图有真相,下面是测试的结果图:

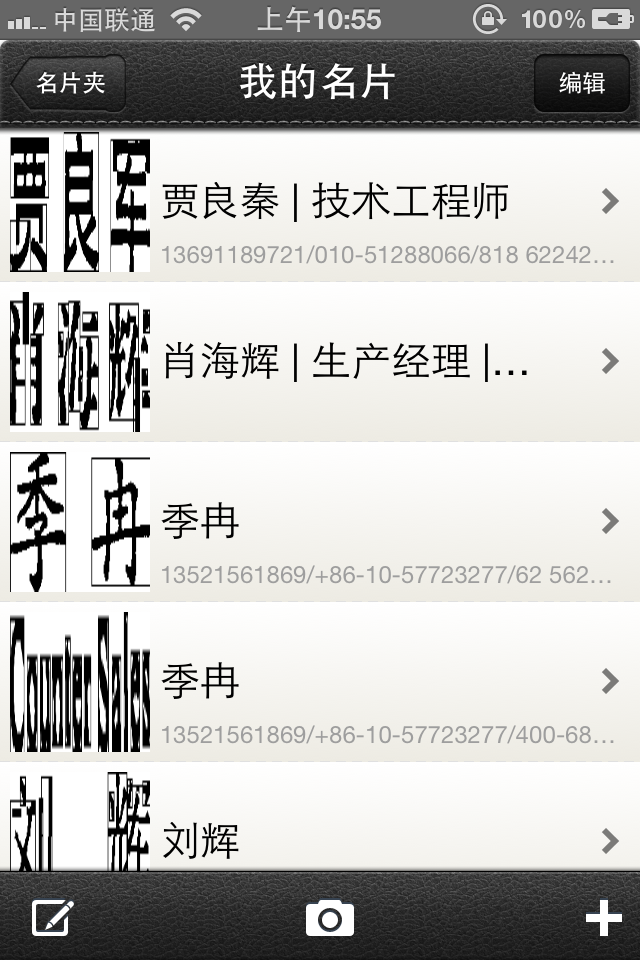
刚刚完善了名字提取功能,app还来的及升级!如您想测试一下,可以到App store中下载 名片扫描通 ScanZen















 3202
3202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









