






前言,我对根文件系统的一些体会:
接下来大家看到的《linux文件系统》三篇文章,写的是极好。但是要完全理解还是需要对根文件系统有个比较深刻的了解。
我们提到的根文件系统根据使用的时机,其实分为三种:第一种是在内核启动时由内核在内存中创造出来的一个虚拟的rootfs,这个rootfs只有超级块和根目录。第二种是用户生成的内存根文件系统,早期是initrd,后来是initramfs和tmpfs,这三种根文件系统相对来说会完整一些包含了各种库函数和命令,供内核启动时调用。第三种是保存在磁盘或者是flash中的能够提供完整功能的根文件系统,可以供内核和用户调用。
下面简单讲下三种根文件系统是在何时被使用到的:
**1.**bootloader在加载内核时会把initramfs(或者是initrd,tmpfs)和kernel一起加载到内存中。对于嵌入式这个initramfs就是最终的根文件系统(这是一个完整的,包含各种lib,各种命令和文件)。(这个initramfs里面的目录和文件,会被kernel copy到内核创造出的内存rootfs空间中)。
**2.**由于我们不想把kernel变得很大,并没有把保存根文件系统的硬件驱动包含在kernel中,这时内核是没有办法挂载在外部设备中的根文件系统。为了解决这个问题,内核最开始会生成一个内存rootfs。这个rootfs只有根目录,里面没有任何文件。然后内核会把这个内存rootfs挂载到vfs系统中。然后这个内存rootfs会把initramfs中的内容copy到他自己的空间中,形成了一个比较完整根文件系统。
**3.**对于有些嵌入式来说,完成上面两个步骤根文件系统就已经构建完成了。也有些嵌入式系统的内核可以直接挂载Emmc中的rootfs(可以参考《浅谈ARM嵌入式中的根文件系统rootfs 》这篇博文:https://blog.csdn.net/katerdaisy/article/details/135747568)。但是对于大部分设备来说,内核还会把内存rootfs替换成磁盘中的根文件系统。
内核可以直接挂载Emmc中的rootfs,uboot传递参数如下:
mmcargs=setenv bootargs console= ttymxc0, 115200 root= /dev/mmcblk1p2 rootwait rw
其中root=/dev/mmcblk1p2 用于指明根文件系统存放在
内核要使用内存rootfs和initrd时,uboot传递参数如下:
setenv bootargs mem=120M console=ttyS0,115200n8 root=/dev/ram0 rw initrd=0x82000000,29M ip=192.168.1.14:192.168.1.13:192.168.1.1:255.255.255.0
其中root=/dev/ram0指明根文件系统存放在内存ram0中,initrd=0x82000000指明initrd在内存中的位置。
总的来说,我们需要linux需要一个根文件系统提供的库和命令集,但是在linux内核还没有完全初始化之前还没有办法访问外部存储设备上的根文件系统时,就需要一个折中的方法。如上面所讲的会在内存中先构建一个够linux初始化的根文件系统,于是就有了内存rootfs和initramfs。
linux文件系统 - 初始化(一)
https://www.cnblogs.com/alantu2018/p/8447303.html
术语表:
struct task:进程
struct mnt_namespace:命名空间
struct mount:挂载点
struct vfsmount:挂载项
struct file:文件
struct super_block:超级块
struct dentry:目录
struct inode:索引节点
一、目的
linux文件系统主要分为三个部分:文件系统调用;虚拟文件系统(VFS);挂载到VFS的实际文件系统。
其中,VFS是核心,linux文件系统的本质就是在内存中创建一棵VFS树。当根目录被创建后,用户就可以使用系统调用在VFS上创建文件、删除文件、挂载各种文件系统等操作。
该系列文章主要分析linux3.10文件系统初始化过程,分为三个阶段:
1、挂载根文件系统(rootfs);
2、加载initrd;
3、挂载磁盘文件系统;
二、常用数据结构
linux文件系统中重要的数据结构有:文件、挂载点、超级块、目录项、索引节点等。每个数据结构的具体实现请参见源代码,这里不再描述。
为了直观的表示数据结构之间的关系,请参见图1:图中含有两个文件系统(红色和绿色表示的部分),并且绿色文件系统挂载在红色文件系统tmp目录下。一般来说,每个文件系统在VFS层都是由挂载点、超级块、目录和索引节点组成;当挂载一个文件系统时,实际也就是创建这四个数据结构的过程,因此这四个数据结构的地位很重要,关系也很紧密。由于VFS要求实际的文件系统必须提供以上数据结构,所以不同的文件系统在VFS层可以互相访问。
如果进程打开了某个文件,还会创建file(文件)数据结构,这样进程就可以通过file来访问VFS的文件系统了。
另外,该图只给出了主要的关系结构,忽略了部分细节。
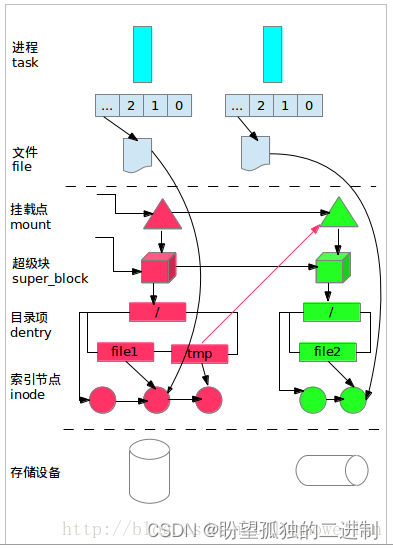
图1
三、函数调用关系
图2描述了文件系统初始化过程中主要的函数调用关系。linux文件系统初始化过程主要分为三个阶段:
1、vfs_caches_init()负责挂载rootfs文件系统,并创建了第一个挂载点目录:'/';
2、rest_init()负责加载initrd文件,扩展VFS树,创建基本的文件系统目录拓扑;
3、init程序负责挂载磁盘文件系统,并将文件系统的根目录从rootfs切换到磁盘文件系统;
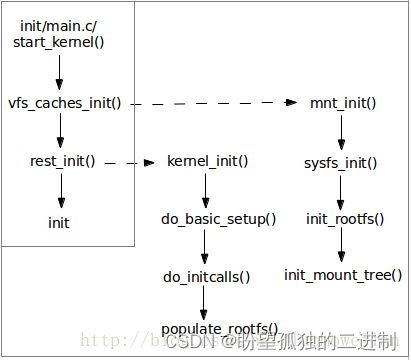
图2
四、总结
linux文件系统初始化过程主要分为三个阶段:挂载rootfs,提供第一个挂载点''/;加载initrd,扩展VFS树;执行init程序,完成linux系统的初始化。下面会详细介绍每个阶段的主要内容。
挂载rootfs文件系统
一、目的
本文主要讲述linux3.10文件系统初始化过程的第一阶段:挂载rootfs文件系统。
rootfs是基于内存的文件系统,所有操作都在内存中完成;也没有实际的存储设备,所以不需要设备驱动程序的参与。基于以上原因,linux在启动阶段使用rootfs文件系统,当磁盘驱动程序和磁盘文件系统成功加载后,linux系统会将系统根目录从rootfs切换到磁盘文件系统。
二、主要函数调用过程
图1描述了挂载rootfs的函数调用关系(图中红色部分),便于后面的分析。
从图中发现,在挂载rootfs前会先挂载sysfs,这样做的原因是确保sysfs能够完整的记录下设备驱动模型。
sysfs_init()完成注册和挂载sysfs文件系统的功能;init_rootfs()负责注册rootfs,init_mount_tree()负责挂载rootfs,并将init_task的命名空间与之联系起来。
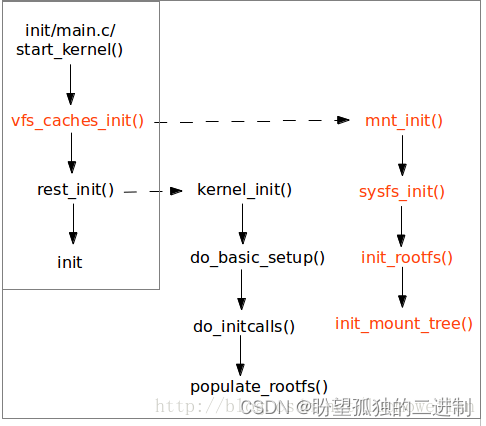
图1
三、linux文件系统初始化
vfs_cache_init()首先建立并初始化目录hash表dentry_hashtable和索引节点hash表inode_hashtable;然后设置内核可以打开的最大文件数;最后调用mnt_init()完成sysfs和rootfs文件系统的注册和挂载。
linux使用哈希表存储目录和索引节点,以提高目录和索引节点的查找效率;dentry_hashtable是目录哈希表,inode_hashtable是索引节点哈希表。
四、挂载sysfs文件系统
sysfs用来记录和展示linux驱动模型,sysfs先于rootfs挂载是为全面展示linux驱动模型做好准备。
mnt_init()调用sysfs_init()注册并挂载sysfs文件系统,然后调用kobject_create_and_add()创建"fs"目录。
下面详细介绍sysfs文件系统的挂载过程:
1、sysfs_init()调用register_filesystem()注册文件系统类型sysfs_fs_type,并加入到全局单链表file_systems中。
173 err = register_filesystem(&sysfs_fs_type);
174 if (!err) {
175 sysfs_mnt = kern_mount(&sysfs_fs_type);
176 if (IS_ERR(sysfs_mnt)) {
177 printk(KERN_ERR "sysfs: could not mount!\n");
178 err = PTR_ERR(sysfs_mnt);
179 sysfs_mnt = NULL;
180 unregister_filesystem(&sysfs_fs_type);
181 goto out_err;
182 }
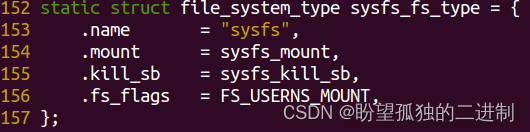
sysfs_fs_type定义如下,.mount成员函数负责超级块、根目录和索引节点的创建和初始化工作。
2、sysfs_init()->kern_mount()->vfs_kern_mount()创建并初始化struct mount挂载点,并使用全局变量sysfs_mnt保存该挂载点的挂载项(mnt成员)。
3、kern_mount()调用sysfs_fs_type的.mount成员sysfs_mount()创建并初始化超级块、根目录’/'、根目录的索引节点等数据结构;并且把超级块添加到全局单链表super_blocks中,把索引节点添加到hash表inode_hashtable和超级块的inode链表中。
4、目前,我们可以得出一个重要结论:kern_mount()主要完成挂载点、超级块、根目录和索引节点的创建和初始化操作,可以看成是一个原子操作,这个函数以后会频繁使用。
796 mnt->mnt.mnt_root = root;
797 mnt->mnt.mnt_sb = root->d_sb;
798 mnt->mnt_mountpoint = mnt->mnt.mnt_root;
799 mnt->mnt_parent = mnt;
5、mnt_init()调用kobject_create_and_add()创建"fs"目录。
通过以上步骤,sysfs文件系统在VFS中的视图如图2所示:挂载点指向超级块和根目录;超级块处在super_blocks单链表中,并且链接起所有属于该文件系统的索引节点;根目录’/'和目录"fs"指向各自的索引节点;为了提高查找效率,索引节点保存在hash表中。
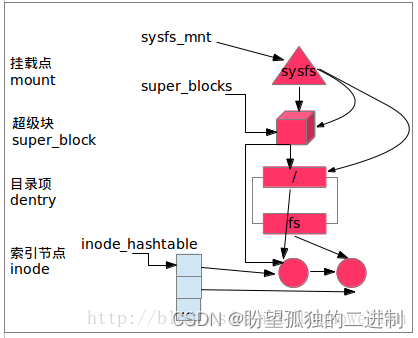
图2
五、挂载rootfs文件系统
mnt_init()调用init_rootfs()注册rootfs,然后调用init_mount_tree()挂载rootfs。
下面详细介绍rootfs文件系统的挂载过程:
1、mnt_init()调用init_rootfs()注册文件系统类型rootfs_fs_type,并加入到全局单链表file_systems中。rootfs_fs_type定义如下,mount成员函数负责超级块、根目录和索引节点的建立和初始化工作。
static struct file_system_type rootfs_fs_type = {
.name = "rootfs",
.mount = rootfs_mount,
.kill_sb = kill_litter_super,
};
2、init_mount_tree()调用vfs_kern_mount()挂载rootfs文件系统,详细的挂载过程与sysfs文件系统类似,不再赘述。
3、init_mount_tree()调用create_mnt_ns()创建命名空间,并设置该命名空间的挂载点为rootfs的挂载点,同时将rootfs的挂载点链接到该命名空间的双向链表中。
4、init_mount_tree()设置init_task的命名空间,同时调用set_fs_pwd()和set_fs_root()设置init_task任务的当前目录和根目录为rootfs的根目录’/'。
通过以上分析,我们发现sysfs和rootfs的区别在于:虽然系统同时挂载了sysfs和rootfs文件系统,但是只有rootfs处于init_task进程的命名空间内,也就是说系统当前实际使用的是rootfs文件系统。
此时,sysfs和rootfs在VFS中的视图如图3所示:为了突出主要关系,省略了挂载点指向超级块和根目录。
从图中看出,rootfs处于进程的命名空间中,并且进程的fs_struct数据结构的root和pwd都指向了rootfs的根目录’/‘,所以用户实际使用的是rootfs文件系统。另外,rootfs为VFS提供了’/'根目录,所以文件操作和文件系统的挂载操作都可以在VFS上进行了。
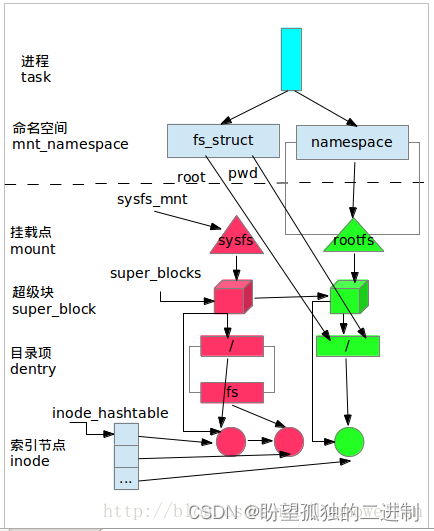
图3
六、总结!
linux文件系统在初始化时,同时挂载了sysfs和rootfs文件系统,但是只有rootfs处于进程的命名空间中,且进程的root目录和pwd目录都指向rootfs的根目录。至此,linux的VFS已经准备好了根目录(rootfs的根目录’/'),此时用户可以使用系统调用对VFS树进行扩展。
让我们来分析一下sysfs初始化的代码
《vfs学习-sysfs》
https://blog.csdn.net/verdicty/article/details/44651035
/*
* 一、说明
* sysfs与设备、驱动相关。系统将驱动的层级结构通过sysfs以
* 文件系统的形式展现给用户。在驱动方面涉及到的概念有kobject,
* kset,bus,device_driver,device,class等等;而在文件系统方面
* 涉及到的概念有inode,dentry,super_block,vfsmount等虚拟文件
* 系统方面的内容。既然sysfs也是一种文件系统,就必须提供虚拟
* 文件系统相关的数据结构。
* 各方面内容:用户-访问文件系统->VFS-访问实际文件系统->sysfs
* --映射到->driver体系
*/
/*
* 二、sysfs文件系统的加载
*/
//sysfs的mount//
/*
* 调用过程
* start_kernel(/init/main.c)->vfs_caches_init(/fs/dcache.c)->
* mnt_init(/fs/namespace.c)->sysfs_init
* 在start_kernel中两个函数是文件系统初始化相关的:
* vfs_caches_init_early(),vfs_caches_init(totalram_pages)
*/
/*
* /fs/sysfs/mount.c
* 几个全局变量
*/
/*
* 静态,本文件内函数用,vfsmount代表一个加载的文件系统
* 这是sysfs的源头,sysfs_mnt 可找到其根dentry,进而可找到inode,超级块等结构
* 生成这个结构的过程就是生成inode dentry super_block并使其相关联的过程。
*/
static struct vfsmount *sysfs_mnt;
//sysfs的sysfs_dirent缓存cache
struct kmem_cache *sysfs_dir_cachep;
//sysfs的super_block默认操作
static const struct super_operations sysfs_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.evict_inode = sysfs_evict_inode,
};
/*
* sysfs的根sysfs_dirent结构,此结构是联系kobject层级体系和vfs层级体系的桥梁
* 而sysfs_root对应的就是vfs中的根,即/sys/目录
*/
struct sysfs_dirent sysfs_root = {
.s_name = "",
.s_count = ATOMIC_INIT(1),
.s_flags = SYSFS_DIR | (KOBJ_NS_TYPE_NONE << SYSFS_NS_TYPE_SHIFT),
.s_mode = S_IFDIR | S_IRUGO | S_IXUGO,
.s_ino = 1,
};
/*
* sysfs的type,用来注册sysfs文件系统的全局变量,静态的,本文件内函数使用维护
*/
static struct file_system_type sysfs_fs_type = {
.name = "sysfs",
.mount = sysfs_mount,
.kill_sb = sysfs_kill_sb,
}
//初始化sysfs///
目标:生成static struct vfsmount *sysfs_mnt//
int __init sysfs_init(void)
{
int err = -ENOMEM;
//cache缓存申请
sysfs_dir_cachep = kmem_cache_create("sysfs_dir_cache",
sizeof(struct sysfs_dirent),
0, 0, NULL);
if (!sysfs_dir_cachep)
goto out;
/*
* 备用存储设备初始化(bdi),用来存储数据的设备
*/
err = sysfs_inode_init();
if (err)
goto out_err;
/*
* 注册文件系统,就是将sysfs_fs_type对应的文件系统加入到内核全局变量
* file_system中,它定义在:/fs/filesystems.c文件中,是个静态的,只本文件
* 相关函数维护和访问
* static struct file_system_type *file_systems;
*
* 传入的参数是静态全局变量sysfs_fs_type
*/
err = register_filesystem(&sysfs_fs_type);
if (!err) {
/*
* /include/linux/fs.h中定义:
* #define kern_mount(type) kern_mount_data(type, NULL)
* 本函数最终目的是将文件系统的 vfsmount结构 sysfs_mnt存储起来
* 核心就是取到这个结构的值,以备后用
*
* 传入的参数是静态全局变量sysfs_fs_type
*/
sysfs_mnt = kern_mount(&sysfs_fs_type);
if (IS_ERR(sysfs_mnt)) {
printk(KERN_ERR "sysfs: could not mount!\n");
err = PTR_ERR(sysfs_mnt);
sysfs_mnt = NULL;
unregister_filesystem(&sysfs_fs_type);
goto out_err;
}
} else
goto out_err;
out:
return err;
out_err:
kmem_cache_destroy(sysfs_dir_cachep);
sysfs_dir_cachep = NULL;
goto out;
}
/mount vfsmount生成
/*
* /fs/namespace.c中定义:
* 调用vfs_kern_mount进一步处理
*
* 传入的参数是静态全局变量sysfs_fs_type,data=NULL
*/
struct vfsmount *kern_mount_data(struct file_system_type *type, void *data)
{
struct vfsmount *mnt;
mnt = vfs_kern_mount(type, MS_KERNMOUNT, type->name, data);
if (!IS_ERR(mnt)) {
real_mount(mnt)->mnt_ns = MNT_NS_INTERNAL;
}
return mnt;
}
/*
* vfsmount与mount结构:前者是后者的一个成员,都有dentry结构 vfsmount.dentry
* mount.mnt_mountpoint都指向子文件系统(sysfs)的根dentry
*
* /fs/namespace.c中定义
*参数:
* type=sysfs_fs_type
* flags=MS_KERNMOUNT
* name= type->name=sysfs_fs_type->name="sysfs"
* data=NULL
*
* 本函数是取得struct vfsmount结构。但需要加载sysfs以取得sysfs的根dentry.
* 将根dentry与要返回的vfsmount联系起来。
* 申请了一个mount,它体内有一个内嵌的vfsmount(不是指针型的),回头将它返回
* 也就是说返回的vfsmount是mount的一个成员结构,通过vfsmount就能找到mount
*/
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
//申请一个struct mount结构
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & MS_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
//得到本文件系统的根dentry
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
free_vfsmnt(mnt);
return ERR_CAST(root);
}
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
br_write_lock(&vfsmount_lock);
//mount结构通过mnt_instance连接到超级块的s_mounts字段
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
br_write_unlock(&vfsmount_lock);
return &mnt->mnt;
}
/*
* /fs/super.c中定义
* 参数:
* type=sysfs_fs_type
* flags=MS_KERNMOUNT
* name= type->name=sysfs_fs_type->name="sysfs"
* data=NULL
*
* 函数功能:
* 根据type加载文件系统并返回它的root dentry
*/
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
char *secdata = NULL;
int error = -ENOMEM;
if (data && !(type->fs_flags & FS_BINARY_MOUNTDATA)) {
secdata = alloc_secdata();
if (!secdata)
goto out;
error = security_sb_copy_data(data, secdata);
if (error)
goto out_free_secdata;
}
/*
* 调用type的mount函数,.
* 即sysfs_fs_type->mount=sysfs_mount()[/fs/sysfs/mount.c]
* 整个过程像是这样:对VFS来说,它只要知道文件系统相关信息,并存储起来
* 且vfs调用自己定义好的接口来实现mount(其它操作也一样),具体功能
* 由具体的文件系统自己定义,只要接口保持一致就行。
* 对sysfs来说,它提供具体相关结构的生成,还得靠自己的函数。这些结构
* 包括dentry..super_block..mount..vfsmount等,只是把这些信息放在了
* 文件系统类型sysfs_fs_type中,等待VFS体系来调用罢了。说白了自己让别人
* 管自己,最后还是自己劳动。
*/
root = type->mount(type, flags, name, data);
if (IS_ERR(root)) {
error = PTR_ERR(root);
goto out_free_secdata;
}
sb = root->d_sb;
BUG_ON(!sb);
WARN_ON(!sb->s_bdi);
WARN_ON(sb->s_bdi == &default_backing_dev_info);
sb->s_flags |= MS_BORN;
error = security_sb_kern_mount(sb, flags, secdata);
if (error)
goto out_sb;
......
up_write(&sb->s_umount);
free_secdata(secdata);
return root;
out_sb:
dput(root);
deactivate_locked_super(sb);
out_free_secdata:
free_secdata(secdata);
out:
return ERR_PTR(error);
}
/*
* /fs/sysfs/mount.c
*
* fs_type=sysfs_fs_type
* flags=MS_KERNMOUNT
* dev_name= type->name=sysfs_fs_type->name="sysfs"
* data=NULL
*
* 函数功能:
* 加载sysfs文件系统,并返回sysfs的root dentry
* sb = sget取得super_block
* sysfs_fill_super(sb填充sb,并组织与sb相关的根inode dentry以及与
* 根dirent sysfs_root关联起来
* 最后将根dentry返回
*/
static struct dentry *sysfs_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
struct sysfs_super_info *info;
enum kobj_ns_type type;
struct super_block *sb;
int error;
info = kzalloc(sizeof(*info), GFP_KERNEL);
if (!info)
return ERR_PTR(-ENOMEM);
//命名空间相关
for (type = KOBJ_NS_TYPE_NONE; type < KOBJ_NS_TYPES; type++)
info->ns[type] = kobj_ns_grab_current(type);
//查询取得,或新创建一个super_block
sb = sget(fs_type, sysfs_test_super, sysfs_set_super, flags, info);
if (IS_ERR(sb) || sb->s_fs_info != info)
free_sysfs_super_info(info);
if (IS_ERR(sb))
return ERR_CAST(sb);
if (!sb->s_root) {
//新创建的sb,s_root肯定为空,则需要填充super_block
error = sysfs_fill_super(sb, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(sb);
return ERR_PTR(error);
}
sb->s_flags |= MS_ACTIVE;
}
return dget(sb->s_root);
}
//超级块生成
/*
* 在/fs/super.c中定义:
* fs_type=sysfs_fs_type
* sysfs_test_super
* sysfs_set_super
* flags=MS_KERNMOUNT
* data=NULL
*
* 函数功能:
* 在type的super_blocks列表中查找或新创建一个属于type的super_block
*/
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags,
void *data)
{
struct super_block *s = NULL;
struct hlist_node *node;
struct super_block *old;
int err;
retry:
spin_lock(&sb_lock);
if (test) {
hlist_for_each_entry(old, node, &type->fs_supers, s_instances) {
//test不断失败,直到循环结束,old是迭代指针,列表是type->fs_supers
if (!test(old, data))
continue;
if (!grab_super(old))
goto retry;
if (s) {
up_write(&s->s_umount);
destroy_super(s);
s = NULL;
}
down_write(&old->s_umount);
if (unlikely(!(old->s_flags & MS_BORN))) {
deactivate_locked_super(old);
goto retry;
}
return old;
}
}
//新建的话,s肯定是null
if (!s) {
spin_unlock(&sb_lock);
//申请一个空super_block
s = alloc_super(type, flags);
if (!s)
return ERR_PTR(-ENOMEM);
goto retry;
}
//设置好s的数据
err = set(s, data);
if (err) {
spin_unlock(&sb_lock);
up_write(&s->s_umount);
destroy_super(s);
return ERR_PTR(err);
}
//设置type,名称,并添加到全系统全局变量super_blocks中去
s->s_type = type;
strlcpy(s->s_id, type->name, sizeof(s->s_id));
list_add_tail(&s->s_list, &super_blocks);
hlist_add_head(&s->s_instances, &type->fs_supers);
spin_unlock(&sb_lock);
get_filesystem(type);
//内存管理
register_shrinker(&s->s_shrink);
return s;
}
/*
* 定义在:/fs/sysfs/mount.c
* super_block=申请的那个超级块
* data=NULL
* silent=flags & MS_SILENT ? 1 : 0
*
* 函数功能:
* 给sysfs的super_block填充内容; 根据super_block和sysfs_root这个根dirent
* 生成根dentry root的inode。最终将 super_block sysfs_root root dentry
* inode 关联起来,就是将VFS需要的那几项组织起来。虽然返回super_block,
* 但与super_block相关的内容都处理好了。
*/
static int sysfs_fill_super(struct super_block *sb, void *data, int silent)
{
struct inode *inode;
struct dentry *root;
sb->s_blocksize = PAGE_CACHE_SIZE;
sb->s_blocksize_bits = PAGE_CACHE_SHIFT;
sb->s_magic = SYSFS_MAGIC;
sb->s_op = &sysfs_ops;
sb->s_time_gran = 1;
/* get root inode, initialize and unlock it */
mutex_lock(&sysfs_mutex);
//生成根dentry root的inode
inode = sysfs_get_inode(sb, &sysfs_root);
mutex_unlock(&sysfs_mutex);
if (!inode) {
pr_debug("sysfs: could not get root inode\n");
return -ENOMEM;
}
//根据根inode生成根 dentry
root = d_make_root(inode);
if (!root) {
pr_debug("%s: could not get root dentry!\n",__func__);
return -ENOMEM;
}
root->d_fsdata = &sysfs_root;
sb->s_root = root;
sb->s_d_op = &sysfs_dentry_ops;
return 0;
}
///由全局变量sysfs_dirent sysfs_root生成inode///
/*
* /fs/sysfs/inode.c
* 参数:
* sb=sysfs的那个super_block
* sysfs_dirent=sysfs_root
*
* 函数功能:
* 由sysfs_dirent生成一个inode
* 再看看sysfs_root的定义(/fs/sysfs/mount.c)
* struct sysfs_dirent sysfs_root = {
* .s_name = "",
* .s_count = ATOMIC_INIT(1),
* .s_flags = SYSFS_DIR | (KOBJ_NS_TYPE_NONE << SYSFS_NS_TYPE_SHIFT),
* .s_mode = S_IFDIR | S_IRUGO | S_IXUGO,
* .s_ino = 1,
* };
*/
struct inode * sysfs_get_inode(struct super_block *sb, struct sysfs_dirent *sd)
{
struct inode *inode;
//由一个加载的文件系统获得一个inode,由上可知传进去的s_ino=1
inode = iget_locked(sb, sd->s_ino);
if (inode && (inode->i_state & I_NEW))
sysfs_init_inode(sd, inode); //初始化这个inode
return inode;
}
/*
* 静态全局变量,inode hash列表,inode_hashtable[hash]是一个相同hash值=hash的列表
*/
static struct hlist_head *inode_hashtable __read_mostly;
/*
* /fs/inode.c:
* 参数:
* sb=sysfs的超级块
* ino=sysfs_root.s_ino=1
*
* 函数功能:
* 从一个加载的文件系统中申请一个inode出来
* 用到静态全局变量inode_hashtable
*/
struct inode *iget_locked(struct super_block *sb, unsigned long ino)
{
struct hlist_head *head = inode_hashtable + hash(sb, ino);
struct inode *inode;
//@@@@第一次锁申请
spin_lock(&inode_hash_lock);
//1号inode还没生成,当然找不到了
inode = find_inode_fast(sb, head, ino);
//@@@@第一次锁释放
spin_unlock(&inode_hash_lock);
if (inode) {
wait_on_inode(inode);
return inode;
}
//生成1号inode,申请inode空间并初始化
inode = alloc_inode(sb);
if (inode) {
struct inode *old;
//@@@@第二次锁申请
spin_lock(&inode_hash_lock);
/*
* 因为在两次加锁中间可能有别人申请了本号码的inode,
* 所以再查找一次
*/
old = find_inode_fast(sb, head, ino);
if (!old) {
//如果没找到,就用我们刚才申请的的inode
inode->i_ino = ino;
spin_lock(&inode->i_lock);
//设置状态
inode->i_state = I_NEW;
hlist_add_head(&inode->i_hash, head);
spin_unlock(&inode->i_lock);
inode_sb_list_add(inode);
spin_unlock(&inode_hash_lock);
/* Return the locked inode with I_NEW set, the
* caller is responsible for filling in the contents
*/
return inode;
}
/*
* Uhhuh, somebody else created the same inode under
* us. Use the old inode instead of the one we just
* allocated.
* 执行到这里说明有别人在两锁中间申请了本号码的inode
* 则把我们申请的释放掉,然后用别人的那个(old)
*/
spin_unlock(&inode_hash_lock);
destroy_inode(inode);
inode = old;
wait_on_inode(inode);
}
return inode;
}
/*
* 在fs/sysfs/inode.c中:
*/
static const struct address_space_operations sysfs_aops = {
.readpage = simple_readpage,
.write_begin = simple_write_begin,
.write_end = simple_write_end,
};
static struct backing_dev_info sysfs_backing_dev_info = {
.name = "sysfs",
.ra_pages = 0, /* No readahead */
.capabilities = BDI_CAP_NO_ACCT_AND_WRITEBACK,
};
static const struct inode_operations sysfs_inode_operations ={
.permission = sysfs_permission,
.setattr = sysfs_setattr,
.getattr = sysfs_getattr,
.setxattr = sysfs_setxattr,
};
/*
* 在fs/sysfs/inode.c中:
* 参数
* sd=sysfs_root
* inode=与sysfs_root对应的1号inode
* 功能:初始化inode
* 再看看sysfs_root的定义(/fs/sysfs/mount.c)
* struct sysfs_dirent sysfs_root = {
* .s_name = "",
* .s_count = ATOMIC_INIT(1),
* .s_flags = SYSFS_DIR | (KOBJ_NS_TYPE_NONE << SYSFS_NS_TYPE_SHIFT),
* .s_mode = S_IFDIR | S_IRUGO | S_IXUGO,
* .s_ino = 1,
* };
*/
static void sysfs_init_inode(struct sysfs_dirent *sd, struct inode *inode)
{
struct bin_attribute *bin_attr;
/*
* i_private字段存储inode与文件系统相关的信息,在sysfs中存储的是sysfs_dirent结构
*/
inode->i_private = sysfs_get(sd);
inode->i_mapping->a_ops = &sysfs_aops;
inode->i_mapping->backing_dev_info = &sysfs_backing_dev_info;
inode->i_op = &sysfs_inode_operations;
set_default_inode_attr(inode, sd->s_mode);
sysfs_refresh_inode(sd, inode);
/* initialize inode according to type */
switch (sysfs_type(sd)) {
case SYSFS_DIR:
/*
* sysfs_root的s_flags是SYSFS_DIR,所以i_op和i_fop指向相应位置
*/
inode->i_op = &sysfs_dir_inode_operations;
inode->i_fop = &sysfs_dir_operations;
break;
case SYSFS_KOBJ_ATTR:
inode->i_size = PAGE_SIZE;
inode->i_fop = &sysfs_file_operations;
break;
case SYSFS_KOBJ_BIN_ATTR:
bin_attr = sd->s_bin_attr.bin_attr;
inode->i_size = bin_attr->size;
inode->i_fop = &bin_fops;
break;
case SYSFS_KOBJ_LINK:
inode->i_op = &sysfs_symlink_inode_operations;
break;
default:
BUG();
}
unlock_new_inode(inode);
}
/由sysfs_root dirent对应的inode生成dentry///
/*
* /fs/dcache.c:
* 参数:sysfs_root dirent对应的inode
* 功能:生成对应的dentry
*/
struct dentry *d_make_root(struct inode *root_inode)
{
struct dentry *res = NULL;
if (root_inode) {
//name变量="/"
static const struct qstr name = QSTR_INIT("/", 1);
//在sb中申请出一个dentry
res = __d_alloc(root_inode->i_sb, &name);
if (res)
//用inode信息初始化,使之与root_inode关联
d_instantiate(res, root_inode);
else
iput(root_inode);
}
return res;
}
/*
* /fs/dcache.c:
* 从文件系统申请一个dentry
*/
struct dentry *__d_alloc(struct super_block *sb, const struct qstr *name)
{
struct dentry *dentry;
char *dname;
//内存申请
dentry = kmem_cache_alloc(dentry_cache, GFP_KERNEL);
if (!dentry)
return NULL;
//名称串内存申请
dentry->d_iname[DNAME_INLINE_LEN-1] = 0;
if (name->len > DNAME_INLINE_LEN-1) {
dname = kmalloc(name->len + 1, GFP_KERNEL);
if (!dname) {
kmem_cache_free(dentry_cache, dentry);
return NULL;
}
} else {
dname = dentry->d_iname;
}
//名字复制
dentry->d_name.len = name->len;
dentry->d_name.hash = name->hash;
memcpy(dname, name->name, name->len);
dname[name->len] = 0;
/* Make sure we always see the terminating NUL character */
smp_wmb();
//名字指针赋值
dentry->d_name.name = dname;
//下面是各种初始化
dentry->d_count = 1;
dentry->d_flags = 0;
spin_lock_init(&dentry->d_lock);
seqcount_init(&dentry->d_seq);
dentry->d_inode = NULL;
dentry->d_parent = dentry;
dentry->d_sb = sb;
dentry->d_op = NULL;
dentry->d_fsdata = NULL;
INIT_HLIST_BL_NODE(&dentry->d_hash);
INIT_LIST_HEAD(&dentry->d_lru);
INIT_LIST_HEAD(&dentry->d_subdirs);
INIT_HLIST_NODE(&dentry->d_alias);
INIT_LIST_HEAD(&dentry->d_u.d_child);
d_set_d_op(dentry, dentry->d_sb->s_d_op);
this_cpu_inc(nr_dentry);
return dentry;
}
/*
* 最终生成了使vfsmount sysfs_mnt=mount.mnt这个全局变量得到赋值后
* 以后要找sysfs便可从sysfs_mnt找。因为它是静态的,所以它的值是由
* 模块内函数维护的。VFS对一个文件系统要求的inode_root,dentry_root,
* super_block等都可以从这个变量找到。
* 具体的inode和dentry是在sysfs_lookup时才生成的,没有事先生成。先
* 操作dirent的层次,最后返回基于dirent的dentry
*
*
*/
/*
* 三、设备驱动模块kobject等
*/
/*
* 关系:
* kset:
* 向下:指向子节点链表 kset->list
* 自己:kobj对应,因此kobject不是个指针,所以本kobj能定位到自己的kset
* 向上: kobj->parent,kobj->kset(父级kset)
* kobject:
* 向上: kobject->parent
* 横向: entry链入兄弟链表,进入父kset的list字段
* sysfs_dirent:
* 向上: parent,
* 向下: s_dir.children(只能是目录)
* 横向: s_rb
*
*
* kobject->sd 指向对应的sysfs_dirent结构
* sysfs_dirent->s_ino指向对应的inode号
* inode->i_private存储其对应的sysfs_dirent结构
* dentry->d_fsdata指向对应的sysfs_dirent结构
* inode->i_dentry指向对应dentry列表
* dentry->d_inode指向对应的inode
*
* kset{kobject}
* ^ 7
* |/
* v
* kobject---->sysfs_dirent<------>inode
* ^1
* |
* v n
* sysfs_dirent<------dentry
*/
/*
* kset 是管理kobject的集合,自身体内含有一个kobject,是kset所包含
* 子kobject集合的父亲。kset还可以包含其它的kset(kset->kobj->kset?)
*/
struct kset {//在sysfs目录结构中,kset是个目录
struct list_head list;//子层kobject链表
spinlock_t list_lock;
struct kobject kobj;//本层kobject,代表sysfs目录结构中的自己
const struct kset_uevent_ops *uevent_ops;
};
struct kobject {
const char *name;//设备名
struct list_head entry;//链入kset(兄弟链)
struct kobject *parent;//父对象
struct kset *kset;//本对象所属的kset(父集链)
struct kobj_type *ktype;//对象类型描述符
/*
* dentry,inode相关字段,组成sysfs文件系统层级关系
* 每个sysfs节点有一个sysfs_dirent结构
*/
struct sysfs_dirent *sd;
struct kref kref;//引用计数
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;//说明本节点在sysfs中有对应
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
/*
* kobject与vfs关联
* inode->i_private存储其对应的sysfs_dirent结构
* sysfs_dirent.s_ino对应inode节点号
* 向上有parent,向下(只能是目录)有s_dir.children
* 横向兄弟有s_rb
* 这样就形成了一个层级结构
*/
struct sysfs_dirent {
atomic_t s_count;
atomic_t s_active;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
struct sysfs_dirent *s_parent;//父节点
const char *s_name;
//兄弟节点,链入父节点的s_dir.children字段
struct rb_node s_rb;
union {
struct completion *completion;
struct sysfs_dirent *removed_list;
} u;
const void *s_ns; /* namespace tag */
unsigned int s_hash; /* ns + name hash */
union {
struct sysfs_elem_dir s_dir;//目录级联用
struct sysfs_elem_symlink s_symlink;
struct sysfs_elem_attr s_attr;
struct sysfs_elem_bin_attr s_bin_attr;
};
/*
* s_flags表明在sysfs中的类型
* SYSFS_DIR,SYSFS_KOBJ_ATTR, SYSFS_KOBJ_BIN_ATTR,SYSFS_KOBJ_LINK
*/
unsigned short s_flags;
umode_t s_mode;
unsigned int s_ino;//对应的inode节点id号
struct sysfs_inode_attrs *s_iattr;
};
/*
* sysfs_dirent与dentry的关联,dentry的层次与kobject相同
* kobject形成设备、驱动层次,而dentry负责在stsfs中将这个
* 层次以文件的形式展示出来
* 在v3.6.2/fs/sysfs/inode.c中
* sysfs_init_inode(struct sysfs_dirent *sd, struct inode *inode)
* 根据sysfs_dirent生成inode
*/
dentry->d_fsdata是void指针,指向sysfs_dirent
struct kobj_type {
void (*release)(struct kobject *kobj);//资源释放
const struct sysfs_ops *sysfs_ops;//操作
struct attribute **default_attrs;//默认属性
const struct kobj_ns_type_operations *(*child_ns_type)(struct kobject *kobj);
const void *(*namespace)(struct kobject *kobj);
};
struct sysfs_ops {
//用户读取数据
ssize_t (*show)(struct kobject *, struct attribute *,char *);
//用户写入数据
ssize_t (*store)(struct kobject *,struct attribute *,const char *, size_t);
const void *(*namespace)(struct kobject *, const struct attribute *);
};
//在http://lxr.linux.no/linux+v3.6.2/include/linux/kobject.h中:
extern const struct sysfs_ops kobj_sysfs_ops;
//在http://lxr.linux.no/linux+v3.6.2/lib/kobject.c中:
const struct sysfs_ops kobj_sysfs_ops = {
.show = kobj_attr_show,
.store = kobj_attr_store,
};
struct attribute {
const char *name;//sysfs目录中的文件名
umode_t mode;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
bool ignore_lockdep:1;
struct lock_class_key *key;
struct lock_class_key skey;
#endif
};
/*
* 每个bus_type对应/sys/bus下一个子目录,如/sys/bus/pci
* 每个子目录下有两个目录devices,drivers; 前者表示总线上所有设备;
* 后者表示与该总线相"关联"的所有驱动程序。另外就是几个处理函数。
*
* 一些结构:
* bus_type
->device *dev_root;
* device
->device*parent指向父设备
->kobj
->type设备类型
->bus总线
->device_driver *driver申请本结构的驱动程序
->class设备的class
* device_driver
->bus_type *bus指向bus
* class
->dev_kobj代表class链入层级关系
*/
struct bus_type {//系统总线结构
const char *name;//名称
const char *dev_name;//设备名
struct device *dev_root;//默认根设备
struct bus_attribute *bus_attrs;//默认总线属性
struct device_attribute *dev_attrs;//总线上默认设备属性
struct driver_attribute *drv_attrs;//总线上默认设备驱动属性
int (*match)(struct device *dev, struct device_driver *drv);
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
int (*probe)(struct device *dev);
int (*remove)(struct device *dev);
void (*shutdown)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
const struct dev_pm_ops *pm;
struct iommu_ops *iommu_ops;
struct subsys_private *p;//驱动抽象中:bus私有数据
};
/*
* http://lxr.linux.no/linux+v3.6.2/drivers/base/base.h中:
* subsys_private,driver_private,device_private
*/
struct subsys_private {
struct kset subsys;//回指定义本subsys的kset
struct kset *devices_kset;//device目录
struct list_head interfaces;
struct mutex mutex;
struct kset *drivers_kset;//driver目录?
struct klist klist_devices;//用来遍历devices_kset
struct klist klist_drivers;//用来遍历drivers_kset
//本bus有事件的话,就会通知本链上函数
struct blocking_notifier_head bus_notifier;
unsigned int drivers_autoprobe:1;
struct bus_type *bus;//本结构所相关的bus_type
struct kset glue_dirs;
struct class *class;//本结构相关的class
};
struct driver_private {
struct kobject kobj;
struct klist klist_devices;
struct klist_node knode_bus;
struct module_kobject *mkobj;
struct device_driver *driver;
};
struct device_private {
struct klist klist_children;
struct klist_node knode_parent;
struct klist_node knode_driver;
struct klist_node knode_bus;
struct list_head deferred_probe;
void *driver_data;
struct device *device;
};
/*
* kset代表一个目录,它体内的kobject与sysfs关联
* 子kobject代表sysfs中的一个文件
* subsys_private与bus对应,subsys_private体内有两个子kset代表两个子目录
* devices与drivers。
* device_private与device结构对应,而device体内有kobject,代表一个设备
* driver_private与device_driver对应,driver_private有kobject代表一个驱动
*
* 分了3类东西,
* 第1类在include/linux/kobject.h中,是kset,kobject,sysfs_dirent(与sysfs关联)
* 第2类在include/linux/device.h中, 是bus_type,device,device_driver,class
* 第3类在drivers/base/base.h中,是subsys_private,driver_private,device_private
* 1在抽象,2是设备,3是驱动
* kset含有kobject:
->kobj 本层
->list 子层
bus的subsys_private有两个kset
->devices_kset 总线上的设备集合
->drivers_kset 总线相关的驱动集合
device有个kobject
->kobj 本设备对象的kobject
driver_private有个kobject
->kobj 本驱动对象的kobject
*
*/
/*
* 二、过程
*
* 一些全局变量
* /drivers/base/core.c:
struct kset *devices_kset;系统内所有设备,对应/sys/devices/
/drivers/base/bus.c:
这里的两个是静态的,说明只在本文件中有效,也就是只有用本文件中的函数
才能访问。
static struct kset *bus_kset;系统内所有总线,对应/sys/bus/
static struct kset *system_kset;所有子系统,对应/sys/devices/system
start_kernel->rest_init-创建进程->kernel_init(pid=1)->do_basic_setup
->driver_init[v3.6.2/drivers/base/init.c]->buses_init
实际上在driver_init时就涉及许多设备驱动相关的初始化
*/
void __init driver_init(void)
{
devtmpfs_init();
devices_init();//设备初始化
buses_init();//这就是总线初始化
classes_init();
firmware_init();
hypervisor_init();
platform_bus_init();
cpu_dev_init();
memory_dev_init();
}
/*
* /sys/是sysfs的根,下面的函数就是在根下放几个目录:/sys/devices/,/sys/dev/,
* /sys/dev/block/和/sys/dev/char/这几个目录都是"设备(device)相关"的。
*/
int __init devices_init(void)
{
devices_kset = kset_create_and_add("devices", &device_uevent_ops, NULL);
if (!devices_kset)
return -ENOMEM;
dev_kobj = kobject_create_and_add("dev", NULL);
if (!dev_kobj)
goto dev_kobj_err;
sysfs_dev_block_kobj = kobject_create_and_add("block", dev_kobj);
if (!sysfs_dev_block_kobj)
goto block_kobj_err;
sysfs_dev_char_kobj = kobject_create_and_add("char", dev_kobj);
if (!sysfs_dev_char_kobj)
goto char_kobj_err;
return 0;
char_kobj_err:
kobject_put(sysfs_dev_block_kobj);
block_kobj_err:
kobject_put(dev_kobj);
dev_kobj_err:
kset_unregister(devices_kset);
return -ENOMEM;
}
/*
* 与上面函数类似,此函数功能是创添加了/sys/bus/和/sys/devices/system/
*/
int __init buses_init(void)
{
//最后一个参数是parent_kobj,就是父节点的kobject,null就直接挂根上/sys/bus/
bus_kset = kset_create_and_add("bus", &bus_uevent_ops, NULL);
if (!bus_kset)
return -ENOMEM;
//父节点为devices_kset->kobj,所以是在/sys/devices/下挂着
system_kset = kset_create_and_add("system", NULL, &devices_kset->kobj);
if (!system_kset)
return -ENOMEM;
return 0;
}
/*
* 顺便提下subsys_system_register函数,在/drivers/base/bus.c中有一句:
* EXPORT_SYMBOL_GPL(subsys_system_register);说明它是被其它模块调用的
* 一个subsys跟一个总线相关。所以此函数调用bus_register来注册一种类型
* 的总线bus_type
* int subsys_system_register(struct bus_type *subsys,
* const struct attribute_group **groups)
* 子系统没理解好,子系统注册时用的就是bus_type,一个bus就是
* 一个子系统,一个子系统又可包含更广泛的概念?看代码好像是注册一个
* subsystem就是注册一个bus,因为调用了bus_register
*/
添加dir///
/*
* 添加kobject对应就是在sysfs添加一个目录,即/sys/xxx/,用函数:
* 在v3.6.2/lib/kobject.c:
* kset_create_and_add->kset_register->kobject_add_internal
* 在kset_create_and_add里会创建一个kset并将它与父级kobject链起来。然后
* 再调用kset_register将本kobject加入sysfs并发送通知事件。
*/
static int kobject_add_internal(struct kobject *kobj)
{
int error = 0;
struct kobject *parent;
if (!kobj)return -ENOENT;
if (!kobj->name || !kobj->name[0]) {
return -EINVAL;
}
//父级kobject引用++,父kobj可能不存在
parent = kobject_get(kobj->parent);
//若kset存在且父节点没取到,再从kset里取一次
if (kobj->kset) {
if (!parent)
parent = kobject_get(&kobj->kset->kobj);
kobj_kset_join(kobj);
kobj->parent = parent;
}
......
error = create_dir(kobj);
if (error) {
kobj_kset_leave(kobj);
kobject_put(parent);
kobj->parent = NULL;
......
} else
kobj->state_in_sysfs = 1;
return error;
}
/*
* 从create_dir这个函数开始就进入了sysfs流程
*/
static int create_dir(struct kobject *kobj)
{
int error = 0;
error = sysfs_create_dir(kobj);
if (!error) {
error = populate_dir(kobj);
if (error)
sysfs_remove_dir(kobj);
}
return error;
}
/*
* 在v3.6.2/fs/sysfs/dir.c中:
* int sysfs_create_dir(struct kobject * kobj)
*
* sysfs_create_dir - create a directory for an object.
* @kobj: object we're creating directory for.
* /sys/ 目录是根,对应的dirent是变量sysfs_root,定义在
* /fs/sysfs/mount.c#L35
* struct sysfs_dirent sysfs_root = {
* .s_name = "",
* .s_count = ATOMIC_INIT(1),
* .s_flags = SYSFS_DIR | (KOBJ_NS_TYPE_NONE << SYSFS_NS_TYPE_SHIFT),
* .s_mode = S_IFDIR | S_IRUGO | S_IXUGO,
* .s_ino = 1,
* };
* sysfs的级联体系是基于dirent的,设备驱动模型的级联体系是基于kobjet和kset的。
* 在驱动那边kobject和kset的层级被组织好了。
* 当需要"显示"到sysfs时,就调用sysfs_create_dir类似的sysfs函数来创建目录(或文件)
* 如果一个kobject父级为空,说明它是最顶端的,即/sys/下的,把它的父级dirent设置
* 为sysfs_root
*
*
* 而dentry的root("/"目录)是VFS的d_make_root(inode)生成的(/fs/dcache.c),而这个
* inode也是根据sysfs_root生成的。
*
* 硬件<---设备驱动体系----sysfs体系----VFS体系--->用户:
* kobject -- dirent -- dentry(动态生成)
* 设备驱动层级: 以kobject为基础,最上层kobject是几个全局变量
* 如devices_set,bus_set,system_set等
* sysfs层级:以dirent为基础,最上层是sysfs_root,全局变量
* VFS层级:以dentry为基础,最上层的是由sysfs_root和vfs函数d_make_root生成的,像
* 其它文件系统一样,存储在super_block里
*
*
*
*/
int sysfs_create_dir(struct kobject * kobj)
{
enum kobj_ns_type type;
struct sysfs_dirent *parent_sd, *sd;
const void *ns = NULL;
int error = 0;
BUG_ON(!kobj);
//如果父kobj不存在就用根,直接挂到/sys/
if (kobj->parent)
parent_sd = kobj->parent->sd;
else
parent_sd = &sysfs_root;
if (!parent_sd)
return -ENOENT;
if (sysfs_ns_type(parent_sd))
ns = kobj->ktype->namespace(kobj);
type = sysfs_read_ns_type(kobj);
error = create_dir(kobj, parent_sd, type, ns, kobject_name(kobj), &sd);
if (!error)
kobj->sd = sd;
return error;
}
static int create_dir(struct kobject *kobj, struct sysfs_dirent *parent_sd,
enum kobj_ns_type type, const void *ns, const char *name,
struct sysfs_dirent **p_sd)
{
//S_IFDIR表示目录?
umode_t mode = S_IFDIR| S_IRWXU | S_IRUGO | S_IXUGO;
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
int rc;
//申请一个dirent
sd = sysfs_new_dirent(name, mode, SYSFS_DIR);
if (!sd)
return -ENOMEM;
sd->s_flags |= (type << SYSFS_NS_TYPE_SHIFT);
sd->s_ns = ns;
//本节点是个目录,其kobj记录在s_dir成员中(联合体)
sd->s_dir.kobj = kobj;
/* link in */
sysfs_addrm_start(&acxt, parent_sd);
rc = sysfs_add_one(&acxt, sd);//添加
sysfs_addrm_finish(&acxt);
if (rc == 0)
*p_sd = sd;
else
sysfs_put(sd);
return rc;
}
//向父级dirent 添加一个dirent
int sysfs_add_one(struct sysfs_addrm_cxt *acxt, struct sysfs_dirent *sd)
{
int ret;
//添加内部函数
ret = __sysfs_add_one(acxt, sd);
if (ret == -EEXIST) {
......
}
return ret;
}
int __sysfs_add_one(struct sysfs_addrm_cxt *acxt, struct sysfs_dirent *sd)
{
struct sysfs_inode_attrs *ps_iattr;
int ret;
if (!!sysfs_ns_type(acxt->parent_sd) != !!sd->s_ns) {
WARN(1, KERN_WARNING "sysfs: ns %s in '%s' for '%s'\n",
sysfs_ns_type(acxt->parent_sd)? "required": "invalid",
acxt->parent_sd->s_name, sd->s_name);
return -EINVAL;
}
//21位的二元组[ns,name]的hash值(是个UINT)
sd->s_hash = sysfs_name_hash(sd->s_ns, sd->s_name);
//设置父级dirent
sd->s_parent = sysfs_get(acxt->parent_sd);
//本dirent的兄弟链接
ret = sysfs_link_sibling(sd);
if (ret)
return ret;
/* Update timestamps on the parent */
ps_iattr = acxt->parent_sd->s_iattr;
if (ps_iattr) {
struct iattr *ps_iattrs = &ps_iattr->ia_iattr;
ps_iattrs->ia_ctime = ps_iattrs->ia_mtime = CURRENT_TIME;
}
return 0;
}
struct sysfs_elem_dir {
struct kobject *kobj;
unsigned long subdirs;//本目录子目录数
struct rb_root children;//子目录的红黑树
};
//兄弟节点是一个红黑树链接的(rbtree)
static int sysfs_link_sibling(struct sysfs_dirent *sd)
{
//s_dir 是 sysfs_elem_dir 结构
struct rb_node **node = &sd->s_parent->s_dir.children.rb_node;
struct rb_node *parent = NULL;
//如果将被添加的是一个目录,则父目录的子目录数+=1
if (sysfs_type(sd) == SYSFS_DIR)
sd->s_parent->s_dir.subdirs++;
//红黑树遍历,找到合适位置
while (*node) {
struct sysfs_dirent *pos;
int result;
pos = to_sysfs_dirent(*node);
parent = *node;
result = sysfs_sd_compare(sd, pos);
if (result < 0)
node = &pos->s_rb.rb_left;
else if (result > 0)
node = &pos->s_rb.rb_right;
else
return -EEXIST;
}
/* add new node and rebalance the tree */
rb_link_node(&sd->s_rb, parent, node);
rb_insert_color(&sd->s_rb, &sd->s_parent->s_dir.children);
return 0;
}
添加file
/*
* 添加kobject就是往某个"目录"下添加一个"文件"
* v3.6.2/include/linux/device.h#L117
*/
#define bus_register(subsys) \
({ \
static struct lock_class_key __key; \
__bus_register(subsys, &__key); \
})
/*
* 内部函数定义在:
* v3.6.2/drivers/base/bus.c#L923
*/
int __bus_register(struct bus_type *bus, struct lock_class_key *key)
{
int retval;
struct subsys_private *priv;
//申请一个结构
priv = kzalloc(sizeof(struct subsys_private), GFP_KERNEL);
if (!priv)
return -ENOMEM;
//与bus联系起来
priv->bus = bus;
bus->p = priv;
BLOCKING_INIT_NOTIFIER_HEAD(&priv->bus_notifier);
//设置bus的名字,如"USB"
retval = kobject_set_name(&priv->subsys.kobj, "%s", bus->name);
if (retval)
goto out;
/*
* 前面说过,bus_kset指的是/sys/bus/目录; 一个kobj.kset指的是本
* kobj的父级目录,所以下面这句就是本bus的父目录是/sys/bus/,若为
* USB,则最终形成/sys/bus/usb/
* /
priv->subsys.kobj.kset = bus_kset;
priv->subsys.kobj.ktype = &bus_ktype;
priv->drivers_autoprobe = 1;
//此函数上面说过,添加一个kset目录,即添加/sys/bus/usb/
retval = kset_register(&priv->subsys);
if (retval)
goto out;
//为本目录(/sys/bus/usb/)添加一个属性文件
retval = bus_create_file(bus, &bus_attr_uevent);
if (retval)
goto bus_uevent_fail;
//每个总线目录下有个 /devices和/drivers目录
priv->devices_kset = kset_create_and_add("devices", NULL,
&priv->subsys.kobj);
if (!priv->devices_kset) {
retval = -ENOMEM;
goto bus_devices_fail;
}
priv->drivers_kset = kset_create_and_add("drivers", NULL,
&priv->subsys.kobj);
if (!priv->drivers_kset) {
retval = -ENOMEM;
goto bus_drivers_fail;
}
INIT_LIST_HEAD(&priv->interfaces);
__mutex_init(&priv->mutex, "subsys mutex", key);
klist_init(&priv->klist_devices, klist_devices_get, klist_devices_put);
klist_init(&priv->klist_drivers, NULL, NULL);
retval = add_probe_files(bus);
if (retval)
goto bus_probe_files_fail;
retval = bus_add_attrs(bus);
if (retval)
goto bus_attrs_fail;
pr_debug("bus: '%s': registered\n", bus->name);
return 0;
bus_attrs_fail:
remove_probe_files(bus);
bus_probe_files_fail:
kset_unregister(bus->p->drivers_kset);
bus_drivers_fail:
kset_unregister(bus->p->devices_kset);
bus_devices_fail:
bus_remove_file(bus, &bus_attr_uevent);
bus_uevent_fail:
kset_unregister(&bus->p->subsys);
out:
kfree(bus->p);
bus->p = NULL;
return retval;
}
/*
* v3.6.2/drivers/base/bus.c#L127
*/
int bus_create_file(struct bus_type *bus, struct bus_attribute *attr)
{
int error;
if (bus_get(bus)) {
error = sysfs_create_file(&bus->p->subsys.kobj, &attr->attr);
bus_put(bus);
} else
error = -EINVAL;
return error;
}
//v3.6.2/fs/sysfs/file.c#L571
int sysfs_create_file(struct kobject * kobj, const struct attribute * attr)
{
BUG_ON(!kobj || !kobj->sd || !attr);
//kobj是usb目录的那个kobj
return sysfs_add_file(kobj->sd, attr, SYSFS_KOBJ_ATTR);
}
//v3.6.2/fs/sysfs/file.c#L558
int sysfs_add_file(struct sysfs_dirent *dir_sd, const struct attribute *attr,
int type)
{
//dir_sd指的是usb目录
return sysfs_add_file_mode(dir_sd, attr, type, attr->mode);
}
int sysfs_add_file_mode(struct sysfs_dirent *dir_sd,
const struct attribute *attr, int type, umode_t amode)
{
umode_t mode = (amode & S_IALLUGO) | S_IFREG;
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
const void *ns;
int rc;
rc = sysfs_attr_ns(dir_sd->s_dir.kobj, attr, &ns);
if (rc)
return rc;
//目录下文件所用的那个dirent
sd = sysfs_new_dirent(attr->name, mode, type);
if (!sd)
return -ENOMEM;
sd->s_ns = ns;
sd->s_attr.attr = (void *)attr;
sysfs_dirent_init_lockdep(sd);
sysfs_addrm_start(&acxt, dir_sd);
//这里与前面相同了,就是在dirent结构体系中加入一个元素
rc = sysfs_add_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
if (rc)
sysfs_put(sd);
return rc;
}
//文件系统mount过程
/*
* struct path
* /include/linux/path.h
*/
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
/*
* /fs/namespace.c中的系统调用定义
* SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
* char __user *, type, unsigned long, flags, void __user *, data)
* 系统调用mount有5个参数,此函数最后是调用do_mount完成mount任务
*/
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
{
......
//取得挂载点的path结构信息,应该是根文件系统目录
retval = kern_path(dir_name, LOOKUP_FOLLOW, &path);
......
//如果是新加载的文件系统,执行这里
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page)
}
1916/*
1917 * create a new mount for userspace and request it to be added into the
1918 * namespace's tree
1919 */
1920static int do_new_mount(struct path *path, char *type, int flags,
1921 int mnt_flags, char *name, void *data)
1922{
1923 struct vfsmount *mnt;
1924 int err;
1925
1926 if (!type)
1927 return -EINVAL;
1928
1929 /* we need capabilities... */
1930 if (!capable(CAP_SYS_ADMIN))
1931 return -EPERM;
1932 //加载type字串指定的文件系统,过程与rootfs类似
1933 mnt = do_kern_mount(type, flags, name, data);
1934 if (IS_ERR(mnt))
1935 return PTR_ERR(mnt);
1936 //将mnt挂载到path指定的路径上
1937 err = do_add_mount(real_mount(mnt), path, mnt_flags);
1938 if (err)
1939 mntput(mnt);
1940 return err;
1941}
/*
* 功能:
* 将newmnt文件系统加载到path指定的vfs路径上
* 参数:
* newmnt:刚才加载的文件系统
* path:newmnt需要加载到的vfs路径
* 说明:
* 因为path可能加载了别的文件系统(顶层是rootfs,子层是别的),所以要进入到最
* 内层(最后加载的文件系统)锁住上层mnt
* add a mount into a namespace's mount tree
*/
1878static int do_add_mount(struct mount *newmnt, struct path *path, int mnt_flags)
1879{
1880 int err;
1881
1882 mnt_flags &= ~(MNT_SHARED | MNT_WRITE_HOLD | MNT_INTERNAL);
1883
1884 err = lock_mount(path);
1885 if (err)
1886 return err;
1887
1888 err = -EINVAL;
1889 if (unlikely(!check_mnt(real_mount(path->mnt)))) {
1890 /* that's acceptable only for automounts done in private ns */
1891 if (!(mnt_flags & MNT_SHRINKABLE))
1892 goto unlock;
1893 /* ... and for those we'd better have mountpoint still alive */
1894 if (!real_mount(path->mnt)->mnt_ns)
1895 goto unlock;
1896 }
1897
1898 /* Refuse the same filesystem on the same mount point */
1899 err = -EBUSY;
1900 if (path->mnt->mnt_sb == newmnt->mnt.mnt_sb &&
1901 path->mnt->mnt_root == path->dentry)
1902 goto unlock;
1903
1904 err = -EINVAL;
1905 if (S_ISLNK(newmnt->mnt.mnt_root->d_inode->i_mode))
1906 goto unlock;
1907
1908 newmnt->mnt.mnt_flags = mnt_flags;
1909 err = graft_tree(newmnt, path);
1910
1911unlock:
1912 unlock_mount(path);
1913 return err;
1914}
//锁住父mount/
/*
* 将path指定的最内层mnt锁住,path可能加载了多个文件系统,所以要进入
* 到最内层的
*/
1543static int lock_mount(struct path *path)
1544{
1545 struct vfsmount *mnt;
1546retry:
1547 mutex_lock(&path->dentry->d_inode->i_mutex);
1548 if (unlikely(cant_mount(path->dentry))) {
1549 mutex_unlock(&path->dentry->d_inode->i_mutex);
1550 return -ENOENT;
1551 }
1552 down_write(&namespace_sem);
//查找path对应的第一个子mnt
1553 mnt = lookup_mnt(path);
//一直向下一层找,直到下层没有了(llokup_mnt返回0
1554 if (likely(!mnt))
1555 return 0;
/*
* 找到了本层的子层mnt,释放命名空间锁本层inode锁
* 释放路径锁。然后迭代:让path指向子层mnt,和dentry
* 再retry
*/
1556 up_write(&namespace_sem);
1557 mutex_unlock(&path->dentry->d_inode->i_mutex);
1558 path_put(path);
1559 path->mnt = mnt;
1560 path->dentry = dget(mnt->mnt_root);
1561 goto retry;
1562}
/*
575 * lookup_mnt - Return the first child mount mounted at path
576 */
590struct vfsmount *lookup_mnt(struct path *path)
591{
592 struct mount *child_mnt;
593
594 br_read_lock(&vfsmount_lock);
595 child_mnt = __lookup_mnt(path->mnt, path->dentry, 1);
596 if (child_mnt) {
597 mnt_add_count(child_mnt, 1);
598 br_read_unlock(&vfsmount_lock);
599 return &child_mnt->mnt;
600 } else {
601 br_read_unlock(&vfsmount_lock);
602 return NULL;
603 }
604}
/*
* 根据dir指示返回mnt的第一个或最后一个子mnt
* mount_hashtable[hash(mnt, dentry)]的值是一个链表,存储着相同hash值的mnt
* 根据代码大概是,某一个path对应一对mnt dentry,在此path挂载的话,会有mnt1,
* dentry1,再在此path挂载的话,会有mnt2,dentry2并且其父是mnt1,dentry1而并不
* 是mnt和dentry。那意味着hash表项中(&p->mnt_parent->mnt == mnt &&
* p->mnt_mountpoint == dentry)只能成立一次。也就是说同一挂载点的mnt,dentry
* 只可能有一个儿子。(这块不明白)
*/
553struct mount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry,
554 int dir)
555{
556 struct list_head *head = mount_hashtable + hash(mnt, dentry);
557 struct list_head *tmp = head;
558 struct mount *p, *found = NULL;
559
560 for (;;) {
//顺着来还是倒着来
561 tmp = dir ? tmp->next : tmp->prev;
562 p = NULL;
563 if (tmp == head)
564 break;
565 p = list_entry(tmp, struct mount, mnt_hash);
//确定一下关系,因为hash有可能冲突
566 if (&p->mnt_parent->mnt == mnt && p->mnt_mountpoint == dentry) {
567 found = p;
568 break;
569 }
570 }
571 return found;
572}
//嫁接子mount到父mount上//
1570static int graft_tree(struct mount *mnt, struct path *path)
1571{
1572 if (mnt->mnt.mnt_sb->s_flags & MS_NOUSER)
1573 return -EINVAL;
1574
1575 if (S_ISDIR(path->dentry->d_inode->i_mode) !=
1576 S_ISDIR(mnt->mnt.mnt_root->d_inode->i_mode))
1577 return -ENOTDIR;
1578
1579 if (d_unlinked(path->dentry))
1580 return -ENOENT;
1581
1582 return attach_recursive_mnt(mnt, path, NULL);
1583}
path walk//
static int link_path_walk(const char *name, struct nameidata *nd)
1714{
1715 struct path next;
1716 int err;
1717
1718 while (*name=='/')
1719 name++;
1720 if (!*name)
1721 return 0;
1722
1723 /* At this point we know we have a real path component. */
1724 for(;;) {
1725 struct qstr this;
1726 long len;
1727 int type;
1728
1729 err = may_lookup(nd);
1730 if (err)
1731 break;
1732
1733 len = hash_name(name, &this.hash);
1734 this.name = name;
1735 this.len = len;
1736
1737 type = LAST_NORM;
1738 if (name[0] == '.') switch (len) {
1739 case 2:
1740 if (name[1] == '.') {
1741 type = LAST_DOTDOT;
1742 nd->flags |= LOOKUP_JUMPED;
1743 }
1744 break;
1745 case 1:
1746 type = LAST_DOT;
1747 }
1748 if (likely(type == LAST_NORM)) {
1749 struct dentry *parent = nd->path.dentry;
1750 nd->flags &= ~LOOKUP_JUMPED;
1751 if (unlikely(parent->d_flags & DCACHE_OP_HASH)) {
1752 err = parent->d_op->d_hash(parent, nd->inode,
1753 &this);
1754 if (err < 0)
1755 break;
1756 }
1757 }
1758
1759 if (!name[len])
1760 goto last_component;
1761 /*
1762 * If it wasn't NUL, we know it was '/'. Skip that
1763 * slash, and continue until no more slashes.
1764 */
1765 do {
1766 len++;
1767 } while (unlikely(name[len] == '/'));
1768 if (!name[len])
1769 goto last_component;
1770 name += len;
1771
1772 err = walk_component(nd, &next, &this, type, LOOKUP_FOLLOW);
1773 if (err < 0)
1774 return err;
1775
1776 if (err) {
1777 err = nested_symlink(&next, nd);
1778 if (err)
1779 return err;
1780 }
1781 if (can_lookup(nd->inode))
1782 continue;
1783 err = -ENOTDIR;
1784 break;
1785 /* here ends the main loop */
1786
1787last_component:
1788 nd->last = this;
1789 nd->last_type = type;
1790 return 0;
1791 }//for(;;)循环
1792 terminate_walk(nd);
1793 return err;
1794}
1795
/*
* ///opt/soft/abc.txt
*/
1713static int link_path_walk(const char *name, struct nameidata *nd)
1714{
1715 struct path next;
1716 int err;
1717 //去前导'/'=opt/soft/abc.txt,让name指向第一个分量开始处
1718 while (*name=='/')
1719 name++;
1720 if (!*name)
1721 return 0;
1722
1723 /* At this point we know we have a real path component. */
1724 for(;;) {//按name分量处理
1725 struct qstr this;//当前分量名,长度
1726 long len;
1727 int type;
1728 //inode 访问检查
1729 err = may_lookup(nd);
1730 if (err)
1731 break;
1732
1733 len = hash_name(name, &this.hash);//当前分量hash
1734 this.name = name;//当前分量开始处
1735 this.len = len;//当前分量长度
1736
1737 type = LAST_NORM;//上一个分量正常
1738 if (name[0] == '.') switch (len) {
1739 case 2:
1740 if (name[1] == '.') {
1741 type = LAST_DOTDOT;//上一分量是"点点"
1742 nd->flags |= LOOKUP_JUMPED;
1743 }
1744 break;
1745 case 1:
1746 type = LAST_DOT;//上一分量是"点"
1747 }
1748 if (likely(type == LAST_NORM)) {
1749 struct dentry *parent = nd->path.dentry;
1750 nd->flags &= ~LOOKUP_JUMPED;
1751 if (unlikely(parent->d_flags & DCACHE_OP_HASH)) {
1752 err = parent->d_op->d_hash(parent, nd->inode,
1753 &this);
1754 if (err < 0)
1755 break;
1756 }
1757 }
1758 //*(name+len)==null表示 name即name分量是最后一个:xxx/name'\0'
1759 if (!name[len])
1760 goto last_component;
1761 /*
1762 * If it wasn't NUL, we know it was '/'. Skip that
1763 * slash, and continue until no more slashes.
* 非null表示name后还有分量,那么过滤掉相应的'/'
1764 */
1765 do {
1766 len++;
1767 } while (unlikely(name[len] == '/'));
1768 if (!name[len])
1769 goto last_component;
//name指向下一个分量,说不定有下一次for循环
1770 name += len;
1771 //得到当前分量相关的dentry等数据结构存入nd,再循环处理下一分量
1772 err = walk_component(nd, &next, &this, type, LOOKUP_FOLLOW);
1773 if (err < 0)
1774 return err;
1775
1776 if (err) {//err>0时,处理符号链接
1777 err = nested_symlink(&next, nd);
1778 if (err)
1779 return err;
1780 }
//err==0时,继续for循环,处理下一分量节点
1781 if (can_lookup(nd->inode))
1782 continue;
1783 err = -ENOTDIR;
1784 break;
1785 /* here ends the main loop */
1786
1787last_component:
/*
* 到这里,this指向的是最后一个分量
* 到这里函数才能正确地退出,如果是
* break出去的则表示出错
*/
1788 nd->last = this;
1789 nd->last_type = type;
1790 return 0;
1791 }
1792 terminate_walk(nd);
1793 return err;
1794}
/*
* 主要是两种处理方法,一种是查cache,一种是慢速找,最终用到路径上倒数第
* 二个节点的dentry(最后一个的父)相关的inode,然后调用inode->lookup根据
* 设置的name找到相关的dentry
*
* lookup_fast//rcu列表中查找
* __d_lookup_rcu
* __d_lookup
* lookup_slow
* __lookup_hash
* lookup_dcache
* d_lookup
* __d_lookup
* lookup_real
* dir->i_op->lookup//调用inode的lookup
*/
1475static inline int walk_component(struct nameidata *nd, struct path *path,
1476 struct qstr *name, int type, int follow)
1477{
1478 struct inode *inode;
1479 int err;
1480 /*
1481 * "." and ".." are special - ".." especially so because it has
1482 * to be able to know about the current root directory and
1483 * parent relationships.
1484 */
1485 if (unlikely(type != LAST_NORM))
1486 return handle_dots(nd, type);//点/点点的处理
1487 err = lookup_fast(nd, name, path, &inode);
1488 if (unlikely(err)) {
1489 if (err < 0)
1490 goto out_err;
1491
1492 err = lookup_slow(nd, name, path);
1493 if (err < 0)
1494 goto out_err;
1495
1496 inode = path->dentry->d_inode;
1497 }
1498 err = -ENOENT;
1499 if (!inode)
1500 goto out_path_put;
1501
1502 if (should_follow_link(inode, follow)) {
1503 if (nd->flags & LOOKUP_RCU) {
1504 if (unlikely(unlazy_walk(nd, path->dentry))) {
1505 err = -ECHILD;
1506 goto out_err;
1507 }
1508 }
1509 BUG_ON(inode != path->dentry->d_inode);
1510 return 1;
1511 }
//path内容存入nd
1512 path_to_nameidata(path, nd);
1513 nd->inode = inode;
1514 return 0;
1515
1516out_path_put:
1517 path_to_nameidata(path, nd);
1518out_err:
1519 terminate_walk(nd);
1520 return err;
1521}
1522
/*
* 总结:
* 粗略地看了下vfs。具体的fs只需提供相关结构的方法即可,vfs只是一个框架。
* 具体fs满足vfs所需要的接口。比如,vfs查找路径,最终要生成一个dentry,
* 而sysfs以硬件和dirent来级联,但用户调用sysfs的lookup时,sysfs需要根据
* 当前的参数生成一个dentry。vfs不管sysfs内部如何实现。
* 遗留问题:
* 往同一个目录mount多次,其树状结构是什么样的
* 路径查找中所使用的cache系统原理
*/
《Linux内核源码分析-安装根文件系统-init_rootfs- init_mount_tree》
https://blog.csdn.net/weifenghai/article/details/52834080
本文主要参考《深入理解Linux内核》,结合2.6.11.1版的内核代码,分析内核文件子系统中的安装根文件系统函数。
注意:
1、不描述内核同步、错误处理、参数合法性验证相关的内容
2、源码摘自Linux内核2.6.11.1版
3、阅读本文请结合《深入理解Linux内核》第三版相关章节
4、本文会不定时更新
函数调用层次结构
1、init_rootfs
函数功能:
注册rootfs文件系统
函数源码:
该源码包含在文件:fs/ramfs/inode.c
nt __init init_rootfs(void)
{
returnregister_filesystem(&rootfs_fs_type);
}
static struct file_system_typerootfs_fs_type = {
.name = “rootfs”,
.get_sb = rootfs_get_sb,
.kill_sb = kill_litter_super,
};
2、init_mount_tree
函数功能:
安装rootfs文件系统
函数源码:
static void __initinit_mount_tree(void)
{
structvfsmount *mnt;
structnamespace *namespace;
structtask_struct *g, *p;
mnt= do_kern_mount("rootfs", 0, "rootfs", NULL);
if(IS_ERR(mnt))
panic("Can'tcreate rootfs");
namespace= kmalloc(sizeof(*namespace), GFP_KERNEL);
if(!namespace)
panic("Can'tallocate initial namespace");
atomic_set(&namespace->count,1); //引用计数器
INIT_LIST_HEAD(&namespace->list);//命名空间中已安装文件系统描述链表头
init_rwsem(&namespace->sem);//保护namespace的读写信号量
list_add(&mnt->mnt_list,&namespace->list);//把rootfs文件系统加入命名空间中已安装文件系统描述链表
namespace->root= mnt; //命名空间根目录的已安装文件系统
mnt->mnt_namespace= namespace; //rootfs文件系统的命名空间
init_task.namespace= namespace; //init进程的命名空间
read_lock(&tasklist_lock);
/初始化系统中所有进程的地址空间为默认地址空间/
do_each_thread(g,p) {
get_namespace(namespace);
p->namespace= namespace;
}while_each_thread(g, p);
read_unlock(&tasklist_lock);
set_fs_pwd(current->fs,namespace->root, namespace->root->mnt_root);
set_fs_root(current->fs,namespace->root, namespace->root->mnt_root);
}
函数处理流程:
1、 调用函数do_kern_mount进行实际安装操作,返回新安装文件系统描述符的地址
2、 调用kmalloc分配一个namespace对象,对象地址存放在局部变量namespace中,并初始化namespace、mnt相关数据结构,具体参见注释
3、 初始化系统中所有进程的地址空间为默认地址空间
4、 调用函数set_fs_pwd和set_fs_root初始化当前进程的当前工作目录和根目录
3、do_kern_mount
函数源码:
struct vfsmount *
do_kern_mount(const char *fstype, intflags, const char *name, void *data)
{
structfile_system_type *type = get_fs_type(fstype);
structsuper_block *sb = ERR_PTR(-ENOMEM);
structvfsmount *mnt;
interror;
char*secdata = NULL;
if(!type)
returnERR_PTR(-ENODEV);
mnt= alloc_vfsmnt(name);
if(!mnt)
gotoout;
if(data) {
secdata= alloc_secdata();
if(!secdata) {
sb= ERR_PTR(-ENOMEM);
gotoout_mnt;
}
error= security_sb_copy_data(type, data, secdata);
if(error) {
sb= ERR_PTR(error);
gotoout_free_secdata;
}
}
sb= type->get_sb(type, flags, name, data);
if(IS_ERR(sb))
gotoout_free_secdata;
error = security_sb_kern_mount(sb, secdata);
if (error)
goto out_sb;
mnt->mnt_sb= sb; //超级块
mnt->mnt_root= dget(sb->s_root); //根文件系统
mnt->mnt_mountpoint= sb->s_root; //挂载点
mnt->mnt_parent= mnt; //父文件系统
mnt->mnt_namespace= current->namespace; //命名空间
up_write(&sb->s_umount);
put_filesystem(type);
returnmnt;
out_sb:
up_write(&sb->s_umount);
deactivate_super(sb);
sb= ERR_PTR(error);
out_free_secdata:
free_secdata(secdata);
out_mnt:
free_vfsmnt(mnt);
out:
put_filesystem(type);
return(struct vfsmount *)sb;
}
函数处理流程:
1、根据文件系统类型名称,调用函数get_fs_type获得类型为file_system_type的文件系统类型对象的地址,存入局部变量type中
2、调用alloc_vfsmnt从mnt_cache slab高速缓存中分配一个新的文件系统对象,地址存入局部变量mnt中
3、调用依赖于文件系统的type->get_sb函数分配并初始化一个超级块
4、初始化mnt相关字段,具体参见注释
4、rootfs_get_sb
函数功能:
是get_sb_nodev的封装函数
函数源码:
static struct super_block*rootfs_get_sb(struct file_system_type *fs_type,
intflags, const char *dev_name, void *data)
{
returnget_sb_nodev(fs_type, flags|MS_NOUSER, data, ramfs_fill_super);
}
5、get_sb_nodev
函数功能:
略
函数参数:
略
函数源码:
struct super_block *get_sb_nodev(structfile_system_type *fs_type,
intflags, void *data,
int(*fill_super)(struct super_block *, void *, int))
{
interror;
structsuper_block *s = sget(fs_type, NULL, set_anon_super, NULL);
if(IS_ERR(s))
returns;
s->s_flags= flags;
error= fill_super(s, data, flags & MS_VERBOSE ? 1 : 0);
if(error) {
up_write(&s->s_umount);
deactivate_super(s);
returnERR_PTR(error);
}
s->s_flags|= MS_ACTIVE;
returns;
}
函数处理流程:
1、调用sget函数分配并初始化超级块对象
2、调用函数fill_super,即ramfs_fill_super初始化超级块对象
6、ramfs_fill_super
函数功能:
初始化相关字段,并分配根索引节点对象和根目录项对象
函数源码:
static int ramfs_fill_super(structsuper_block * sb, void * data, int silent)
{
structinode * inode;
structdentry * root;
sb->s_maxbytes= MAX_LFS_FILESIZE;
sb->s_blocksize= PAGE_CACHE_SIZE;
sb->s_blocksize_bits= PAGE_CACHE_SHIFT;
sb->s_magic= RAMFS_MAGIC;
sb->s_op= &ramfs_ops;
sb->s_time_gran= 1;
inode= ramfs_get_inode(sb, S_IFDIR | 0755, 0);
if(!inode)
return-ENOMEM;
root= d_alloc_root(inode);
if(!root) {
iput(inode);
return-ENOMEM;
}
sb->s_root= root;
return0;
}
7、sget
函数源码:
/**
-
sget - findor create a superblock
-
@type: filesystem type superblock should belong to
-
@test: comparison callback
-
@set: setup callback
-
@data: argument to each of them
*/
struct super_block *sget(structfile_system_type *type,
int(*test)(struct super_block *,void *),
int(*set)(struct super_block *,void *),
void*data)
{
structsuper_block *s = NULL;
structlist_head *p;
interr;
retry:
spin_lock(&sb_lock);
if(test) list_for_each(p, &type->fs_supers) {
structsuper_block *old;
old= list_entry(p, struct super_block, s_instances);
if(!test(old, data))
continue;
if(!grab_super(old))
gotoretry;
if(s)
destroy_super(s);
returnold;
}
if(!s) {
spin_unlock(&sb_lock);
s= alloc_super();
if(!s)
returnERR_PTR(-ENOMEM);
gotoretry;
}
err= set(s, data);
if(err) {
spin_unlock(&sb_lock);
destroy_super(s);
returnERR_PTR(err);
}
s->s_type= type;
strlcpy(s->s_id,type->name, sizeof(s->s_id));
list_add_tail(&s->s_list,&super_blocks);
list_add(&s->s_instances,&type->fs_supers);
spin_unlock(&sb_lock);
get_filesystem(type);
returns;
}
函数处理流程:
1、如果定义了test函数,用该函数为对比函数,在文件系统类型的超级块链表中查找super_block对象,找到则返回
2、未找到则调用alloc_super函数分配一个super_block对象,并把对象地址存入局部变量s中
3、调用set函数,即set_anon_super函数初始化超级块
8、set_anon_super
函数功能:
初始化特殊文件系统的超级块,分配一个主设备号为0、次设备号任意(每个特殊文件系统有不同的值)的设备标识符,用该标识符初始化超级块的s_dev字段。
函数源码:
int set_anon_super(struct super_block*s, void *data)
{
intdev;
interror;
retry:
if(idr_pre_get(&unnamed_dev_idr, GFP_ATOMIC) == 0)
return-ENOMEM;
spin_lock(&unnamed_dev_lock);
error= idr_get_new(&unnamed_dev_idr, NULL, &dev);
spin_unlock(&unnamed_dev_lock);
if(error == -EAGAIN)
/*We raced and lost with another CPU. */
gotoretry;
elseif (error)
return-EAGAIN;
if((dev & MAX_ID_MASK) == (1 << MINORBITS)) {
spin_lock(&unnamed_dev_lock);
idr_remove(&unnamed_dev_idr,dev);
spin_unlock(&unnamed_dev_lock);
return-EMFILE;
}
s->s_dev= MKDEV(0, dev & MINORMASK);
return0;
}
注:idr相关处理函数解释摘自“参考文章1”,摘部分内容如下:
idr在linux内核中指的就是整数ID管理机制,从本质上来说,这就是一种将整数ID号和特定指针关联在一起的机制。这个机制最早是在2003年2月加入内核的,当时是作为POSIX定时器的一个补丁。现在,在内核的很多地方都可以找到idr的身影。
idr机制适用在那些需要把某个整数和特定指针关联在一起的地方。举个例子,在I2C总线中,每个设备都有自己的地址,要想在总线上找到特定的设备,就必须要先发送该设备的地址。如果我们的PC是一个I2C总线上的主节点,那么要访问总线上的其他设备,首先要知道他们的ID号,同时要在pc的驱动程序中建立一个用于描述该设备的结构体。
此时,问题来了,我们怎么才能将这个设备的ID号和他的设备结构体联系起来呢?最简单的方法当然是通过数组进行索引,但如果ID号的范围很大(比如32位的ID号),则用数组索引显然不可能;第二种方法是用链表,但如果网络中实际存在的设备较多,则链表的查询效率会很低。遇到这种清况,我们就可以采用idr机制,该机制内部采用radix树实现,可以很方便地将整数和指针关联起来,并且具有很高的搜索效率。
(1)获得idr
要在代码中使用idr,首先要包括<linux/idr.h>。接下来,我们要在代码中分配idr结构体,并初始化:
void idr_init(struct idr *idp);
其中idr定义如下:
struct idr {
struct idr_layer *top;
struct idr_layer id_free;
int layers;
int id_free_cnt;
spinlock_t lock;
};
/ idr是idr机制的核心结构体 */
(2)为idr分配内存
int idr_pre_get(struct idr *idp, unsigned int gfp_mask);
每次通过idr获得ID号之前,需要先分配内存。
返回0表示错误,非零值代表正常
(3)分配ID号并将ID号和指针关联
int idr_get_new(struct idr *idp, void *ptr, int *id);
int idr_get_new_above(struct idr *idp, void *ptr, int start_id, int *id);
idp: 之前通过idr_init初始化的idr指针
id: 由内核自动分配的ID号
ptr: 和ID号相关联的指针
start_id: 起始ID号。内核在分配ID号时,会从start_id开始。如果为I2C节点分配ID号,可以将设备地址作为start_id
函数调用正常返回0,如果没有ID可以分配,则返回-ENOSPC
在实际中,上述函数常常采用如下方式使用:
again:
if (idr_pre_get(&my_idr, GFP_KERNEL) == 0) {
/* No memory, give up entirely */
}
spin_lock(&my_lock);
result = idr_get_new(&my_idr, &target, &id);
if (result == -EAGAIN) {
sigh();
spin_unlock(&my_lock);
goto again;
}
(4)通过ID号搜索对应的指针
void *idr_find(struct idr *idp, int id);
返回值是和给定id相关联的指针,如果没有,则返回NULL
(5)删除ID
要删除一个ID,使用:
void idr_remove(struct idr *idp, int id);
通过上面这些方法,内核代码可以为子设备,inode生成对应的ID号。这些函数都定义在<linux-2.6.xx/lib/idr.c>中
9、alloc_super
函数源码:
/**
-
alloc_super - createnew superblock
-
Allocatesand initializes a new &struct super_block. alloc_super()
-
returnsa pointer new superblock or %NULL if allocation had failed.
*/
static struct super_block*alloc_super(void)
{
structsuper_block *s = kmalloc(sizeof(struct super_block), GFP_USER);
staticstruct super_operations default_op;
if(s) {
memset(s,0, sizeof(struct super_block));
if(security_sb_alloc(s)) {
kfree(s);
s= NULL;
gotoout;
}
INIT_LIST_HEAD(&s->s_dirty);//脏的索引节点链表头
INIT_LIST_HEAD(&s->s_io);//正在被写入磁盘的索引节点链表头
INIT_LIST_HEAD(&s->s_files);//文件对象的链表头
INIT_LIST_HEAD(&s->s_instances);//文件系统类型对象的超级块链表指针
INIT_HLIST_HEAD(&s->s_anon);//用于处理远程网络文件系统的匿名目录项链表头
INIT_LIST_HEAD(&s->s_inodes);//索引索引节点链表头
init_rwsem(&s->s_umount);//卸载使用的读写信号量
sema_init(&s->s_lock,1); //超级块信号量
down_write(&s->s_umount);//获取卸载写信号量
s->s_count= S_BIAS; //引用计数器
atomic_set(&s->s_active,1);//次级引用计数器
sema_init(&s->s_vfs_rename_sem,1);//vfs重命名信号量
sema_init(&s->s_dquot.dqio_sem,1); //磁盘限额相关
sema_init(&s->s_dquot.dqonoff_sem,1); //磁盘限额相关
init_rwsem(&s->s_dquot.dqptr_sem);//磁盘限额相关
init_waitqueue_head(&s->s_wait_unfrozen);//进程挂起的等待队列,直到文件系统被解冻
s->s_maxbytes= MAX_NON_LFS; //文件的最长长度,#define MAX_NON_LFS ((1UL<<31)- 1)
s->dq_op= sb_dquot_ops; //磁盘限额处理方法
s->s_qcop= sb_quotactl_ops;//磁盘限额管理方法
s->s_op= &default_op; //超级块方法
s->s_time_gran= 1000000000; //时间戳粒度,纳秒级,默认值1秒
}
out:
returns;
}
函数处理流程:
1、调用kmalloc函数分配超级块对象,存入局部变量s中
2、分配成功,初始化s中的相关字段,见代码注释
————————————————
《linux系统调用mount全过程分析【转】》
本文转载自:https://blog.csdn.net/skyflying2012/article/details/9748133
系统调用本身是软中断,使用系统调用,内核也陷入内核态,异常处理,找到相应的入口最后就会跳转到sys_mount,跳转到sys_mount之前的这个过程主要是跟系统的异常处理相关,以mips处理器为例,相关代码在arch/mips/kernel/下的traps.c syscall32-o32.S等文件中实现的,过几天有空再缕一遍,今天主要总结的是sys_mount之后的事情,内核是如何实现将文件系统挂载的过程
sys_mount的实现在fs/namespace.c中,我查看了2个版本的内核2.6.21和2.6.36,发现在36内核下使用SYSCALL_DEFINE5来定义的系统调用,21下是直接定义的sys_mount函数,网上搜了一下这个宏定义的分析,是为了解决64位机器上使用32位系统调用的问题,这个宏定义在另一篇文章中我总结分析了一下,这里我就从sys_mount函数开始往下跟。
mount的实现过程在深入理解linux内核的虚拟文件系统一章中也有分析
1 sys_mount
sys_mount主要将系统调用的参数dev_name dir_name type flags data从用户空间拷贝到内核空间,然后调用do_mount函数
2 do_mount
调用kern_path来查找挂载点的路径名,之后会根据传递参数flags来决定如何挂载,我们按照最简单的挂载方式,就是挂载一个普通的磁盘分区来分析,这样会调用do_new_mount
3 do_new_mount
do_new_mount函数会先定义struct vfsmount结构体,这个结构体在内核中用来表示已挂载文件系统的一些信息,具体的结构体成员解释可以参考UTLK的485页
接着会lock_kernel获取内核锁,调用do_kern_mount函数,do_kern_mount函数的返回值就是struct vfsmount,参数name是挂载的设备文件,因此这个函数会根据要挂载的文件系统将这个结构体填充。
4 do_kern_mount
do_kern_mount函数首先会调用get_fs_type来查看内核是否注册了参数type所指的文件系统,对于内核源码下fs目录下的所有文件系统都会通过调用register_filesystem来注册这个文件系统,其实就是添加到内核文件系统链表中,get_fs_type会将参数type字符串跟内核链表中所有已经注册的文件系统结构体file_system_type的name成员向比较,如果找到,则说明内核已经注册了相应文件系统,并且返回相应文件系统注册的file_system_type结构体。后面的挂载过程需要使用到这个结构体中的成员。
找到相应的file_system_type后do_kern_mount会调用vfs_kern_mount,这个函数返回值是struct vfsmount
5 vfs_kern_mount
vfs_kern_mount首先调用alloc_vfsmnt为struct vfsmount分配内存空间,参数是要挂载的设备文件名称,在alloc_vfsmnt中会将name来填充vfsmnt结构体的mnt_devname成员,vfs_kern_mount才是真正去填充vfsmnt结构体的函数。
接着vfs_kern_mount会调用file_system_type参数中的get_sb成员函数,这个就是使用相应注册文件系统的get_sb函数来填充vfsmnt结构体的super_block结构体,get_sb在具体文件系统的实现中,如果自己写一个简单文件系统的话,实现get_sb算是最基本的一步,get_sb在具体的文件系统实现中会读取对应磁盘设备上的superblock将相应的信息填充到内存中的super_block对象中,并且建立起该文件系统根目录的目录项对象和inode节点对象,这样就建立了从vfsmnt到superblock到dentry到inode的一条索引。
调用get_sb填充完vfsmnt的super_block成员后在vfs_kern_mount中在将vfsmnt的其他一些记录成员进行初始化,成功返回
6 do_kern_mount
从vfs_kern_mount返回后,内核中代表挂载文件系统的vfsmnt结构体填充成功,后面主要是调用put_filesystem将对应文件系统模块使用量兼1.返回到do_new_mount
7 do_new_mount
从do_kern_mount返回后,vfsmnt结构体填充成功,do_new_mount调用unlock_kernel释放内核锁,最后调用do_add_mount将新挂载的文件系统(由vfsmnt表示)添加到系统的命名空间结构体的已挂载文件系统链表中,命名空间是指系统中以挂载文件系统树,每个进程的PCB中都有namespace成员来表示该进程的命名空间,大多数的进程共享同一个命名空间,所以如果在一个进程中将磁盘挂载到系统中,在另一个进程也是可以看到的,这就是由命名空间来实现的。vfsmnt添加到相应的namespace中的vfsmnt链表成功后do_new_mount返回
8 do_mount sys_mount
从do_new_mount返回后do_mount返回,最后sys_mount返回,这一块没有重要的知识了。
就这样从sys_mount到vfs_kern_mount到get_sb,然后再层层返回,内核也就实现了指定文件系统的磁盘挂载到指定目录。总体感觉在这个过程中内核主要实现vfsmnt结构体的填充,这个结构体中比较重要的是super_block的填充,然后将vfsmnt添加到相应进程PCB的namespace成员所指向的namespace结构体中,大部分进程都指向这个namespace,所以挂载对大部分进程可见。
上面的分析是按照最基本的挂载方式,复杂的方式以后在分析














 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









