









Hackerland is a happy democratic country with m×n cities, arranged in a rectangular m by n grid and connected by m roads in the east-west direction and n roads in the north-south direction. By public demand, this orthogonal road system is to be supplemented by a system of highways in sucha way that there will be a direct connection between any pair of cities. Each highway is a straight line going through two or more cities. If two cities lie on the same highway, then they are directly connected.If two cities are in the same row or column, then they are already connected by the existing orthogonal road system (each east-west road connects all the m cities in that row and each north-south road connects all the n cities in that column), thus no new highway is needed to connect them. Your task is to count the number of highway that has to be built (a highway that goes through several cities on a straight line is counted as a single highway).
Input
The input contains several blocks of test cases. Each test case consists of a single line containing two integers 1![]() n , m
n , m![]() 300 , specifying the number of cities. The input is terminated by a test case with n = m = 0 .
300 , specifying the number of cities. The input is terminated by a test case with n = m = 0 .
Output
For each test case, output one line containing a single integer, the number of highways that must be built.
Sample Input
2 4 3 3 0 0
Sample Output
12 14
解题报告: 很好的一道递推题。300*300=90000点,要非常小心复杂度。
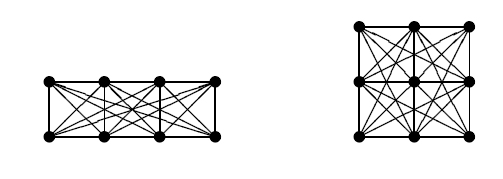
具体怎么做呢?按照样例中的第二个图来说,左上角设为(1, 1)点,右下角设为(3, 3)点。首先我们可以只求斜率为正的直线,计算结果时直接乘2,因为是完全对称的。然后看(3,3)点,与该点连接成直线的点有(2,2),(1,2),(2,1),而(1,1)点重复了。为什么(1,1)点重复了?因为(3,3)点与(1,1)点构成的向量是(2,2),那么(3,3)点与(1,1)向量构成的直线必然穿过与(2,2)向量构成的直线。简单来说,就是(2,2)向量不互质。
那么,如果我们要计算与(m,n)点相连的直线的数量,我们就必须求出[1, m)区间与[1, n)区间互质数的对数。
预处理所有可能点内的互质数的对数。注意复杂度。然后我们就知道了每个点可以连接的直线的数量。但是直接求和并不是最终解。继续看(3,3)点与(2,2)点连接的直线,这条线在(2,2)点连接(1,1)时已经计算过了。换句话说计算(m,n)点连接的直线数时得减去(m/2,n/2)区间内的直线数,该区间内的直须必然是之前就计算过的。
这样求和即可,复杂度大约为90000*3。代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
LL co_prime[333][333];
LL sum[333][333];
LL t_sum[333][333];
int gcd(int a,int b)
{
return b==0?a:gcd(b,a%b);
}
void init()
{
for(int i=1;i<=300;i++)
for(int j=1;j<=300;j++)
co_prime[i][j] = co_prime[i][j-1]+(gcd(i,j)==1?1:0);
for(int i=1;i<=300;i++)
for(int j=1;j<=300;j++)
sum[i][j]=sum[i-1][j]+co_prime[i][j];
for(int i=1;i<=300;i++)
for(int j=1;j<=300;j++)
t_sum[i][j]= t_sum[i-1][j] + t_sum[i][j-1] - t_sum[i-1][j-1]
+ sum[i][j] - sum[i/2][j/2];
}
int main()
{
init();
int m,n;
while(~scanf("%d%d",&n,&m) && (n||m))
printf("%lld\n", t_sum[n-1][m-1]*2);
}
这道题并不简单,训练指南里的中档题,我想了一下午了。不过很锻炼思维了。与之有些相似的题目有:















 74
74

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









