







Hadoop集群搭建
一. Linux虚拟机安装
1.1创建虚拟机
启动vmware,点击创建虚拟机,开始进行创建

在弹出的安装向导界面选择典型,之后选择下一步

选择稍后安装操作系统,再点下一步

在客户机操作系统选择linux,版本根据自己的选择,这里我选择centos7 64位,之后点击下一步

之后填好虚拟机名称和位置,点击下一步

这里磁盘大小默认20G即可,并磁盘拆分为多个文件,再点下一步

最后选择完成即可

创建成功后我们可以看见左侧多了一个虚拟机,之后我们选择编辑虚拟机开始配置

首先点击左侧内存,对内存进行编辑,右侧进行编辑,这里我电脑是32G,所以分配了3G

之后点击左侧的处理器开始编辑处理器,右侧根据自己的电脑配置进行设置

之后左侧选择CD/DVD进行镜像配置,右侧浏览选择镜像文件

这里我选择的是Minima镜像,之后选择打开就可以了

最后点击确定完成配置

1.2 安装centos
配置完后,点击开启此虚拟机进行安装

这里选择Install centos7 回车,等待安装

左右两个里面都选择中文,之后右下角选择继续

这里在系统内找到安装位置,点进去选择继续,之后再点击开始安装

在下一个界面点击ROOT密码设置密码

之后密码设置123456,点击完成

点击创建用户

设置好用户名,设置密码为123456,点击完成

最后点击完成配置

最后点击重启

输入root回车,密码输入123456回车,登陆成功!!

二. 虚拟机配置
2.1网络配置
1)查看本机网络适配器


2)查看虚拟机网络地址配置区间
Vmware点击编辑,再点击虚拟网络编辑器

点击上侧nat模式查看子网和子网掩码

3)配置网络参数
修改虚拟机网卡配置文件,输入如下命令
cd /etc/sysconfig/network-scripts
vi ifcfg-ens33

虚拟机ip地址的获取有两种方式,dhcp动态获取和静态配置
Dhcp方式
修改网络配置参数如下,保存退出

重启网络服务
service network start

查看ip配置 ipaddr
此时的ip地址为 192.168.1.129

测试网络连接情况
跟内,外网的连接情况

4)securect的使用
首先点击快速创建链接,输入ip地址和root,之后点击链接

输入好密码,点击保存密码,之后点击ok

链接成功

2.2静态IP配置
再次进入配置文件

填写各个值,并保存退出

重启网络,并进行测试网络联通情况

2.3配置主机名

2.4主机名和ip地址建立映射关系
修改配置/etc/hosts


注意:windows主机如果需要通过主机名来访问虚拟机,也需要配置,可以安装notepad++小巧的编辑器软件

之后进入etc文件,并打开hosts文件进行修改

添加这三行代码 ip + 主机名

之后在windows下测试链接情况

2.5新建hadoop集群搭建需要的目录
首先进入根目录,并在根目录下创建export文件夹

之后创建三个名为data,software和servers的文件夹

三.克隆虚拟机
3.1先克隆一个完整的备份
右键text01虚拟机,选择管理,选择克隆

之后直接选择下一页

之后选择虚拟机中的当前状态,之后下一页

之后选择创建完整的克隆,再选择下一页

之后填写好虚拟机名称和路径,选择完成

之后选择关闭即可克隆完成

3.2再快速克隆出两台虚拟机

3.3克隆机虚拟网络配置
分别在text02和text03中修改好自己的ip地址


之后重启网络服务,并查看ip地址

用远程工具链接测试


3.4修改主机名


3.5建立主机名和ip地址的映射关系
由于在text01的/etc/hosts文件已经把text02和text03的都配置好了,所以直接测试,可以连接内外网


四.SSH的主机之间的免密登录
首先在text01下输入ssh text01

之后第一次停顿输入yes

第二次停顿输入密码

4.1运行生成密钥的命令 ssh-keygen -t rsa
之后一路回车

查看生成文件夹

4.2复制生成的公钥文件
ssh-copy-id text01

之后同样的操作分别复制给text02和text03

测试ssh登录text02和text03

4.3对text02和text03做同样的操作
Text02下



测试登录情况:

Text03上



测试登录情况

五.在windows本地主机添加名称服务
按win + R,之后输入drivers,再点击确定

双击打开etc文件

之后右击hosts文件进行编辑

在该文件内建立text02和text03的映射


六.Notepad++插件的使用
打开Notepad++,先选插件,再选插件管理

之后,在搜索栏里搜索ftp,并勾选安装

之后,依次点击如图位置,并进行新建连接

之后依次选择新建链接,输入连接名,并点击ok

右侧选择sftp,之后依次填入主机名,用户名和密码,选择close

选择text01

选择是

之后双击查看连接情况
这里一定要双击斜杠

七.集群的搭建和配置
7.1 hadoop集群的部署模式
7.1.1独立模式
又称单机模式,所有的进程运行在一台主机上
7.2.2伪分布模式
Hadoop守护进程运行在一台主机上,namenode和datanode在一台主机上
7.3.3完全分布式模式
Hadoop守护进程运行在不同的主机上,主机分为namenode和datanode
7.2集群规划
| 主机/角色 | NameNode | SecondaryName | DataNode | ResourceManager | NodeManager |
|---|---|---|---|---|---|
| text01 | Yes | No | Yes | Yes | Yes |
| text02 | No | Yes | Yes | No | Yes |
| text03 | No | No | Yes | No | Yes |
7.3 linux下 JDK的安装
7.3.1下载jdk
百度搜索下载jdk 1.8 64 linux
 下载后是一个.tar.gz的压缩文件
下载后是一个.tar.gz的压缩文件

7.3.2 jdk安装到linux主机上
可以用ftp工具如fileZilla,或者使用centos自带的上传(windows主机到linux虚拟机)下载(linux虚拟机到windows主机)工具lrzsz,该工具使用前需要安装


首先进入/export/software/目录

首先输入rz
之后选择对应文件夹下的jdk
点击add 之后点击ok

输入ll查看当前目录下是否上传成功

也可以直接将文件拖进里面

7.3.3解压
tar -xzvf jdk-linux-x64.tar.gz -C /export/servers/

之后返回上一级,进入servers文件夹,查看解压后的文件

进入文件夹内查看文件结构

7.3.4配置环境变量
首先进入配置文件

之后在profile文件的最后加入一下内容

7.3.5使配置文件起作用

7.3.6 验证jdk是否配置成功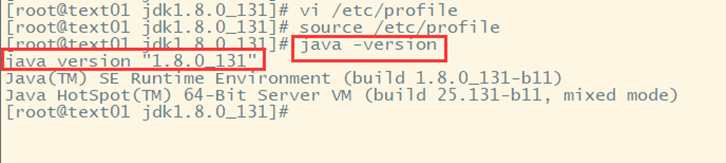
7.4 hadoop集群安装
7.4.1下载hadoop
百度hadoop下载,之后进入官网

点击download下载


这里选择3.1.4的版本


右击复制链接地址

第一种方式是使用wget命令进行下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.4/hadoop-3.1.4.tar.gz
wget命令如果没有找到,要先下载,下载命令:yum –y install wget
我们这里展示另一种方式,将其下载,之后上传
7.4.2上传安装包
首先进入/export/software文件夹下

如果先下载到本地主机,则需要上传到linux虚拟机中

查看上传情况

7.4.3解压
tar -xzvf hadoop-3.1.4.tar.gz -C /export/servers/

7.4.4配置环境变量

在文件最后输入以下内容

7.4.5使配置信息起作用
source /etc/profile

7.4.6验证hadoop配置是否成功
hadoop version

7.4.7常用命令说明



7.4.8hadoop集群配置
1)配置主节点
修改hadoop-env.sh文件

修改core-site.xml文件

修改hdfs-site.xml文件

修改mapred-site.xml

修改yarn-site.xml文件

修改workers文件

2)将集群主节点的配置文件分发到其他子节点text02和text03
分发jdk和hadoop
分发到text02主机
scp -r /export/servers/ text02:/export/

分发到text03主机
scp -r /export/servers/ text03:/export/

分发环境变量配置文件

使text02和text03的环境配置起作用


测试


7.4.9格式化集群文件系统
初次启动hadoop集群之前,需要对主节点进行格式化
hdfs namenode -format


说明格式化成功,此时的hadoop的存储目录结构

7.4.10启动hadoop集群
一键启动
1) jps查看java进程的命令



2) 启动hdfs
start-dfs.sh

需要修改hadoop-env.sh,添加root用户的启动权限

重新启动hadoop集群

查看是否启动成功



3)启动yarn

出现错误,需要root用户启动
修改hadoop-env.sh

重新启动yarn

查看是否启动成功
主节点text01上

其他节点上


7.4.11通过UI(图形界面查看Hadoop的运行状态
Hadoop集群启动后,默认开放了9870(3.0以上版本,老版本需要配置50070)和8088两个端口,9870(50070)用于监控hdfs,8088用于监控yarn,可以通过UI方便的进行管理和查看。在浏览器地址栏中输入:
http://主机名:9870
http://主机名:8088
注意:如果页面打不开,有两种可能的原因,一是windows主机没有配置ip和主机名的对应关系,另一种是端口后没有开发,需要关闭防火墙或者开发50070和8088两个端口

说明centos防火墙正在运行,此时有两种选择,一是直接关闭防火墙,二是开放9870(50070)和8088两个端口
Centos防火墙操作命令
查看防火墙状态

停止防火墙

刷新浏览器,可以查看

如果要通过端口50070进行访问,则需要修改配置文件



7.5集群测试
7.5.1Hdfs shell命令的使用

在UI下查看



注意:hadoop集群存储的最小块是128MB
7.5.2案例:Hadoop集群的计算使用 -------单词计数
做一个mapreduce的单词计算计算程序的案例

1)首先在文件夹下新建两个文件,内容如下

2)在hadoop集群根目录下创建input文件夹


3)将linux主机当前文件夹下的a.txt 和b.txt上传到集群input文件夹下

4)在hadoop集群上执行单词统计操作


注意:不要提前建立根目录下的output文件夹
启动命令,UI下的yarn状态查看

集群操作

5)提示错误信息

6)搜索解决方案

7)解决:
运行hadoop classpath

修改yarn-site.xml
 分发yarn-site.xml文件到其他主机
分发yarn-site.xml文件到其他主机

关闭yarn

重启yarn

8)重新运行单词计数

9)通过UI查看结果



10)通过shell命令查看结果

7.5.2案例:计算PI值

















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









