






摘自维基百科:https://en.wikipedia.org/wiki/Feature_scaling
-
为什么要进行归一化
Since the range of values of raw data varies widely, in some machine learning algorithms, objective functions will not work properly without normalization. For example, many classifiers calculate the distance between two points by the Euclidean distance. If one of the features has a broad range of values, the distance will be governed by this particular feature. Therefore, the range of all features should be normalized so that each feature contributes approximately proportionately to the final distance.Another reason why feature scaling is applied is that gradient descent converges much faster with feature scaling than without it.
-
4种方法
1、Rescaling (min-max normalization)Also known as min-max scaling or min-max normalization, is the simplest method and consists in rescaling the range of features to scale the range in [0, 1] or [−1, 1]. Selecting the target range depends on the nature of the data. The general formula for a min-max of [0, 1] is given as:
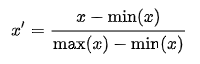
Normalizing errors when population parameters are known. Works well for populations that are normally distributed https://en.wikipedia.org/wiki/Normalization_(statistics)
where x is an original value, x’ is the normalized value. For example, suppose that we have the students’ weight data, and the students’ weights span [160 pounds, 200 pounds]. To rescale this data, we first subtract 160 from each student’s weight and divide the result by 40 (the difference between the maximum and minimum weights).To rescale a range between an arbitrary set of values [a, b], the formula becomes:
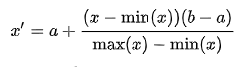
where a,b are the min-max values.
scaler = MinMaxScaler(feature_range=(0, 1))
train_x = scaler.fit_transform(train_x)
2、Standardization (Z-score Normalization)
In machine learning, we can handle various types of data, e.g. audio signals and pixel values for image data, and this data can include multiple dimensions. Feature standardization makes the values of each feature in the data have zero-mean (when subtracting the mean in the numerator) and unit-variance. This method is widely used for normalization in many machine learning algorithms (e.g., support vector machines, logistic regression, and artificial neural networks)[2][citation needed]. The general method of calculation is to determine the distribution mean and standard deviation for each feature. Next we subtract the mean from each feature. Then we divide the values (mean is already subtracted) of each feature by its standard deviation.

3、Mean normalization
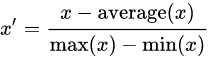
4、Scaling to unit length
Another option that is widely used in machine-learning is to scale the components of a feature vector such that the complete vector has length one. This usually means dividing each component by the Euclidean length of the vector:
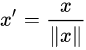
In some applications (e.g. Histogram features) it can be more practical to use the L1 norm (i.e. Manhattan Distance, City-Block Length or Taxicab Geometry) of the feature vector. This is especially important if in the following learning steps the Scalar Metric is used as a distance measure.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









